1.1.3.4. Node-AIの環境構築・学習モデルを作成・エクスポートする¶
本項では、Node-AIを使用して時系列予測の学習モデルを作成し、その学習モデルをWasabiオブジェクトストレージ(以下Wasabi)へエクスポートするまでの手順について記載します。
なお、本項中の設定値の「< >」の表記については、利用の環境により各自入力いただく箇所となります("<"から">"までを設定値に置き換えてください)。
前提条件を確認する¶
「1.1.2. 各種サービスを申し込む - Node-AIを申し込む」、および「1.1.2. 各種サービスを申し込む - Wasabiオブジェクトストレージを申し込む」に記載されている前提条件を参照いただき、Node-AIおよびWasabiが利用可能であることを確認ください。
アカウントを作成する¶
Node-AIを操作するアカウントを作成する手順です。
Node-AI ログインページにアクセスします。
注釈
- ログインページは、シングルテナント版の場合は払い出されたURL、マルチテナント版の場合は「Node-AI ログイン」となります。
利用規約をご確認の上、[ログイン/利用規約に同意して新規登録]をクリックします。

[アカウント新規登録]をクリックします。
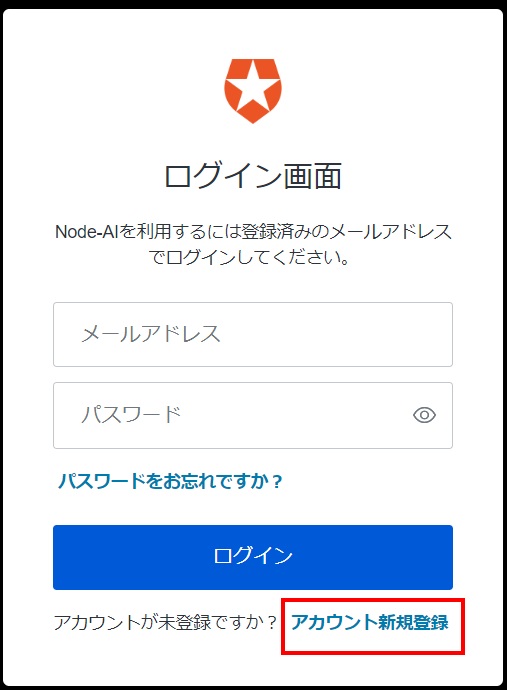
「メールアドレス」と「パスワード」を入力し[登録]をクリックします。
「確認メールを送信しました」の画面が表示されます。メールを確認します。

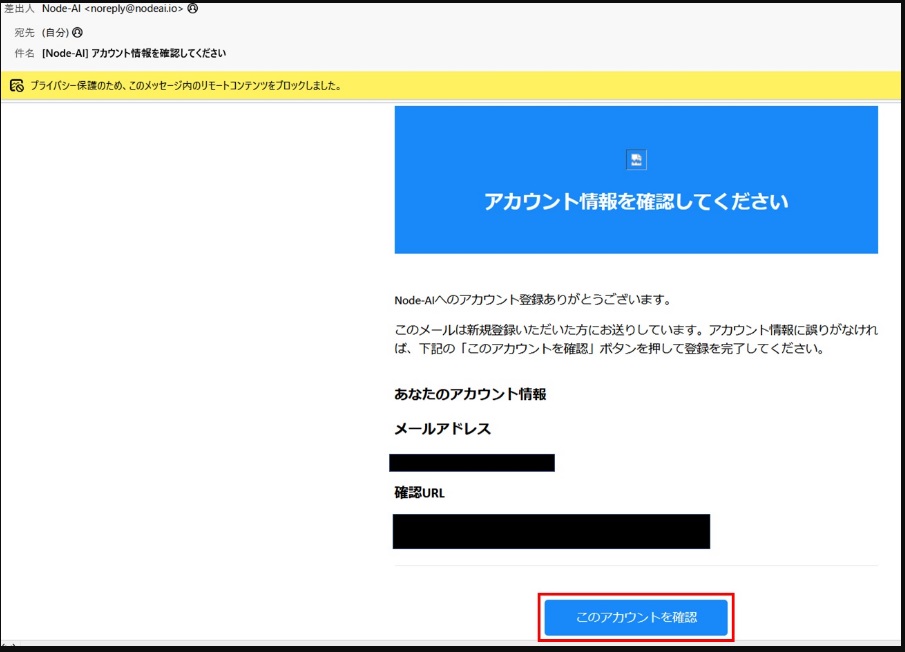
「[Node-AI] アカウント情報を確認してください」のメールを受信したら、[このアカウントを確認]をクリックします。
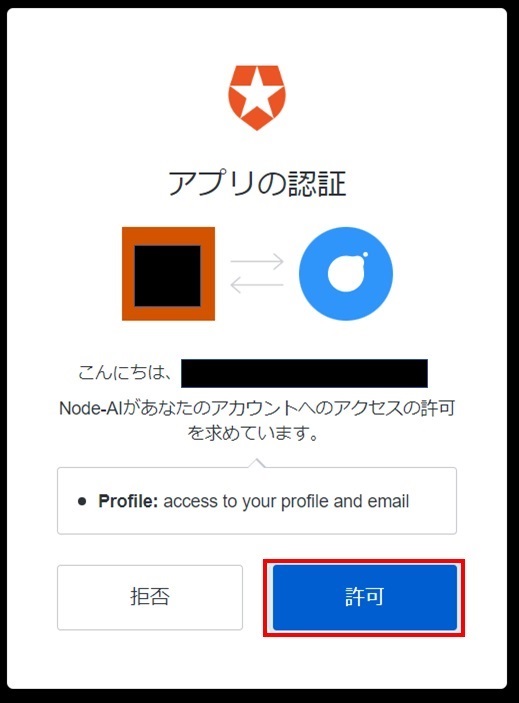
「アプリの認証」の画面が表示されます。[許可]をクリックします。
「個人用」のプロジェクト画面が表示されます。「チュートリアル用」のキャンバスやレシピが表示されています。 「プロジェクト」「キャンバス」などの用語については 「Node-AIマニュアル - 1.1.チーム・プロジェクト・キャンバスについて」を参照ください。
注釈
- Node-AIマニュアルは こちら から確認いただけます。
チーム、プロジェクト、キャンバスを作成する¶
画面左上のチームタブ(初期では[個人用]と表示)をクリックし、[+ チームの新規作成]をクリックします。
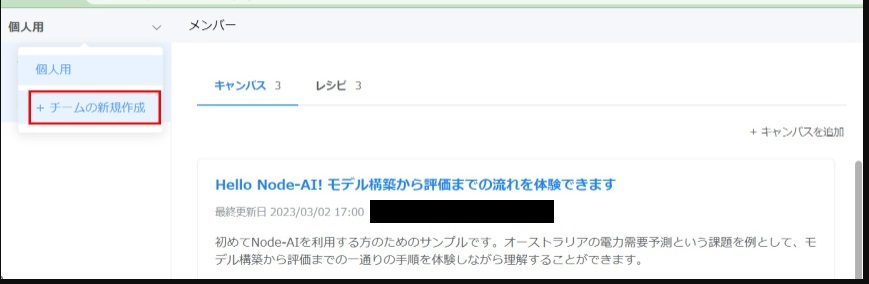
「チーム名(例:Node-AI検証)」、必要に応じて「概要」を入力し、[チーム作成]をクリックします。
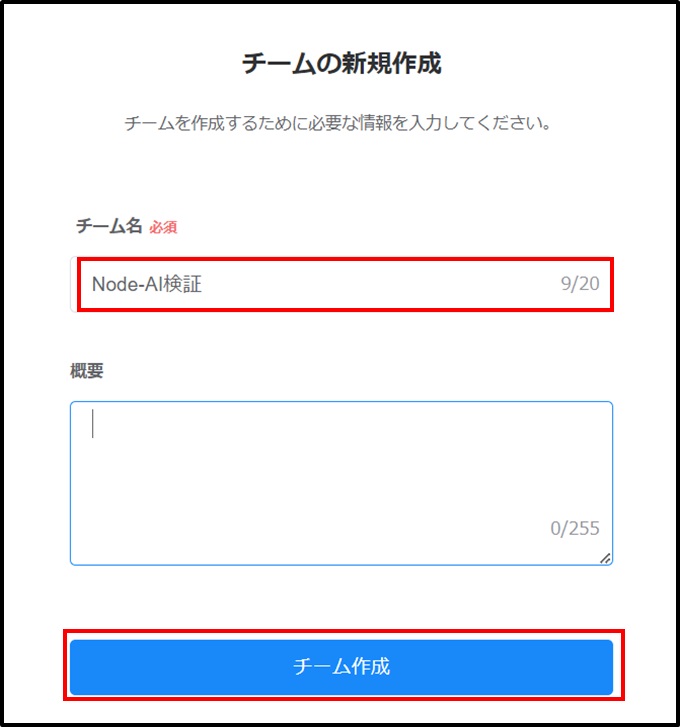
画面左上にチーム名が表示された画面に遷移します。[プロジェクトを作成する]をクリックします。
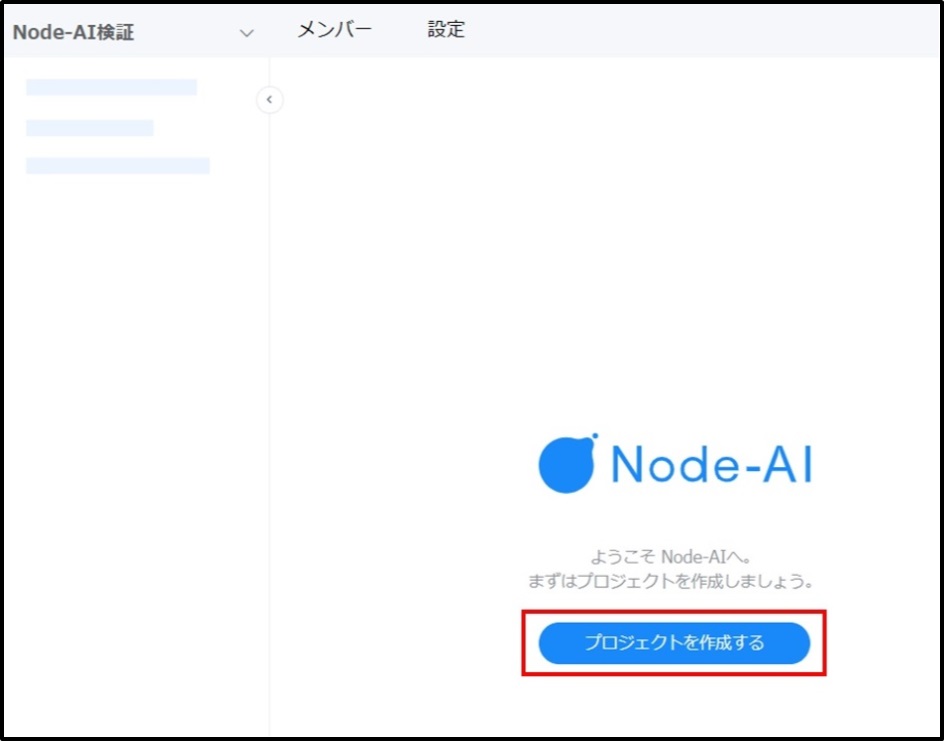
「プロジェクト名(例:学習モデル作成)」、必要に応じて「概要」を入力し、[作成]をクリックします。
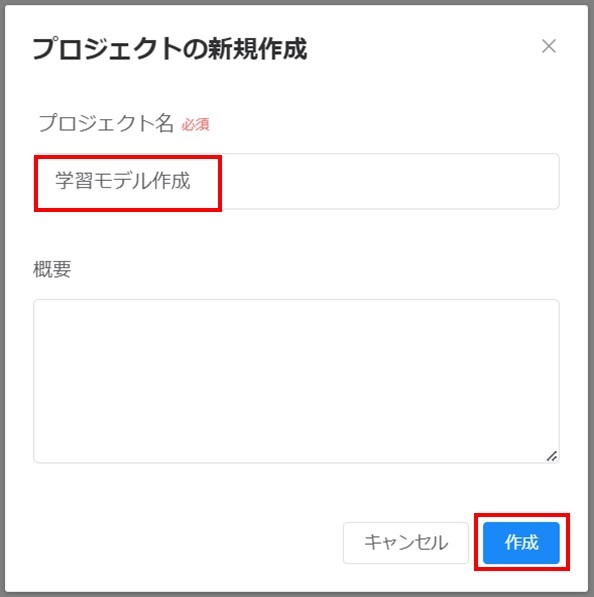
チーム名の下にプロジェクト名が表示された画面に遷移します。[キャンバスを作成する]をクリックします。
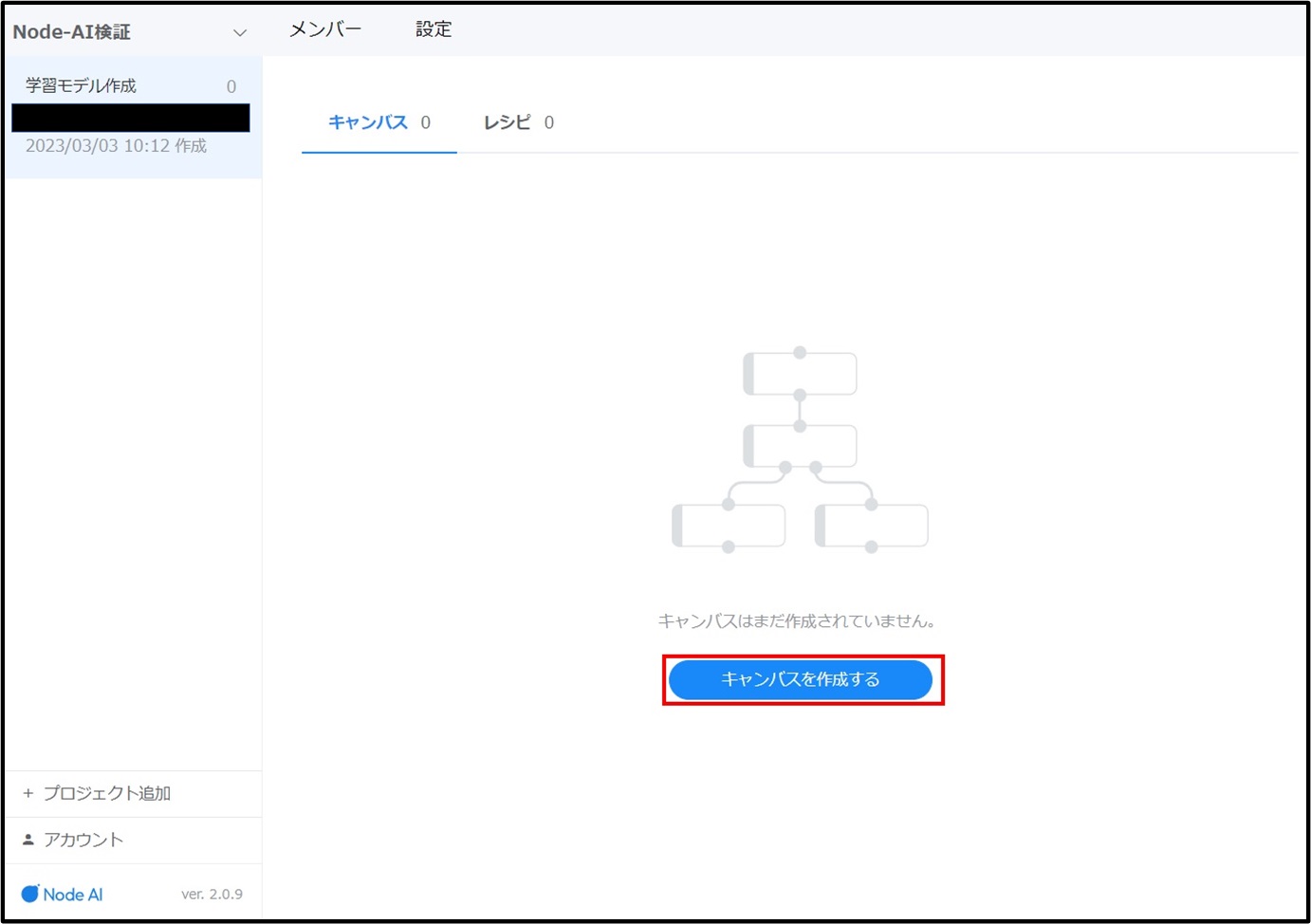
「キャンバス名(例:通過人数予測)」、必要に応じて「概要」を入力し、[作成]をクリックします。
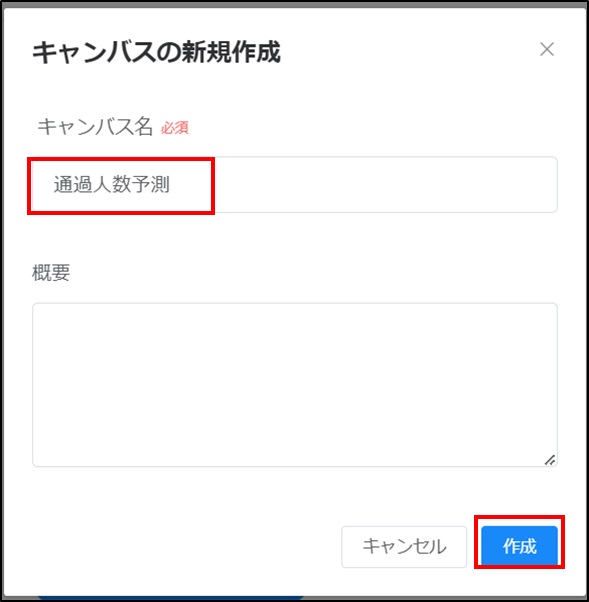
キャンバスのリスト画面に遷移します。[キャンバス名(例:通過人数予測)]をクリックすると、クリックしたキャンバスの画面に遷移します。

学習データをインポートする¶
Node-AIでは、学習データをローカルファイル、AWS S3、Azure Blob、Wasabi、公開データからインポートできます。
本項では例として、Wasabiから学習データをインポートする方法を記載します。
あらかじめ、学習データはWasabiに保存してください。
注釈
本構成ガイドでは例として「通過人数(201608-202003+202204-202208).csv」という学習データを用いて手順を記載しています。
この学習データは、「ある特定の場所を通過する人数」を1分単位で6年間(コロナ禍除く)計測したものに、関連データを付加したものです。
[ファイル]アイコン>[Wasabi]をクリックします。

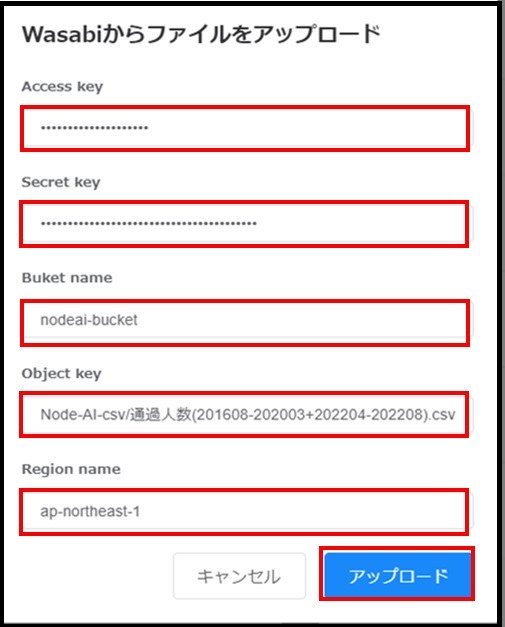
「Wasabiからファイルをアップロード」画面にてWasabiのパラメーターを入力し、[アップロード]をクリックします。
項目
値
備考
Access key
<Node-AI用Wasabiユーザーの「アクセスキー」>
「 1.1.3.1. Wasabiオブジェクトストレージを設定する - Node-AI用ユーザーを作成する 」で取得した「アクセスキー」を入力してください。
Secret key
<Node-AI用Wasabiユーザーの「秘密鍵」>
「 1.1.3.1. Wasabiオブジェクトストレージを設定する - Node-AI用ユーザーを作成する 」で取得した「秘密鍵」を入力してください。
Bucket name
<学習データを保管するバケットの名前(例:nodeai-bucket)>
「 1.1.3.1. Wasabiオブジェクトストレージを設定する - バケットを作成する 」で作成したバケット名を入力してください。
Object key
<バケット内のファイルパス(例:Node-AI-csv/通過人数(201608-202003+202204-202208).csv)>
インポートする学習データが保存されたバケット内のファイルパスを入力してください。
Region name
<バケットのリージョン(例:ap-northeast-1)>
「 1.1.3.1. Wasabiオブジェクトストレージを設定する - バケットを作成する 」で指定したリージョンを入力してください。
自動的に変換処理が行われるので、終わるまで待機します。
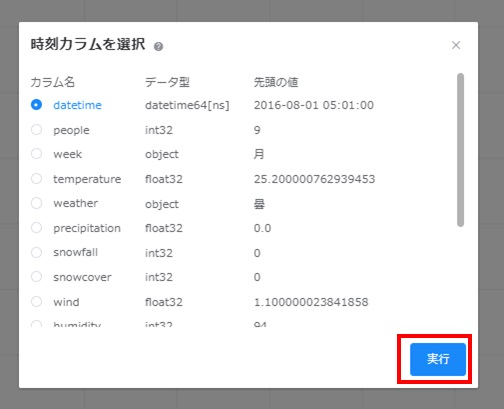
学習データ中の「時刻(データ型:datetime64[ns])」が含まれたカラムを選択し、[実行]をクリックします。
アップロードが終わるまで待機します。
アップロードした学習データが「データ」タブに配置されることを確認します(「データカード」と呼びます)。
目的変数と説明変数を設定する¶
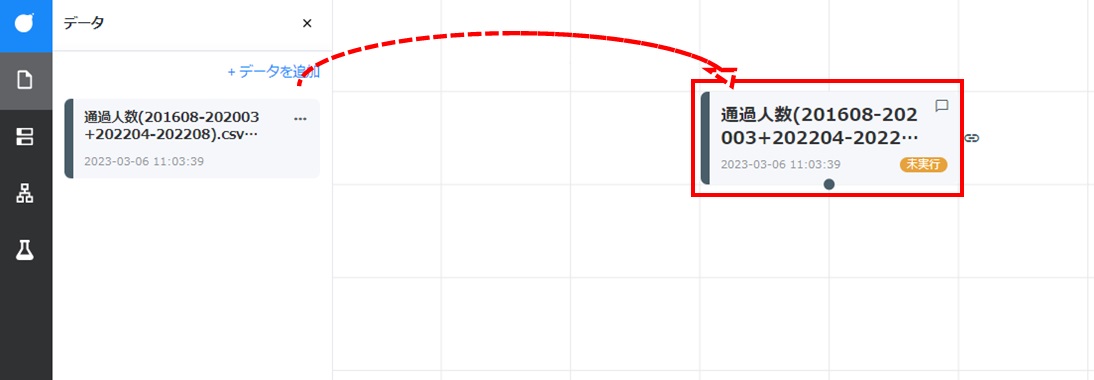
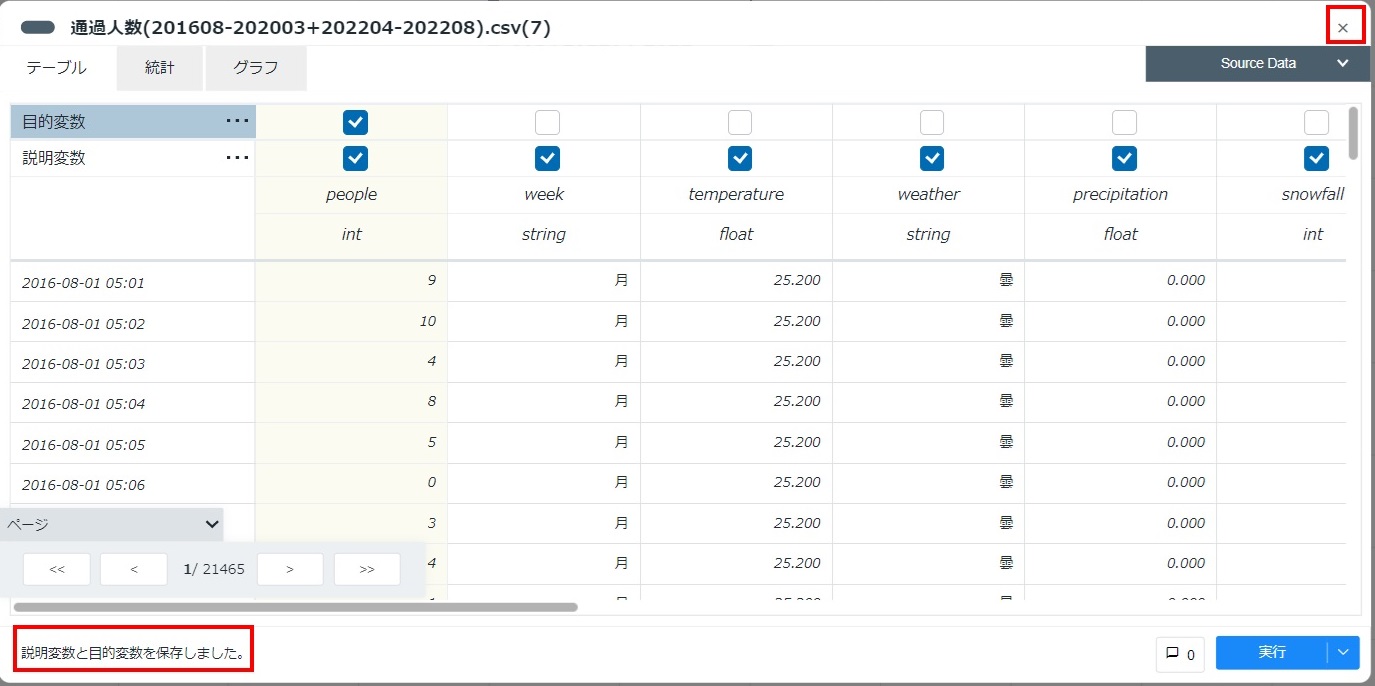
データカードをキャンバスにドラッグアンドドロップして配置します。
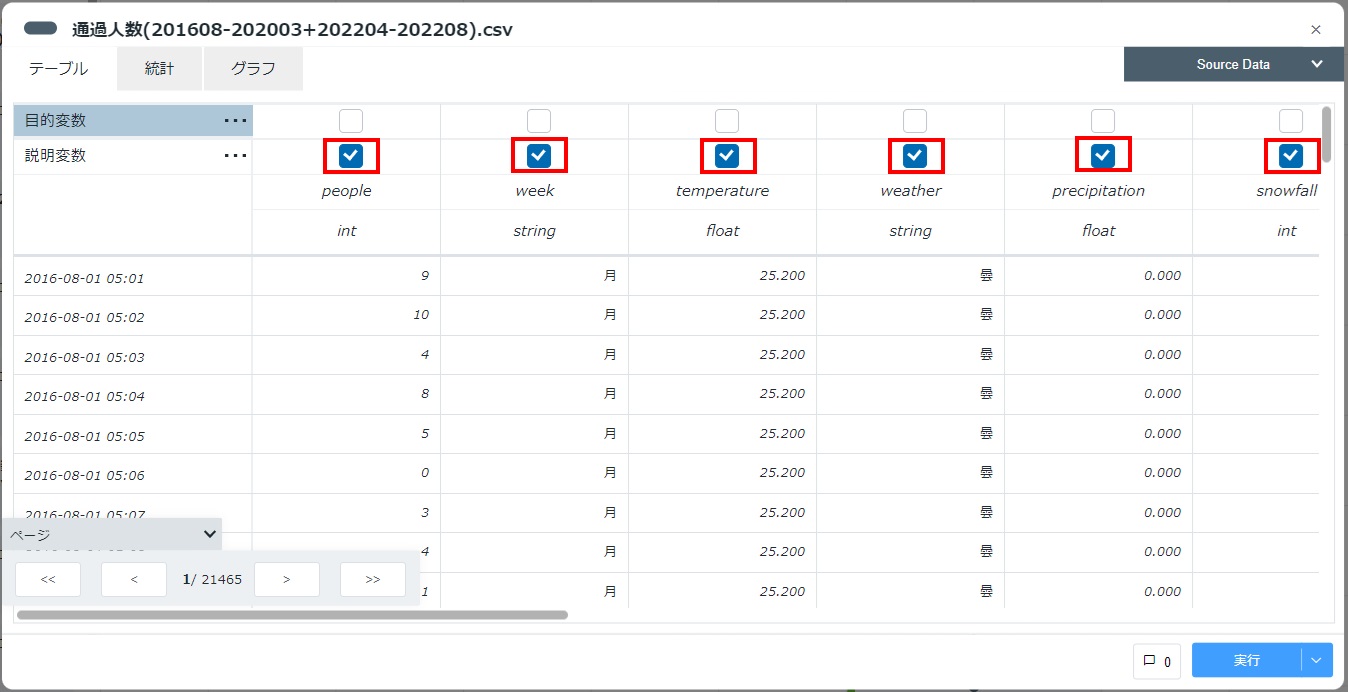
配置したデータカードをダブルクリックして変数一覧を表示し、説明変数として利用するカラム(本構成ガイドでは「people」、「week」、「temperature」など)を指定します。
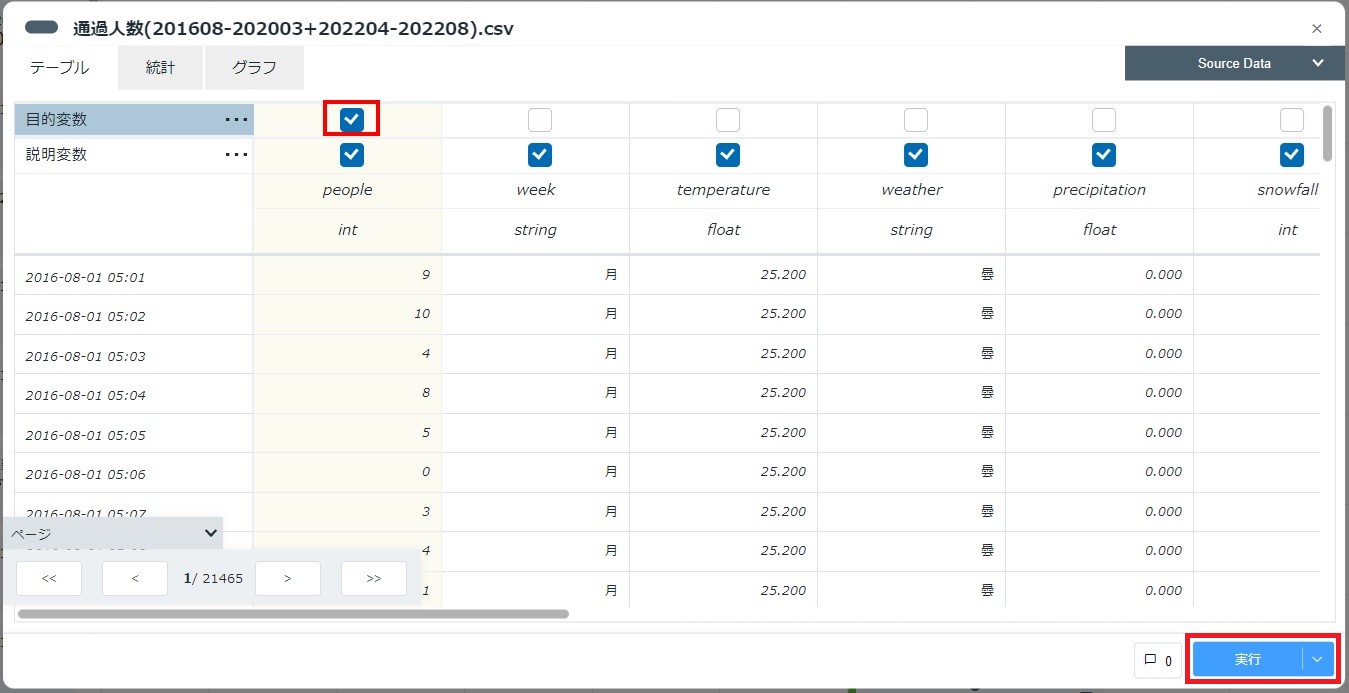
同様に、目的変数として利用するカラム(本構成ガイドでは「people」)を指定し、[実行]をクリックします。
画面左下に「説明変数と目的変数を保存しました。」というメッセージが表示されることを確認し、画面右上の[×]をクリックしてカードを閉じます。
データの前処理を行う¶
学習モデルの作成が適切に行えるよう、インポートした学習データに対して前処理を行う必要があります。
本項では、データの前処理を行うカードの設定手順を記載します。
注釈
- 現在、カスタム前処理カードはシングルテナント版またはマルチテナント版の有料プランのみの機能になっております(2023年4月時点)。
カスタム前処理カード(イベントの前日にフラグを立てる)を設定する¶
カスタム前処理カードは必要に応じて配置・設定します。
本項では、「イベントの前日にフラグを立てる」という前処理を行うカードを例として記載しています。
カード・設定パラメーターの詳細は「Node-AIマニュアル - 1.10.カスタム前処理」を参照ください。
カスタム前処理カードをドラッグしてデータカードの下に配置し、データカードのコネクタからドラッグしてカスタム前処理カードのコネクタに結線します。
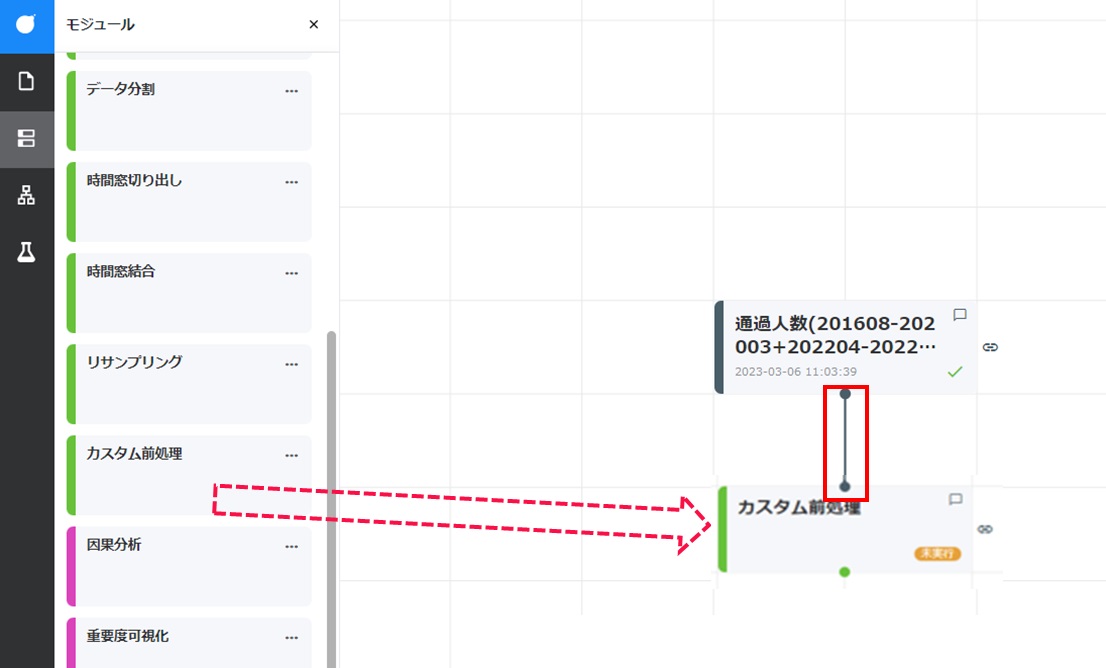
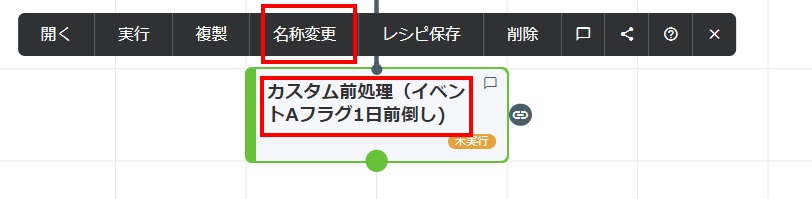
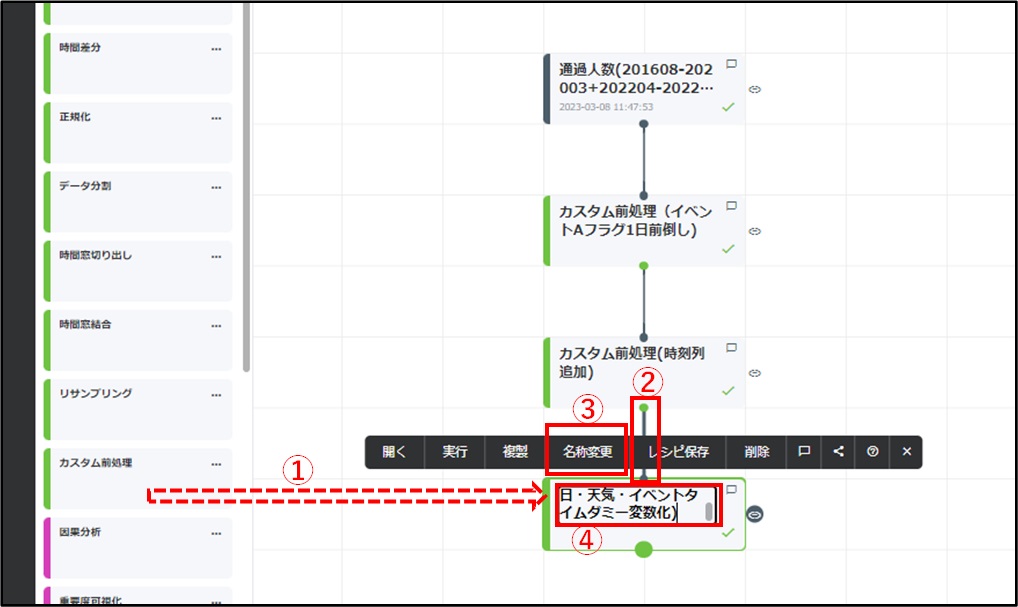
カードをクリックし、[名称変更]をクリックすることでカードの表示名を変更できます。ここでは「カスタム前処理(イベントAフラグ1日前倒し)」と変更しています。
配置したカスタム前処理カードをダブルクリックして開き、[コード]タブをクリックします。コードが初期状態(3行)であることを確認します。

コード部分を以下の内容に書き換え、[実行]をクリックします。
from datetime import timedelta def nodeai_main(df): # イベントタイム情報にイベントAがあるdatetimeを取り出しindex配列を作る hanabi_evt_index = df[df['eventtime'] == "イベントA"].index # いったんeventtime列をすべて"なし”に書き換える。(SKIP) df_edit=df df_edit.loc['2016-08-01 05:00:00':'2022-09-01 00:29:00', 'eventtime'] = 'なし' # index配列のdatetimeの1日前の時刻をindexとし、その行のeventtimeに'イベントA'を書き込む for i in range(len(hanabi_evt_index)): dt = hanabi_evt_index[i] dt2 = dt-timedelta(days=1) df_edit.loc[ dt2 , 'eventtime' ] = 'イベントA' df = df_edit return df

カードの左下に「カスタム前処理の実行が完了しました。」と表示されることを確認し、画面右上の[×]をクリックしてカードを閉じます。

カスタム前処理カード(カラム「時刻」を追加する)を設定する¶
本項では、「学習データにカラム『時刻』を追加する」という前処理を行うカードを例として記載しています。
- 以下の順でカードの配置、接続、名称変更をします。① 新たなカスタム前処理カードをドラッグして「カスタム前処理(イベントAフラグ1日前倒し)」カードの下に配置します。② 「カスタム前処理(イベントAフラグ1日前倒し)」カードのコネクタからドラッグして、新たに配置したカスタム前処理カードのコネクタに結線します。③ 配置したカスタム前処理カードをクリックして表示されるメニューから[名称変更]をクリックします。④ カードの名称を「カスタム前処理(時刻列追加)」にします。
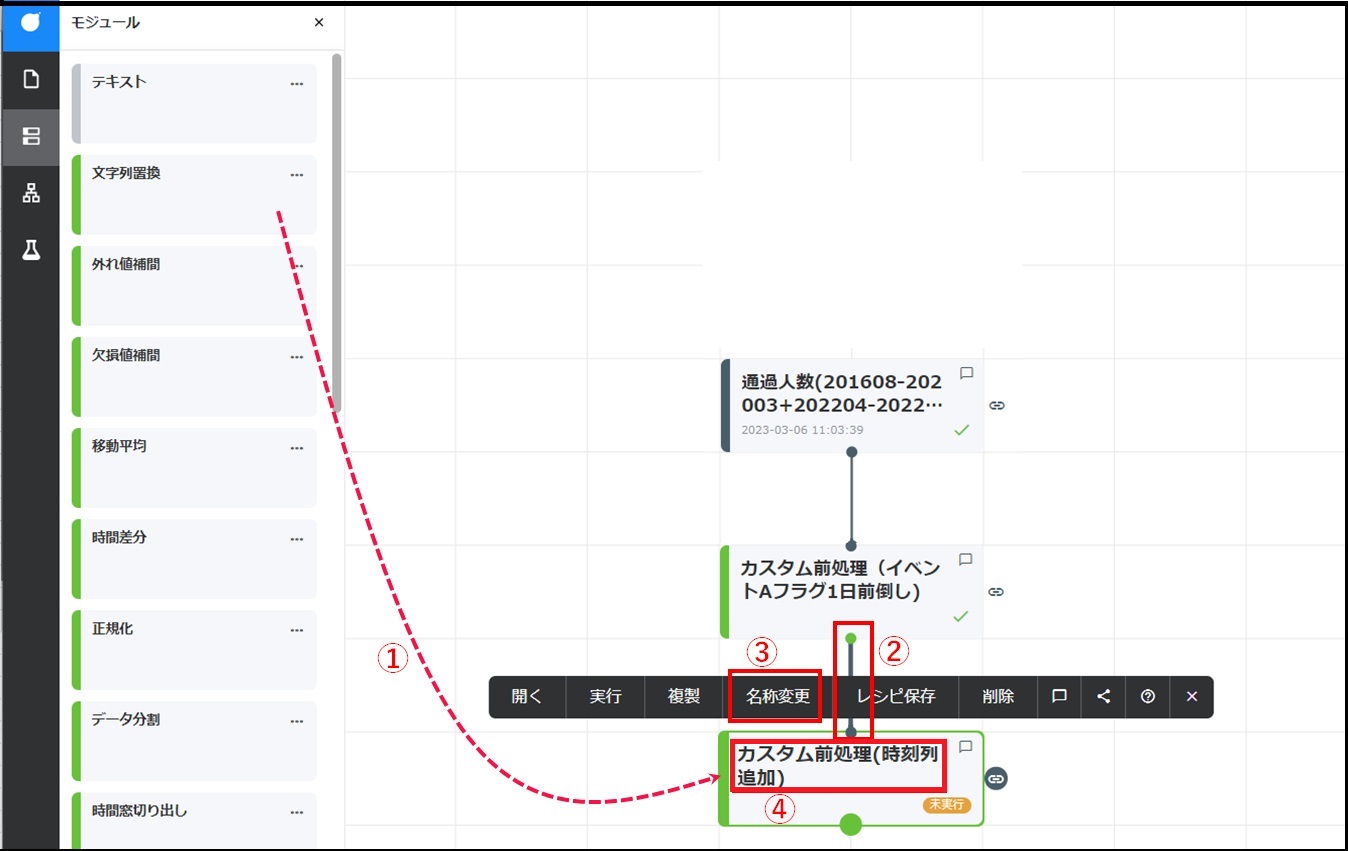
配置したカスタム前処理カードをダブルクリックして開き、[コード]タブをクリックします。コードが初期状態(3行)であることを確認します。
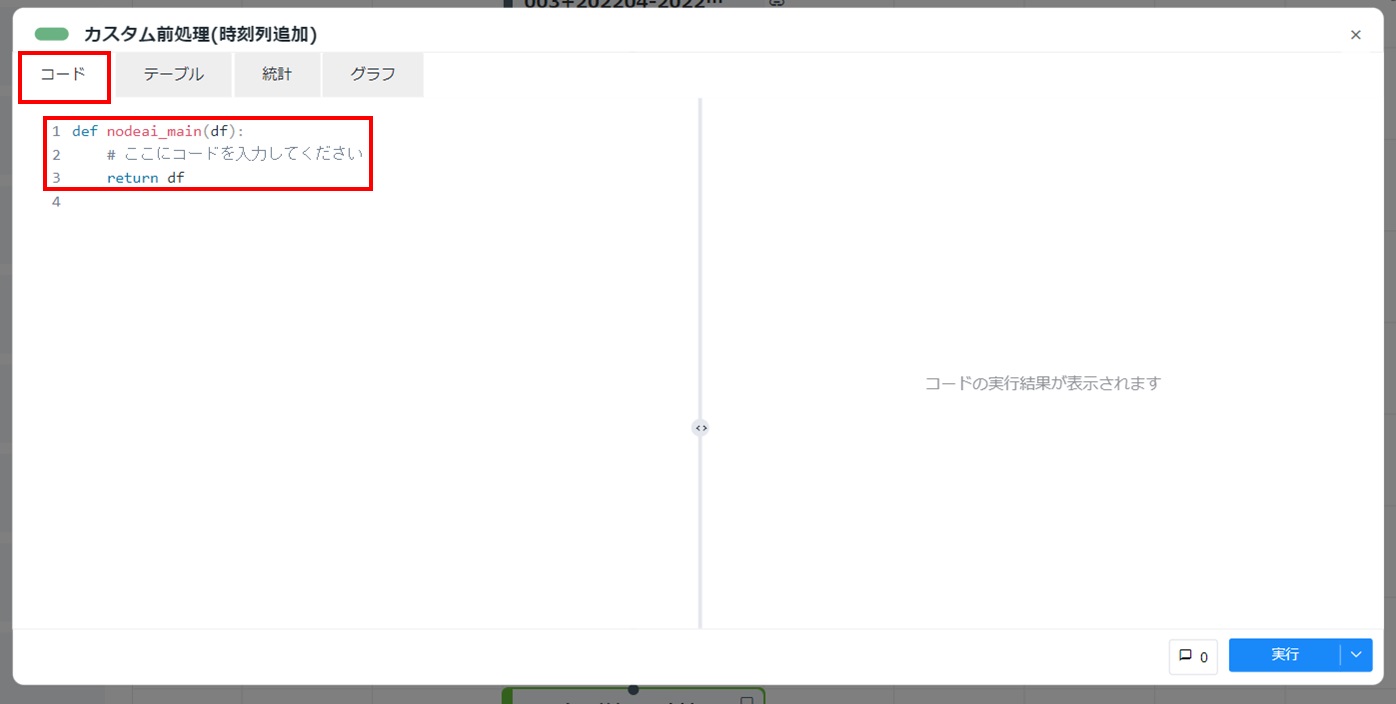
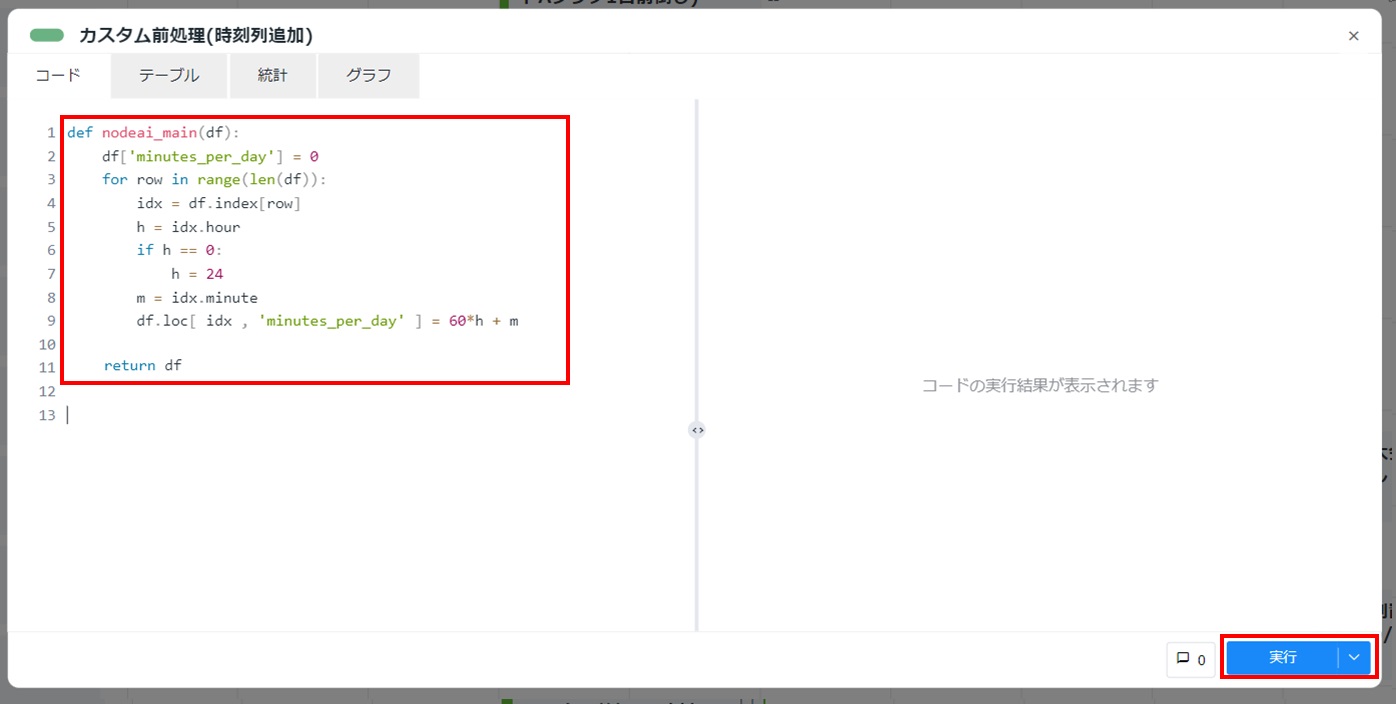
コード部分を以下の内容に書き換え、[実行]をクリックします。
def nodeai_main(df): df['minutes_per_day'] = 0 for row in range(len(df)): idx = df.index[row] h = idx.hour if h == 0: h = 24 m = index.minute df.loc[ idx , 'minutes_per_day' ] = 60*h + m return df
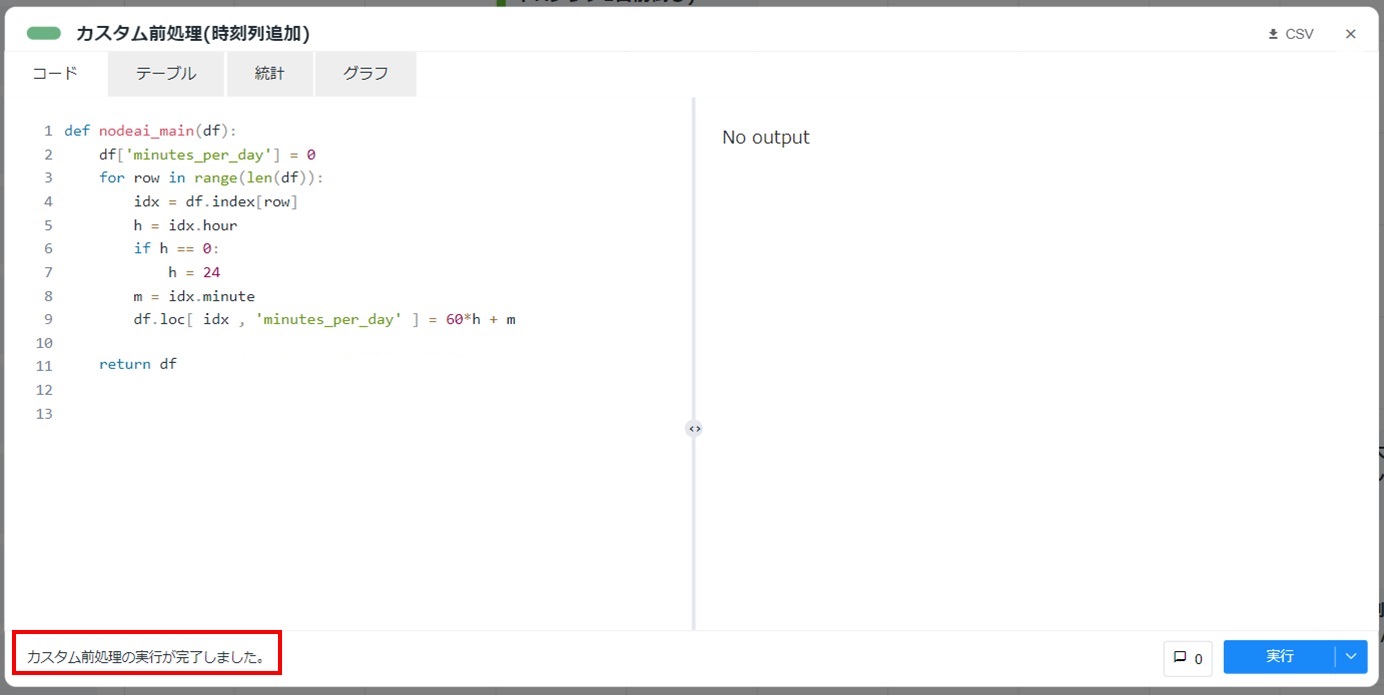
カードの左下に「カスタム前処理が完了しました。」と表示されることを確認します。
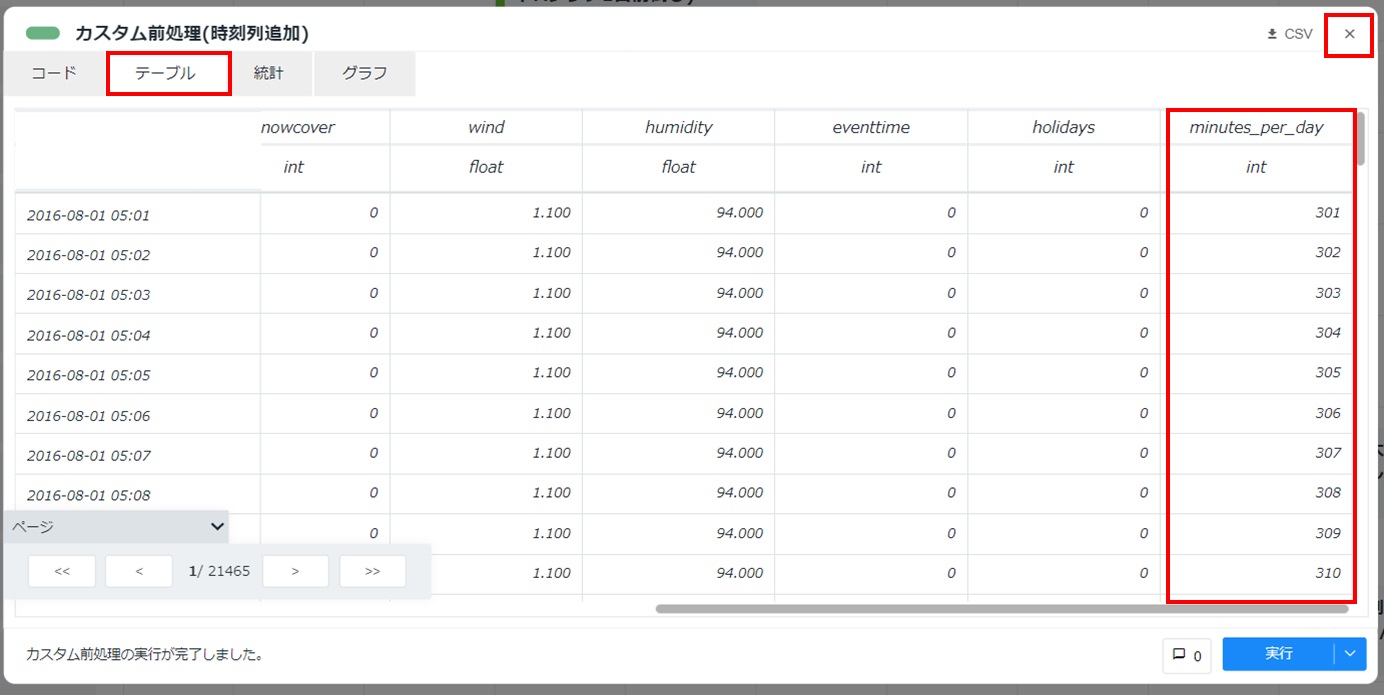
[テーブル]タブを選択し、「minutes_per_day」列が追加されていることを確認します。カード右上の[×]をクリックしてカードを閉じます。
カスタム前処理カード(ダミー変数化)を設定する¶
本項では、「学習データの特定のカラムをダミー変数に変換する」という前処理を行うカードを例として記載しています。
- 以下の順でカードの配置、接続、名称変更をします。① 新たなカスタム前処理カードをドラッグして「カスタム前処理(時刻列追加)」カードの下に配置します。② 「カスタム前処理(時刻列追加)」カードのコネクタからドラッグして、新たに配置したカスタム前処理カードのコネクタに結線します。③ 配置したカスタム前処理カードをクリックして表示されるメニューから[名称変更]をクリックします。④ カードの名称を「カスタム前処理(曜日・天気・イベントタイムダミー変数化)」にします。
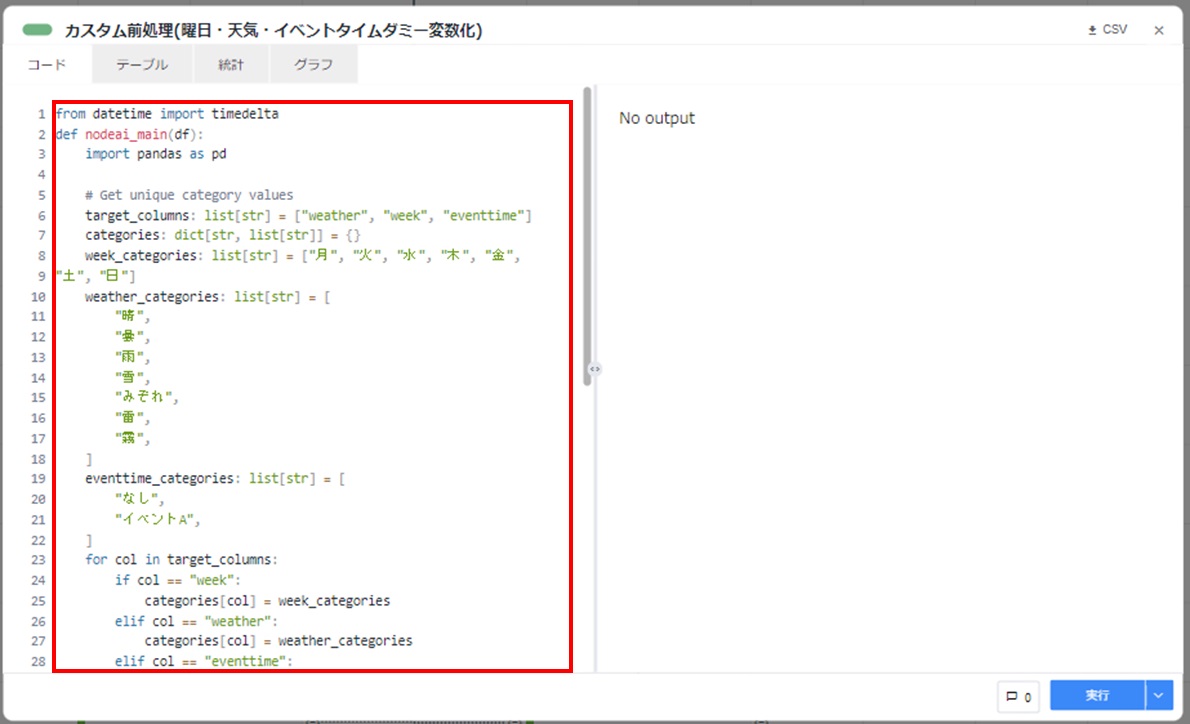
配置したカスタム前処理カードをダブルクリックして開き、[コード]タブをクリックします。コードが初期状態(3行)であることを確認します。
コード部分を以下の内容に書き換え、[実行]をクリックします。
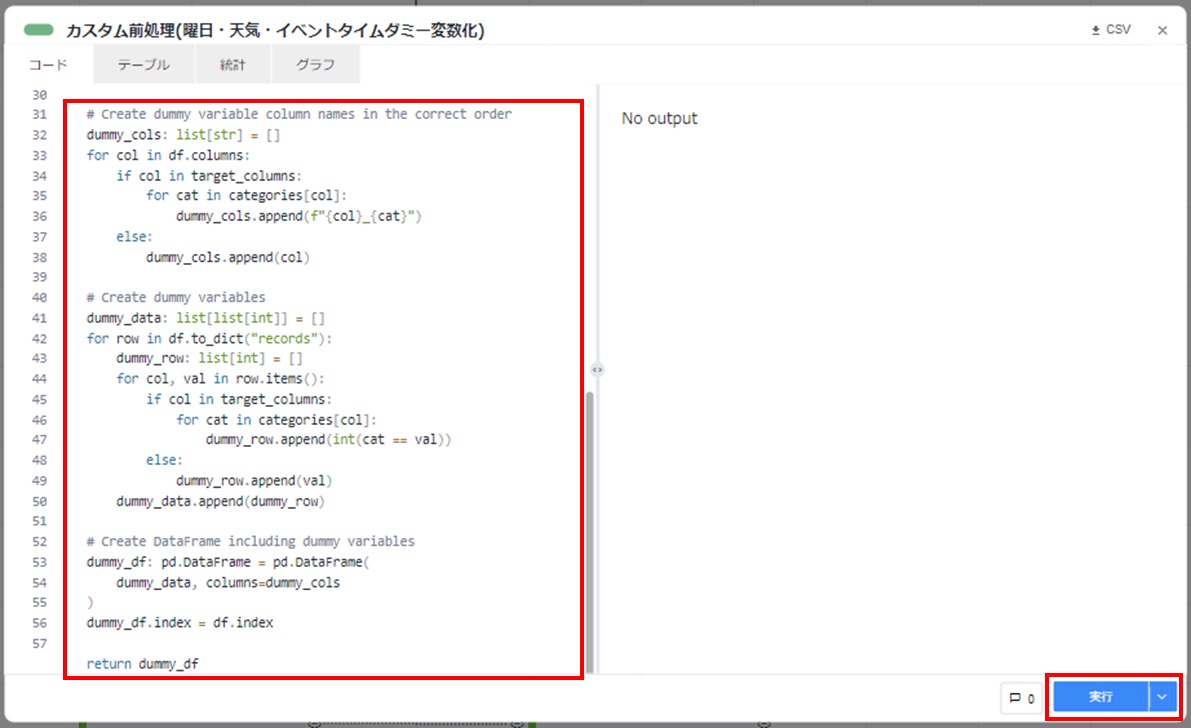
from datetime import timedelta def nodeai_main(df): import pandas as pd # Get unique category values target_columns: list[str] = ["weather", "week", "eventtime"] categories: dict[str, list[str]] = {} week_categories: list[str] = ["月", "火", "水", "木", "金", "土", "日"] weather_categories: list[str] = [ "晴", "曇", "雨", "雪", "みぞれ", "雷", "霧", ] eventtime_categories: list[str] = [ "なし", "イベントA", ] for col in target_columns: if col == "week": categories[col] = week_categories elif col == "weather": categories[col] = weather_categories elif col == "eventtime": categories[col] = eventtime_categories # Create dummy variable column names in the correct order dummy_cols: list[str] = [] for col in df.columns: if col in target_columns: for cat in categories[col]: dummy_cols.append(f"{col}_{cat}") else: dummy_cols.append(col) # Create dummy variables dummy_data: list[list[int]] = [] for row in df.to_dict("records"): dummy_row: list[int] = [] for col, val in row.items(): if col in target_columns: for cat in categories[col]: dummy_row.append(int(cat == val)) else: dummy_row.append(val) dummy_data.append(dummy_row) # Create DataFrame including dummy variables dummy_df: pd.DataFrame = pd.DataFrame( dummy_data, columns=dummy_cols ) dummy_df.index = df.index return dummy_df
カードの左下に「カスタム前処理が完了しました。」と表示されることを確認します。
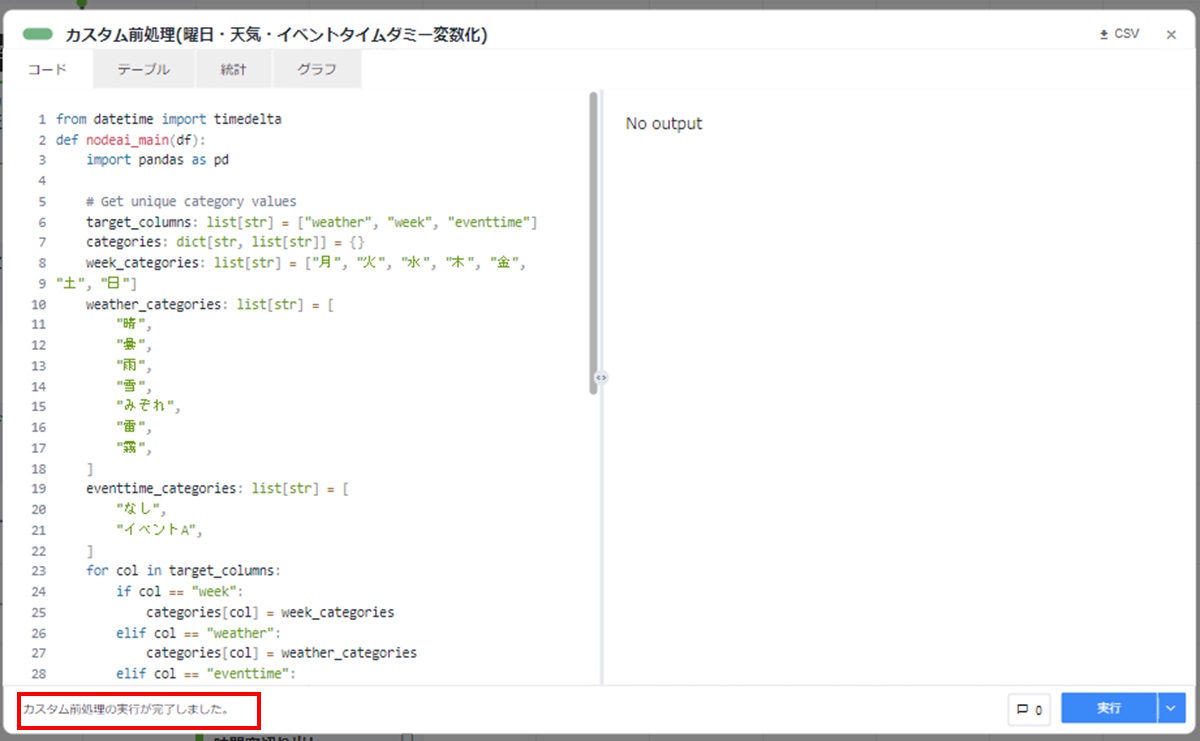
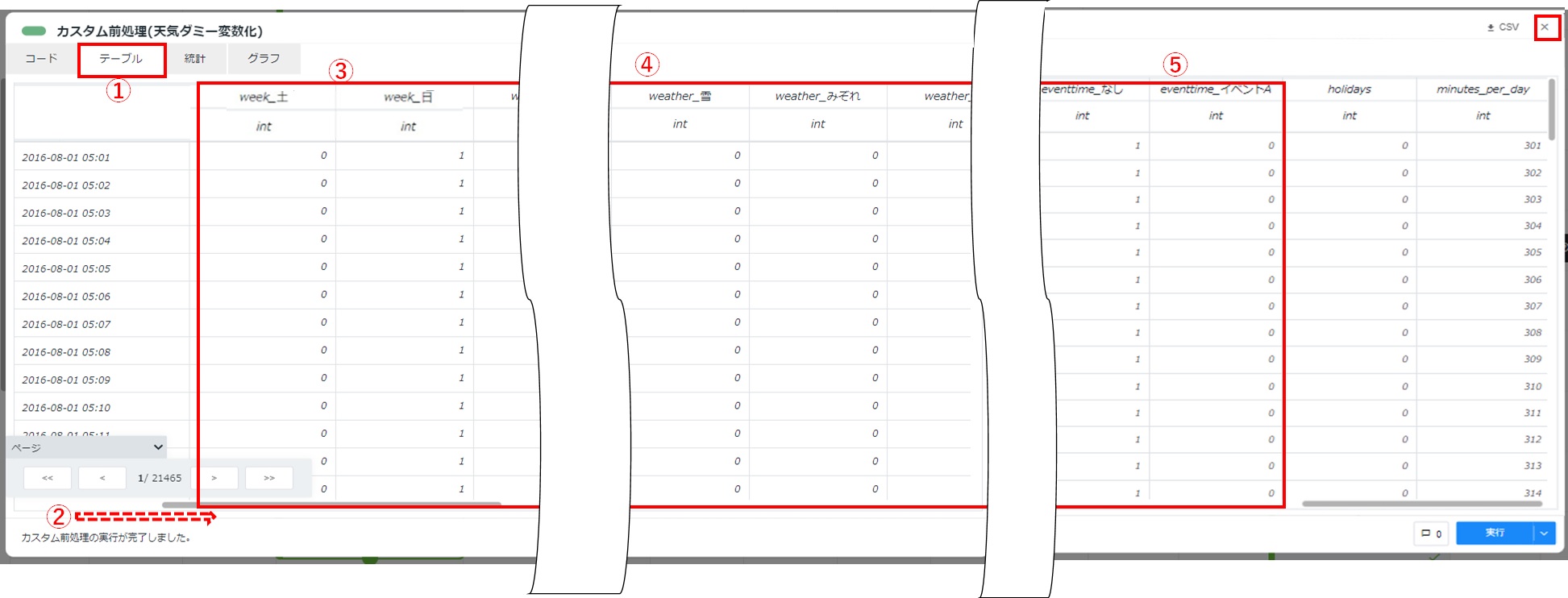
- 以下の順でカスタム前処理結果を確認します。確認後、カード右上の[×]をクリックしてカードを閉じます。① [テーブル]タブを選択します。② 表示されていない列は、テーブル表示欄下の横スクロールバーを使用します。③ 「week_"曜日”」列が追加されていることを確認します。④ 「weather_”天気"」列が追加されていることを確認します。⑤ 「eventtime_イベントA」列が追加されていることを確認します。
欠損値補間カードを設定する¶
学習データに欠損値が含まれている場合には、欠損値補間カードを用いデータを補間します。
カード・設定パラメーターの詳細は「Node-AIマニュアル - 1.3.欠損値補間」を参照ください。
欠損値補間カードをドラッグして「カスタム前処理(曜日・天気・イベントタイムダミー変数化)」カードの下に配置します。「カスタム前処理(曜日・天気・イベントタイムダミー変数化)」カードのコネクタからドラッグして、新たに配置した欠損値補間カードのコネクタに結線します。

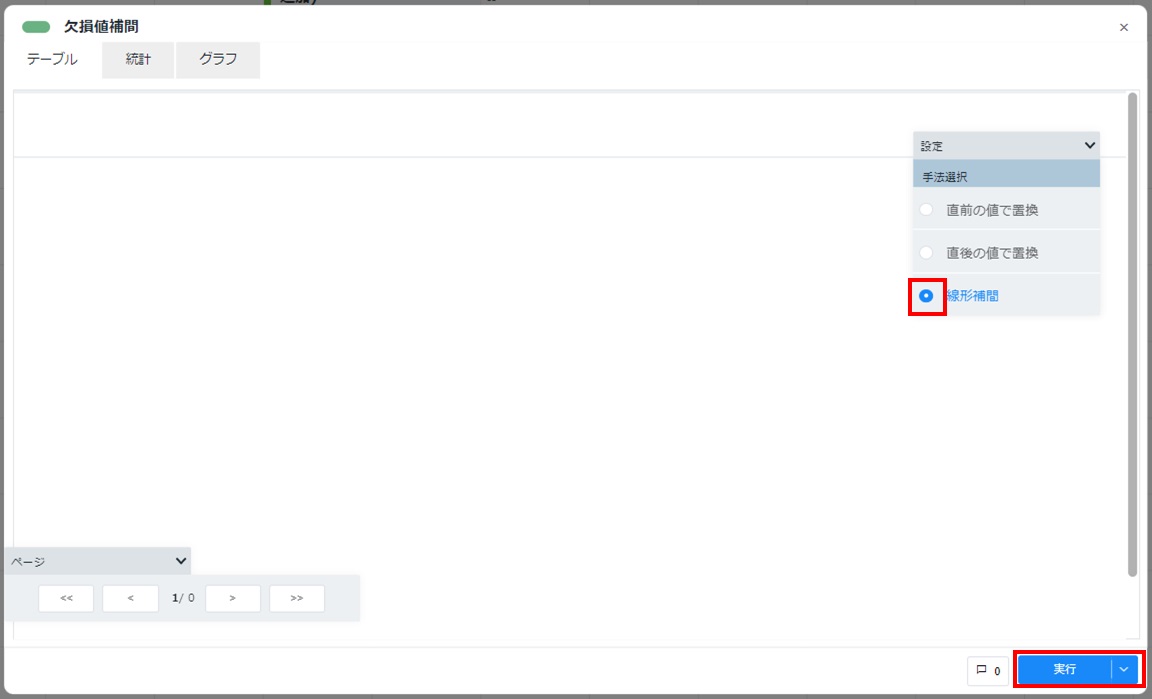
配置した欠損値補間カードをダブルクリックして開き、[設定]をクリックし[線形補間]を選択し、[実行]をクリックします。
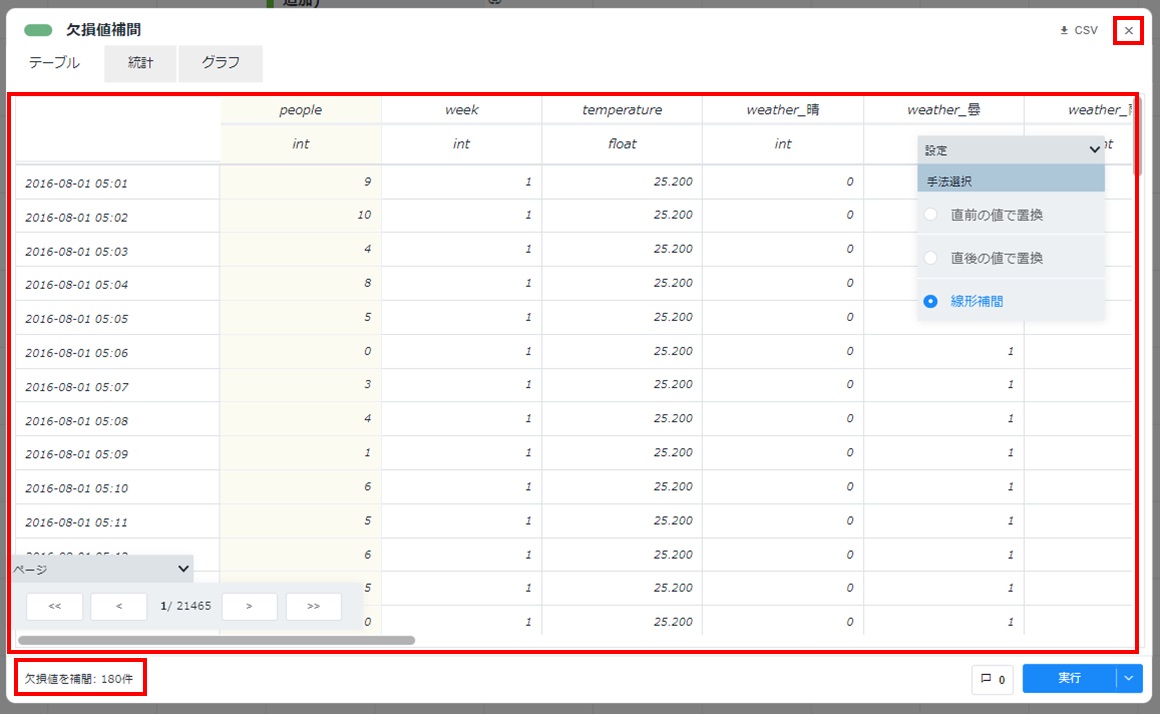
カードの左下に「欠損値を補間:XXX件」と表示され、テーブルが表示されることを確認します。カードの右上の[×]をクリックしてカードを閉じます。
データ分割カードを設定する¶
データ分割カードを用い、入力データを学習データとテストデータに分割します。
カード・設定パラメーターの詳細は「Node-AIマニュアル - 3.1.データ分割」を参照ください。
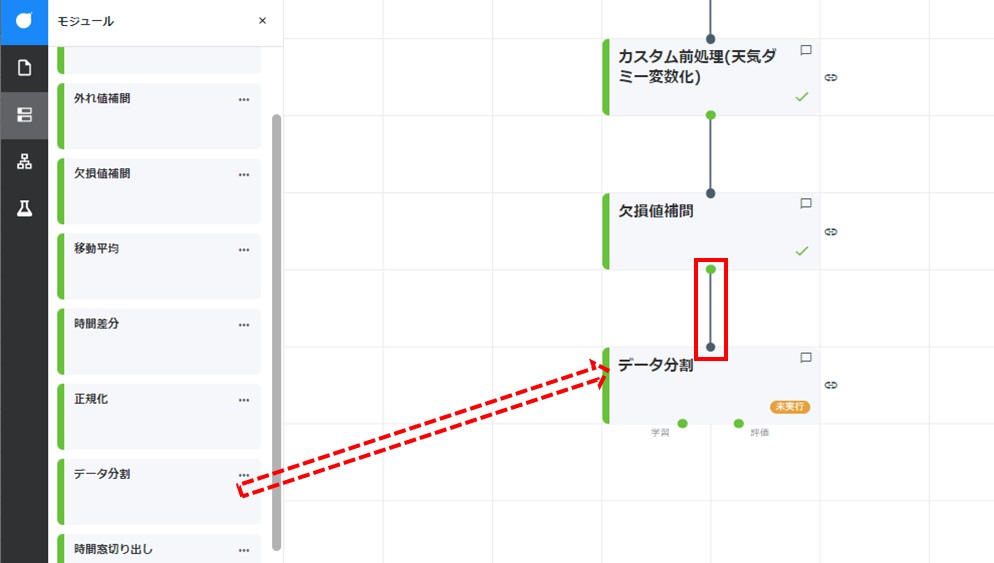
データ分割カードをドラッグして「欠損値補間」カードの下に配置します。「欠損値補間」カードのコネクタからドラッグして、新たに配置したデータ分割カードのコネクタに結線します。
配置したデータ分割カードをダブルクリックして開き、[設定]をクリックし入力データの時間範囲が表示されていることを確認します。
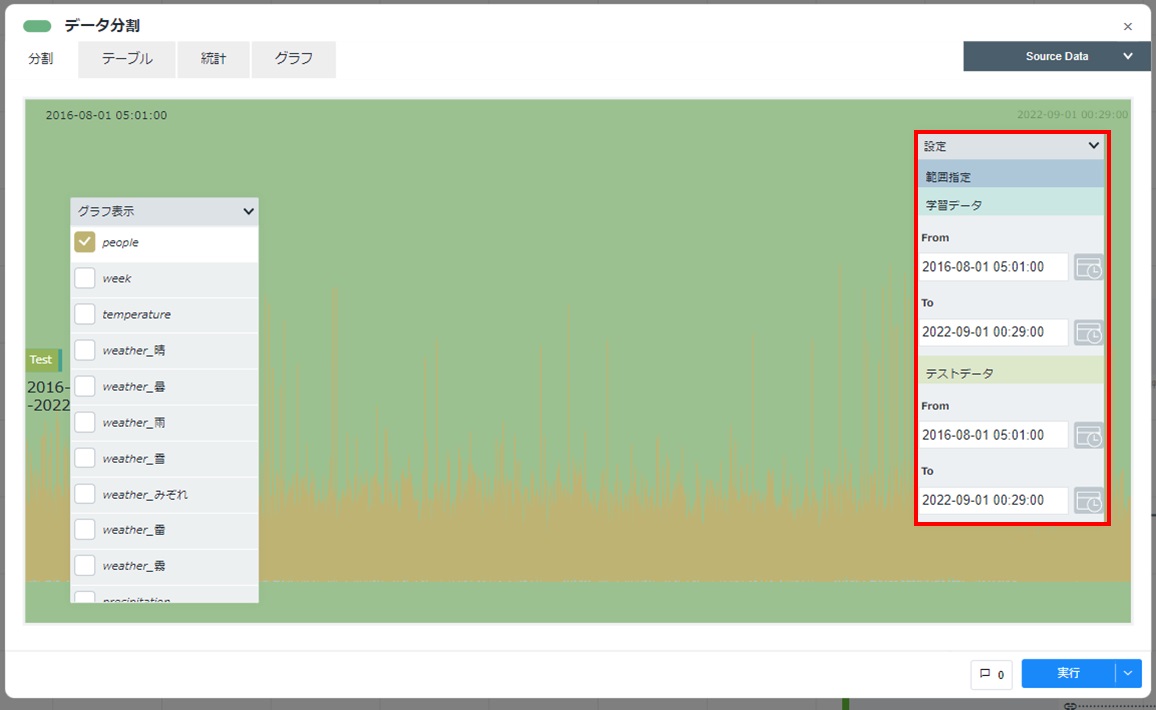
学習データとテストデータに分けるため、設定欄の「学習データ」の”To”と「テストデータ」の”From”の値を編集して時間範囲を指定し、[実行]をクリックします。
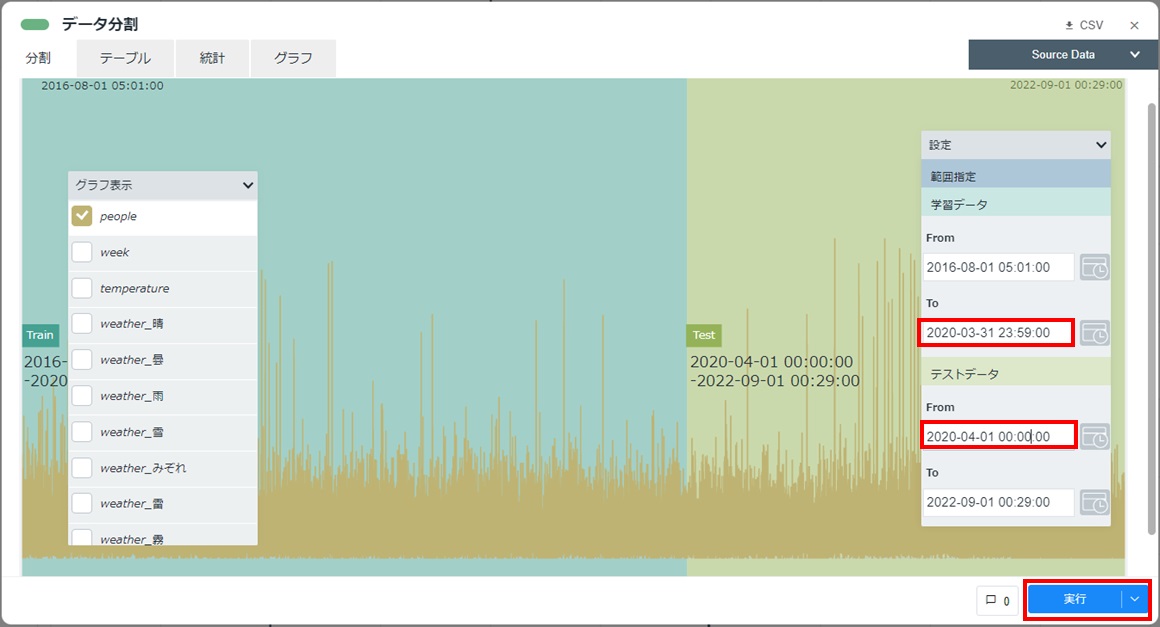
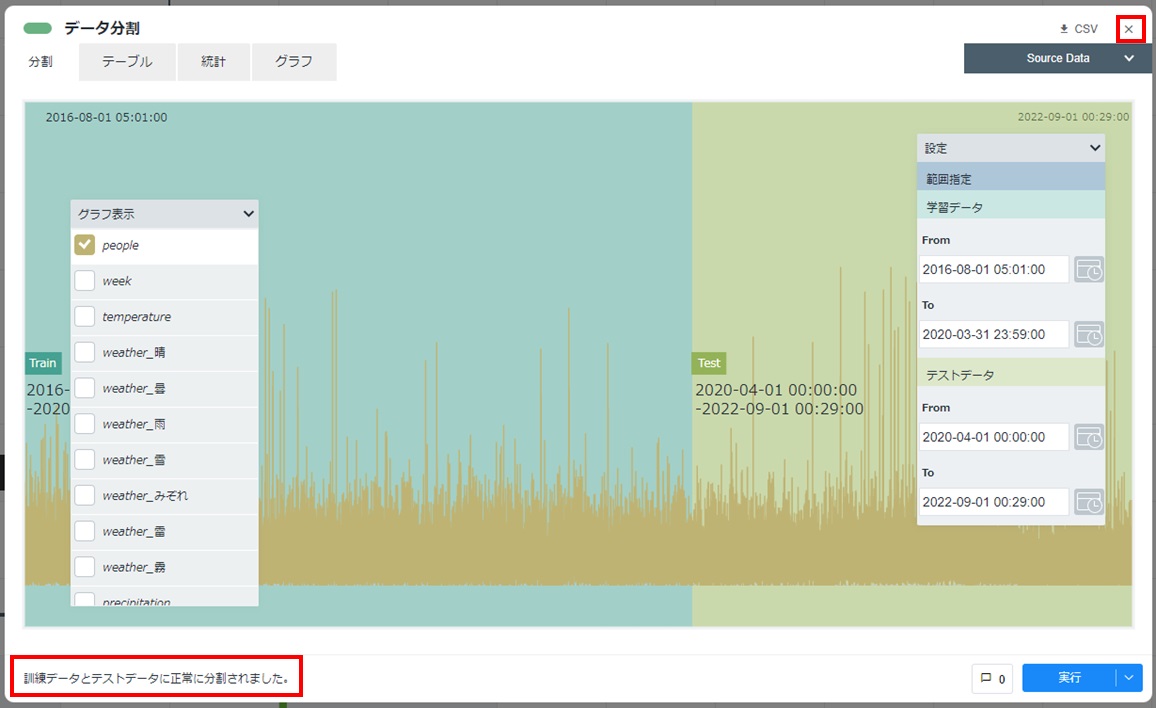
カードの左下に「訓練データとテストデータに正常に分割されました」と表示されることを確認します。カード右上の[×]をクリックしてカードを閉じます。
正規化カード(学習データ用)を設定する¶
正規化カードを用い、データを正規化します。
学習データにおいて、カラムごとに平均や標準偏差が異なるときに実施すると精度の良い結果が得られる場合があります。
カード・設定パラメーターの詳細は「Node-AIマニュアル - 1.6.正規化」を参照ください。
正規化カードをドラッグして「データ分割」カードの左下に配置します。「データ分割」カードの「学習」コネクタからドラッグして、新たに配置した正規化カードのコネクタに結線します。
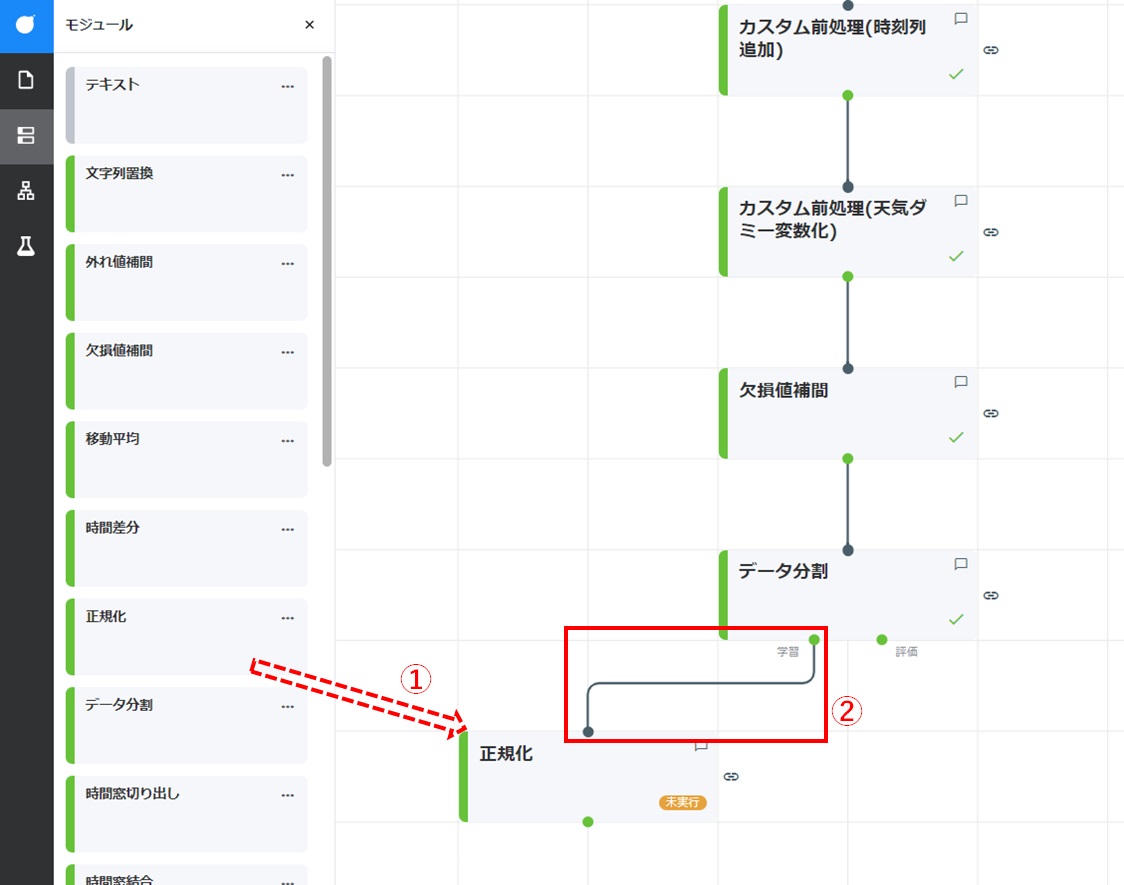
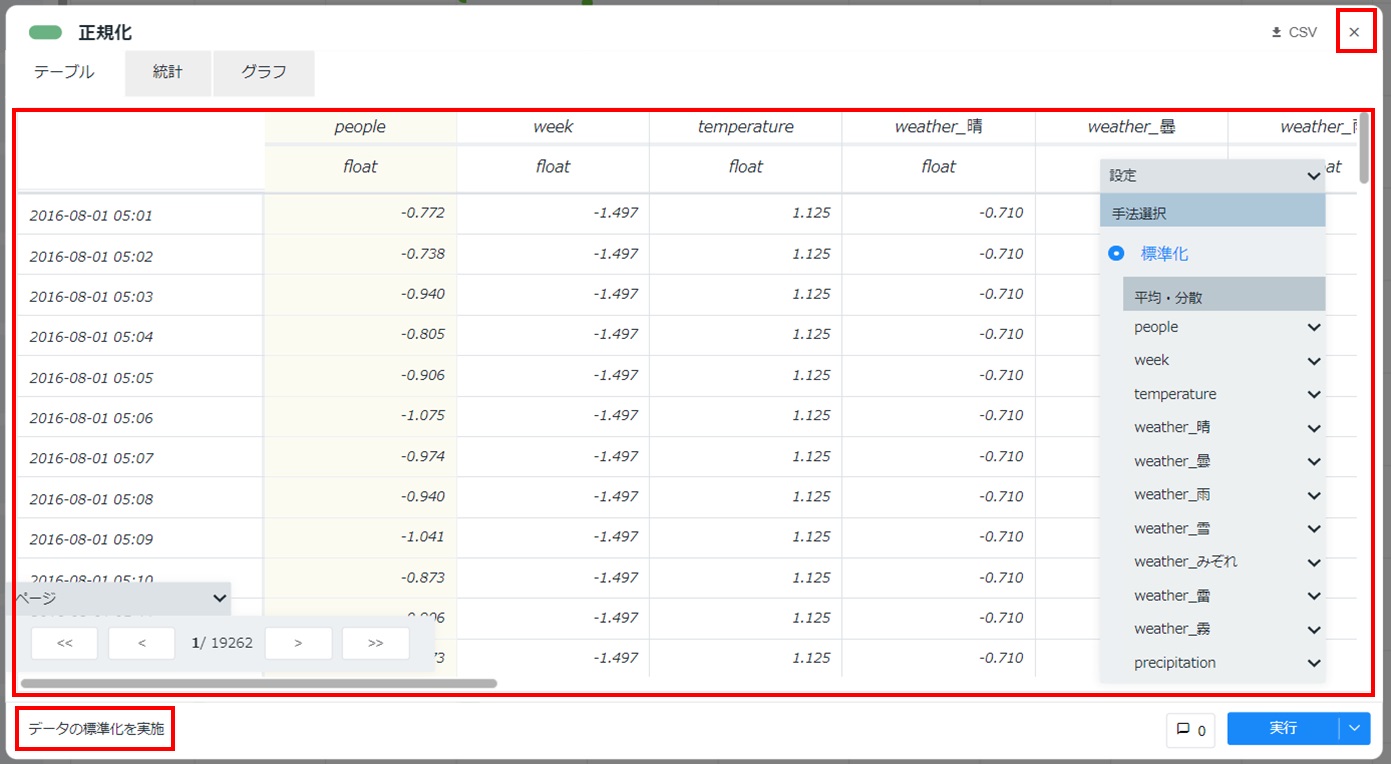
配置した正規化カードをダブルクリックして開き、[設定]をクリックし「手法選択」にて[標準化]が選択されていることを確認し、[実行]をクリックします。

カードの左下に「データの標準化を実施」と表示され、テーブルが表示されることを確認します。カード右上の[×]をクリックしてカードを閉じます。
正規化カード(テストデータ用)を設定する¶
上の手順と同様に、テストデータに対しても同様の処理を行います。
正規化カードをドラッグして「データ分割」カードの右下に配置します。「データ分割」カードの「評価」コネクタからドラッグして、新たに配置した正規化カードのコネクタに結線します。また、上の手順で作成した「正規化」カード(学習データ用)とのコンフィグリンク(カードの横方向の線)を接続します。
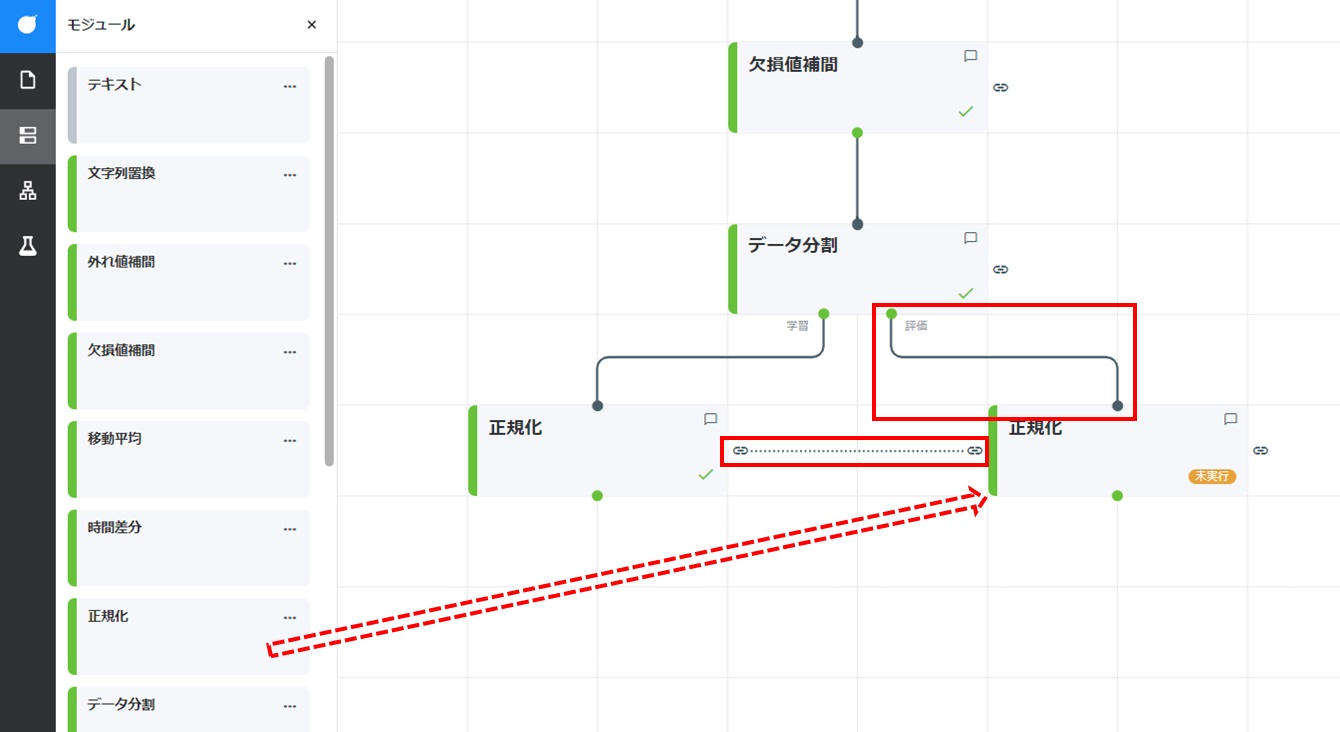
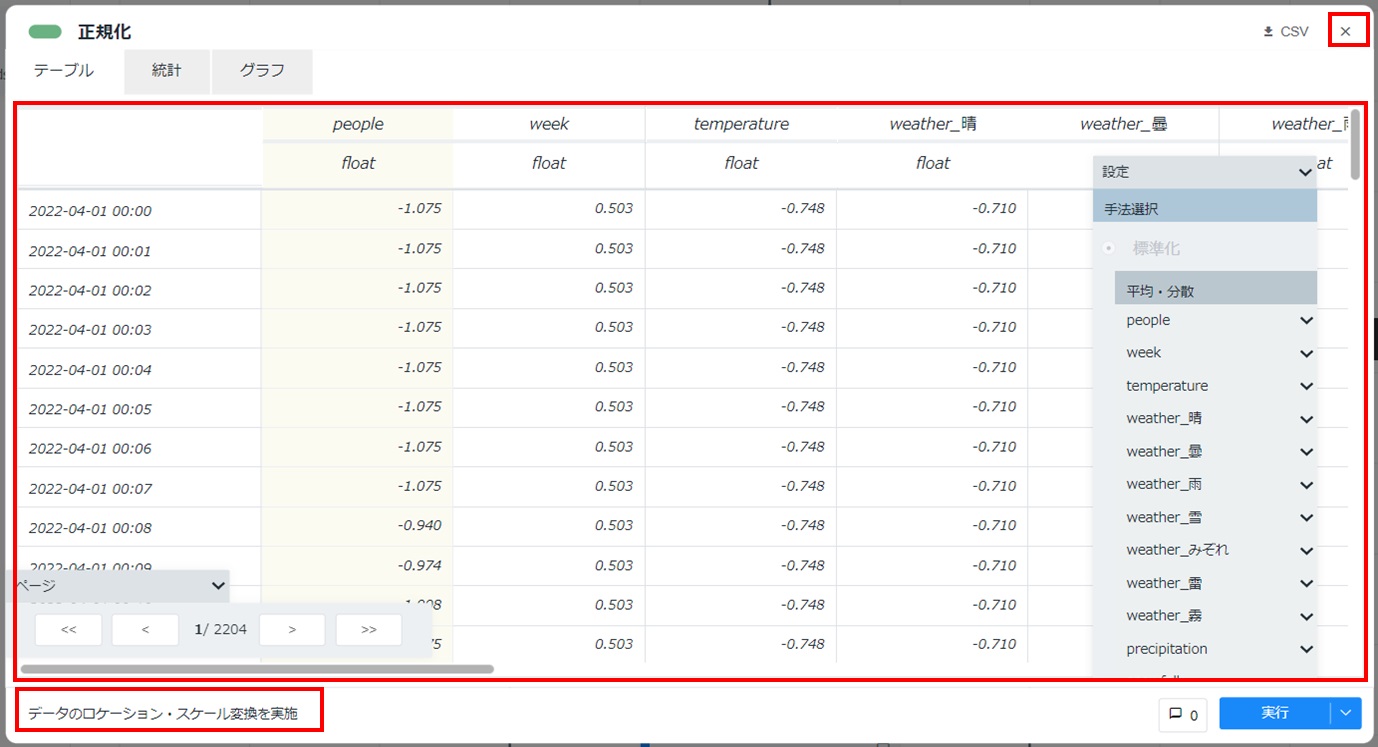
配置した正規化カードをダブルクリックして開き、[設定]をクリックし「手法選択」にて[標準化]が選択されていることを確認し、[実行]をクリックします。

カードの左下に「データのロケーション・スケール変換を実施」と表示され、テーブルが表示されることを確認します。カード右上の[×]をクリックしてカードを閉じます。
時間窓切り出しカード(学習データ用)を設定する¶
時間窓切り出しカードを用い、時系列データである学習データを学習可能な形式に変換します。
カード・設定パラメーターの詳細は「Node-AIマニュアル - 3.2.時間窓切り出し」を参照ください。
時間窓切り出しカードをドラッグして「正規化」カード(学習データ用)の下に配置します。「正規化」カード(学習データ用)のコネクタからドラッグして、新たに配置した時間窓切り出しカードのコネクタに結線します。
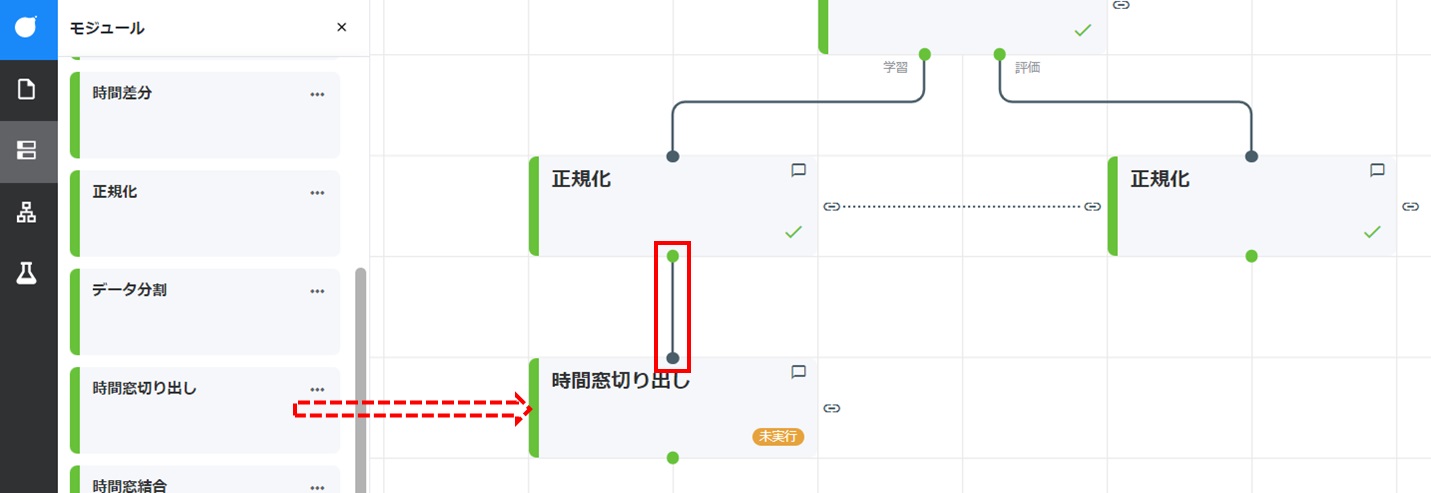
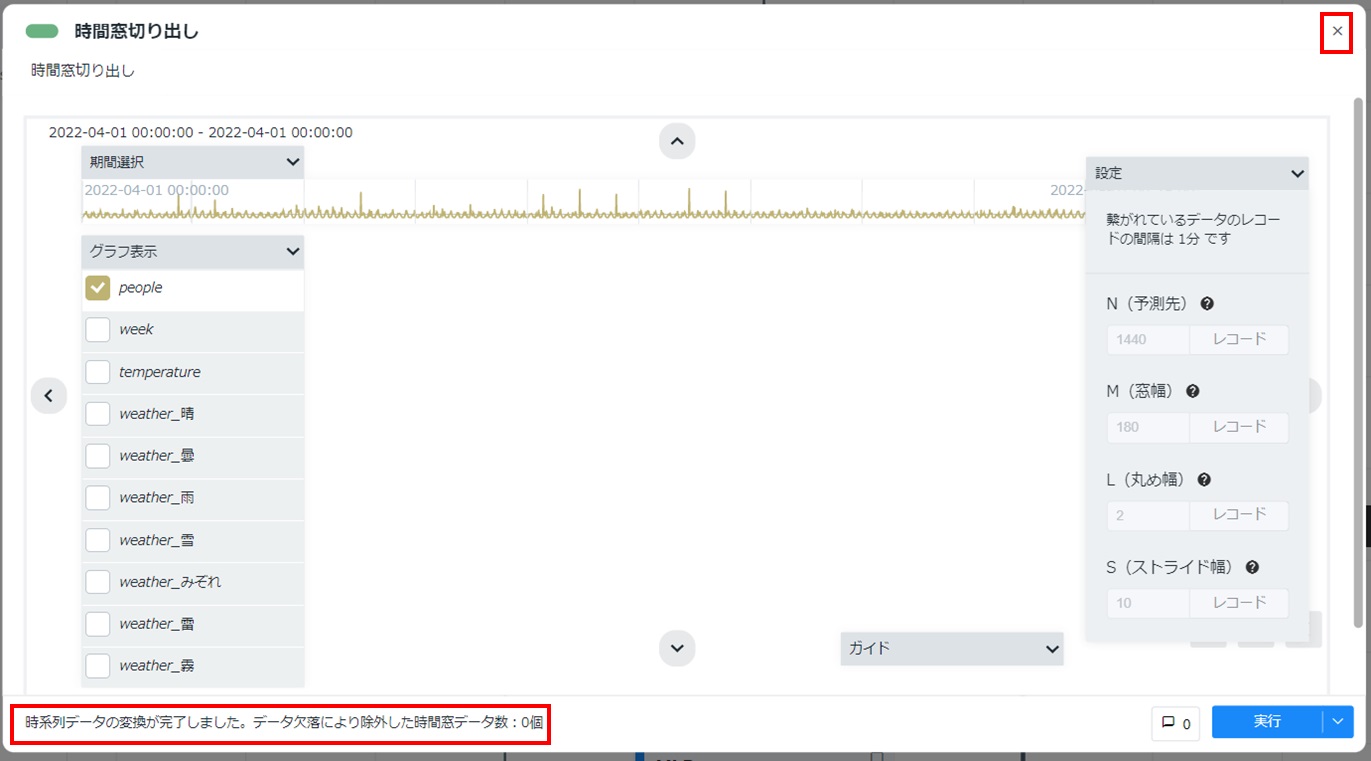
- 配置した時間窓切り出しカードをダブルクリックして開きます。「Node-AIマニュアル - 3.2.時間窓切り出し」を参考に、要件に応じて設定欄のパラメーターを指定して[実行]をクリックします。本項では、「N=1440」「M=180」「L=2」「S=10」を例として記載しています。
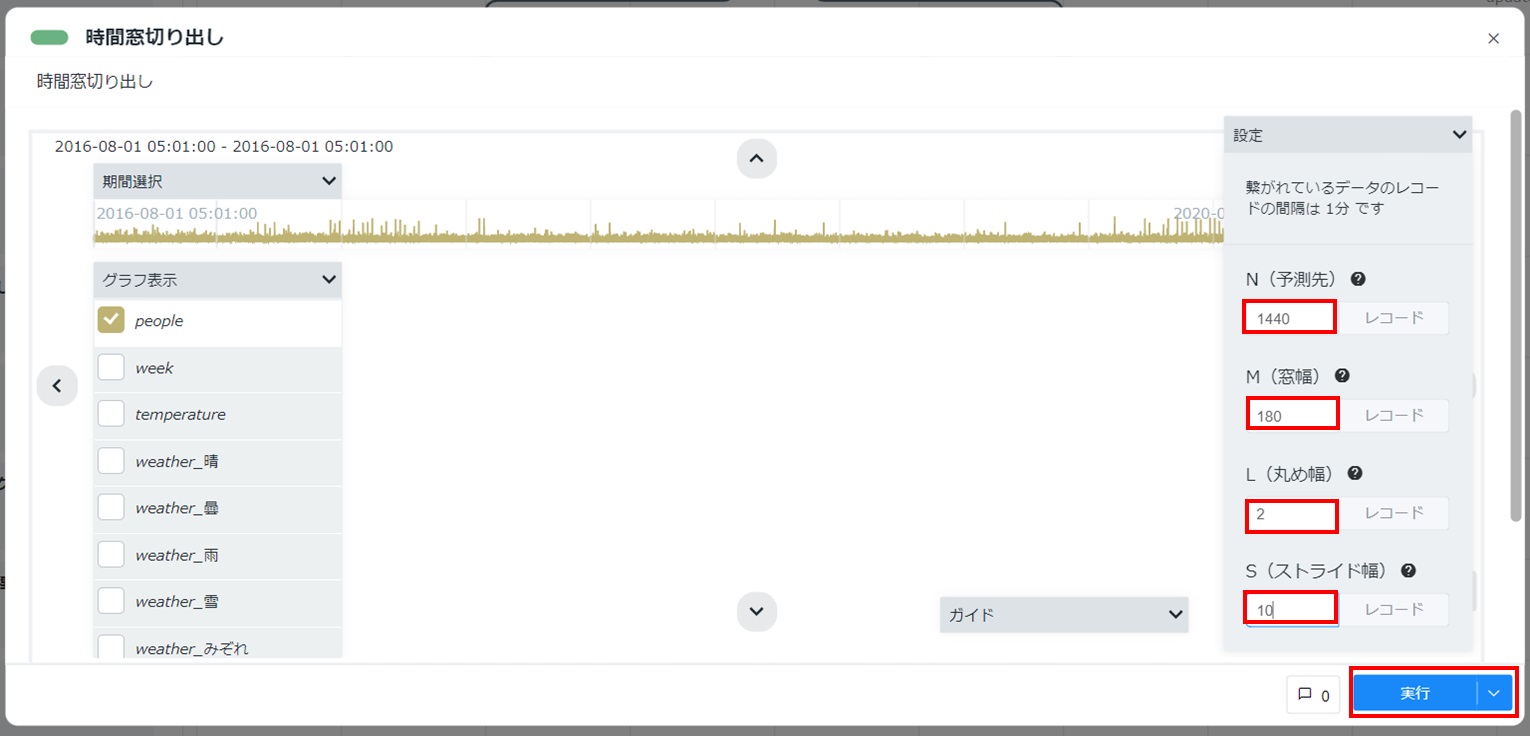
カードの左下に「時系列データの変換が完了しました。データ欠落により除外した時間窓データ数:XXX個」と表示されることを確認します。カード右上の[×]をクリックしてカードを閉じます。
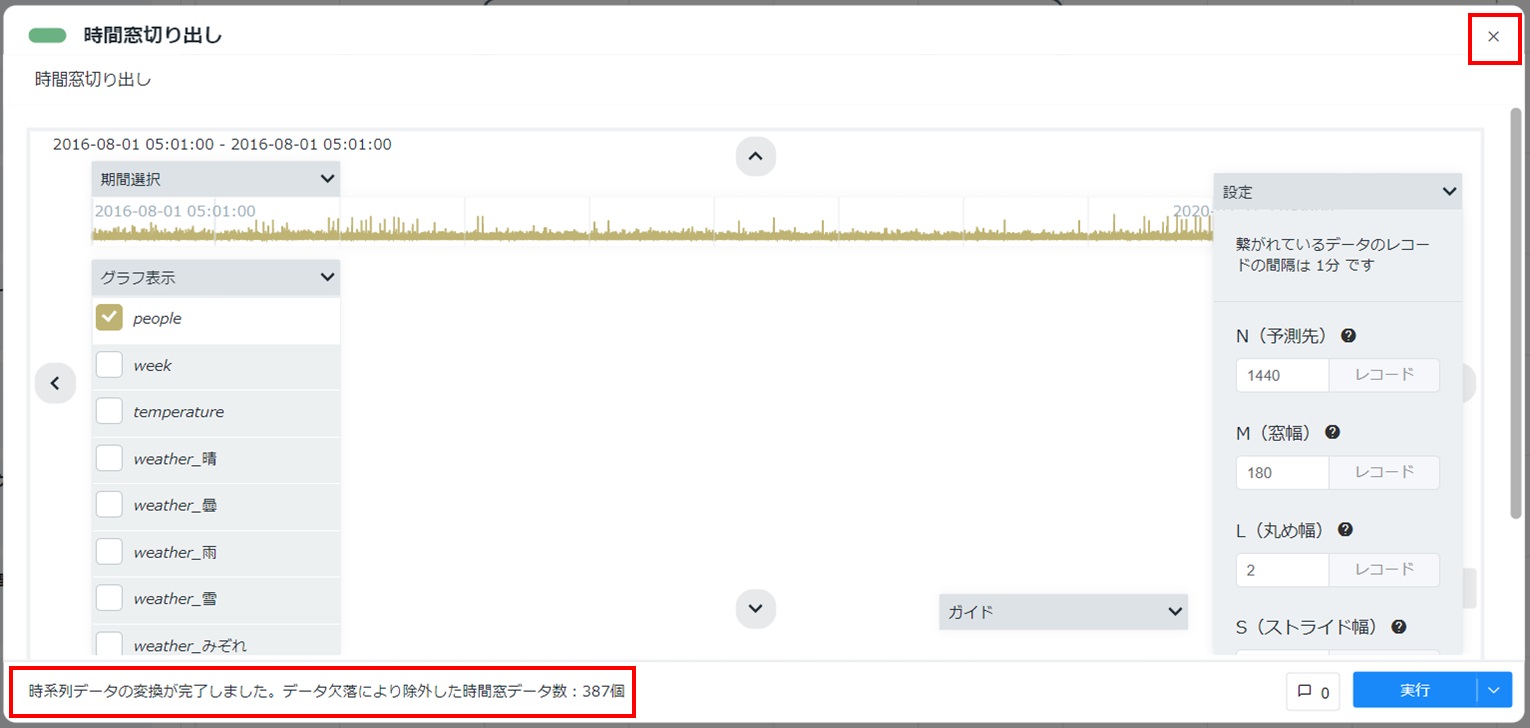
時間窓切り出しカード(テストデータ用)を設定する¶
上の手順と同様に、テストデータに対しても同様の処理を行います。
時間窓切り出しカードをドラッグして「正規化」カード(テストデータ用)の下に配置します。「正規化」カード(テストデータ用)のコネクタからドラッグして、新たに配置した時間窓切り出しカードのコネクタに結線します。また、上の手順で作成した「時間窓切り出し」カード(学習データ用)とのコンフィグリンク(カードの横方向の線)を接続します。
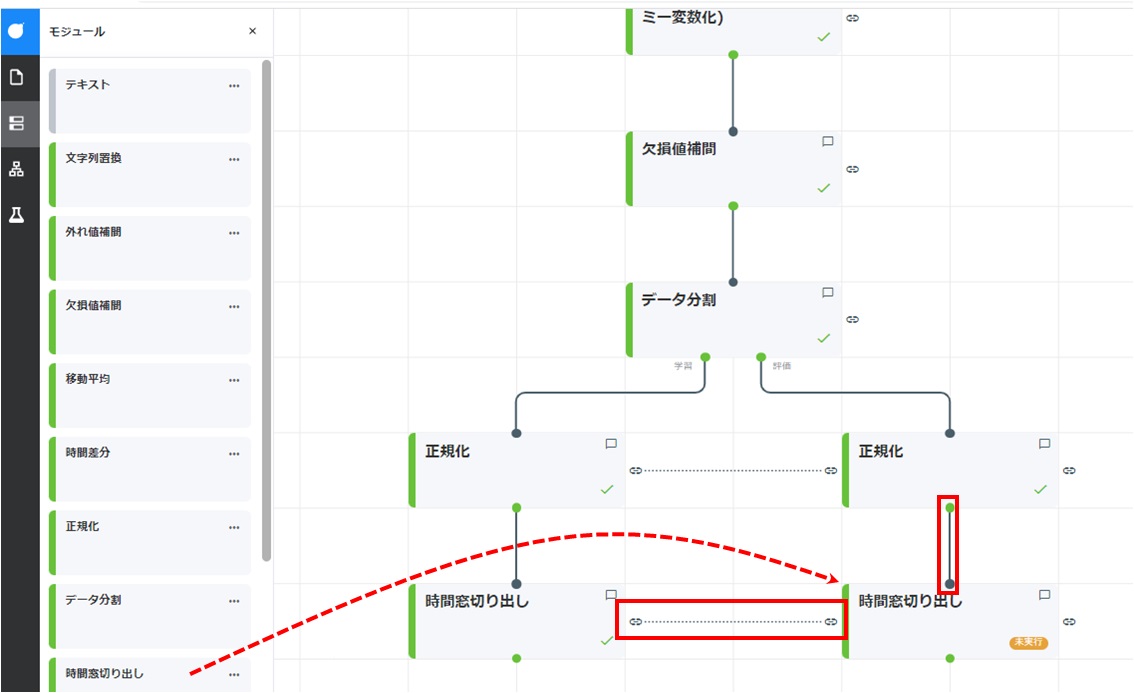
配置した時間窓切り出しカードをダブルクリックして開きます。上の手順で設定した「時間窓切り出し」カード(学習データ用)と同じパラメーターが入力されていることを確認し、[実行]をクリックします。
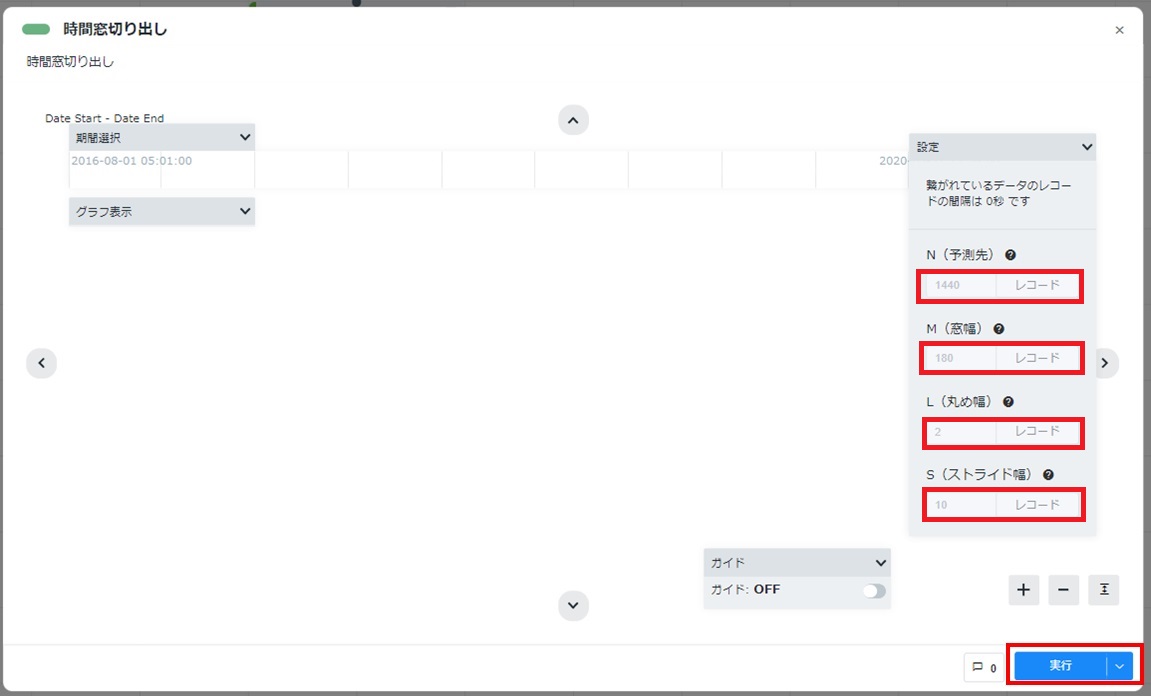
カードの左下に「時系列データの変換が完了しました。データ欠落により除外した時間窓データ数:XXX個」と表示されることを確認します。カード右上の[×]をクリックしてカードを閉じます。
学習モデルを作成する¶
学習モデルの作成をするためのカードを設定します。
本項では、「深層学習モデル(MLP)」を例として記載していますが、要件に応じて「線形モデル」や「決定木回帰モデル」も選択できます。
MLPカードを設定する¶
MLPカードを用い、深層学習モデル(MLP: ニューラルネットワーク)を設計します。
カード・設定パラメーターの詳細は「Node-AIマニュアル - 4.1.a.深層学習モデルの設計 (MLP)」を参照ください。
MLPカードをドラッグして2枚の時間窓切り出しカードの下に配置します。結線は不要です。
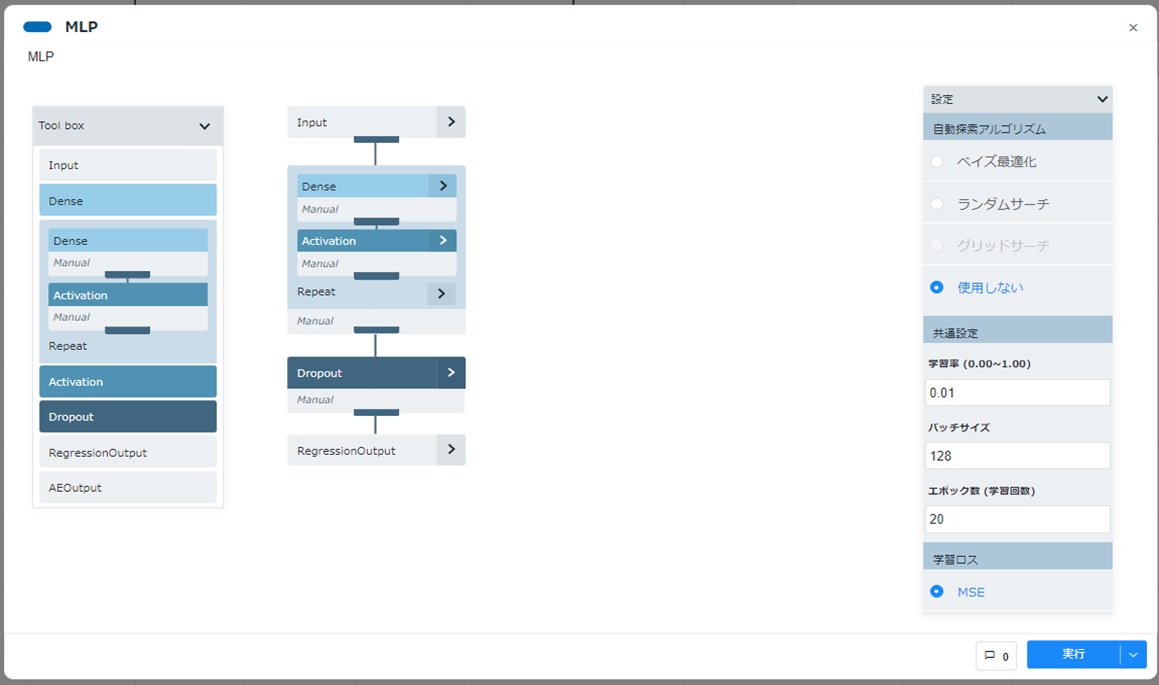
配置したMLPカードをダブルクリックして開きます。デフォルトのレイヤー設定とモデル/学習設定が表示されることを確認します。
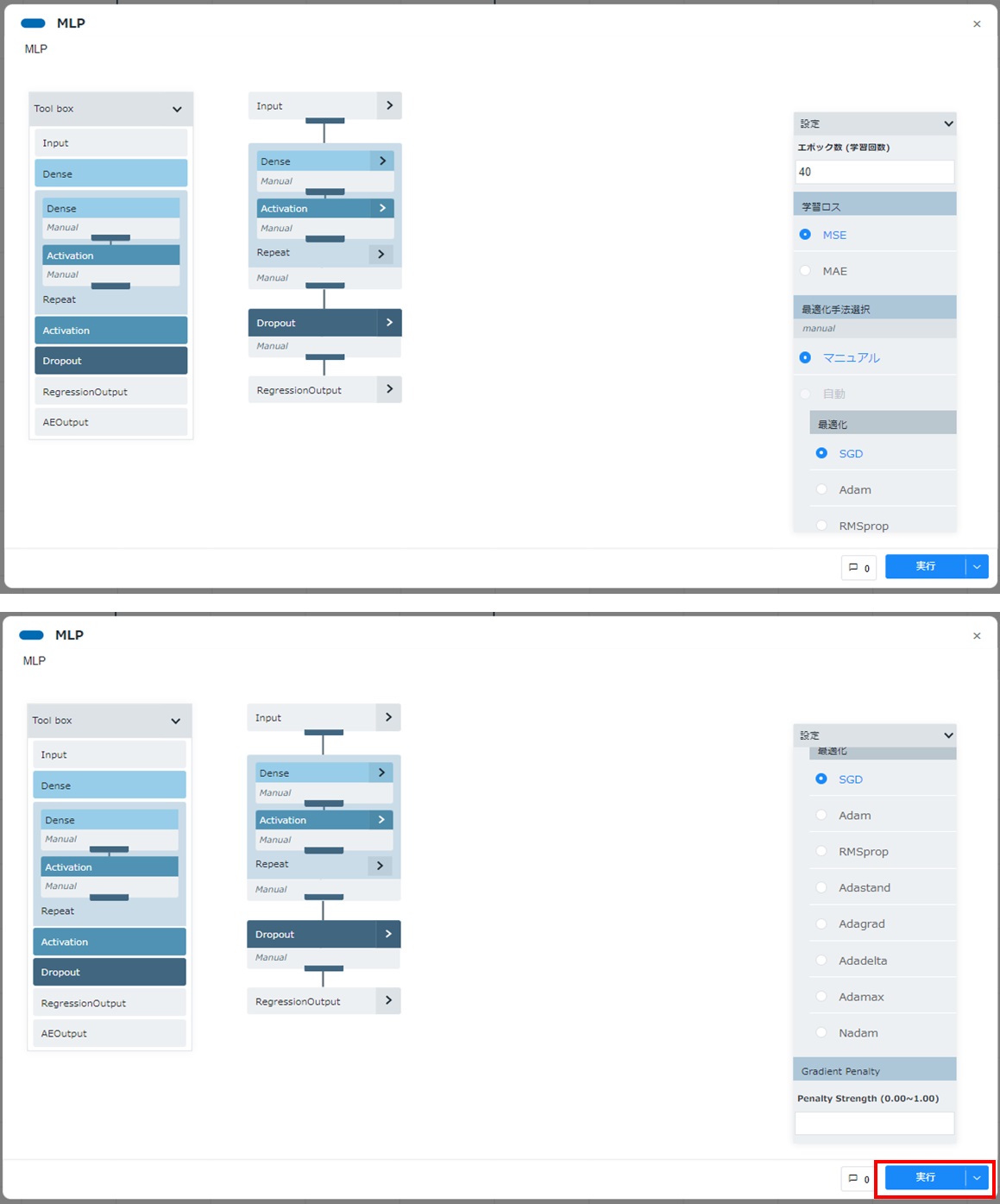
- 学習モデル作成のためのパラメーターを設定します(後述の「学習モデルの評価」の結果を基に適宜パラメーターを変更する箇所となります)。例として本項では、「自動探索アルゴリズム」は[使用しない]を選択し、「共通設定」では「学習率」を"0.001"、「エポック数」を"40"と変更しています。
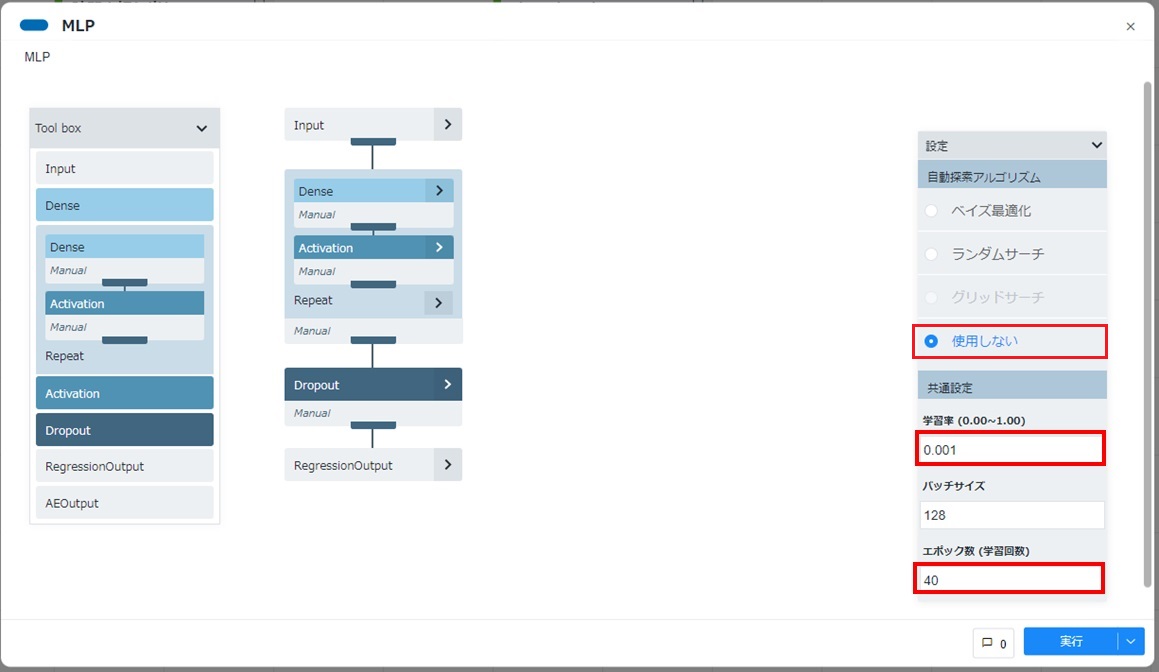
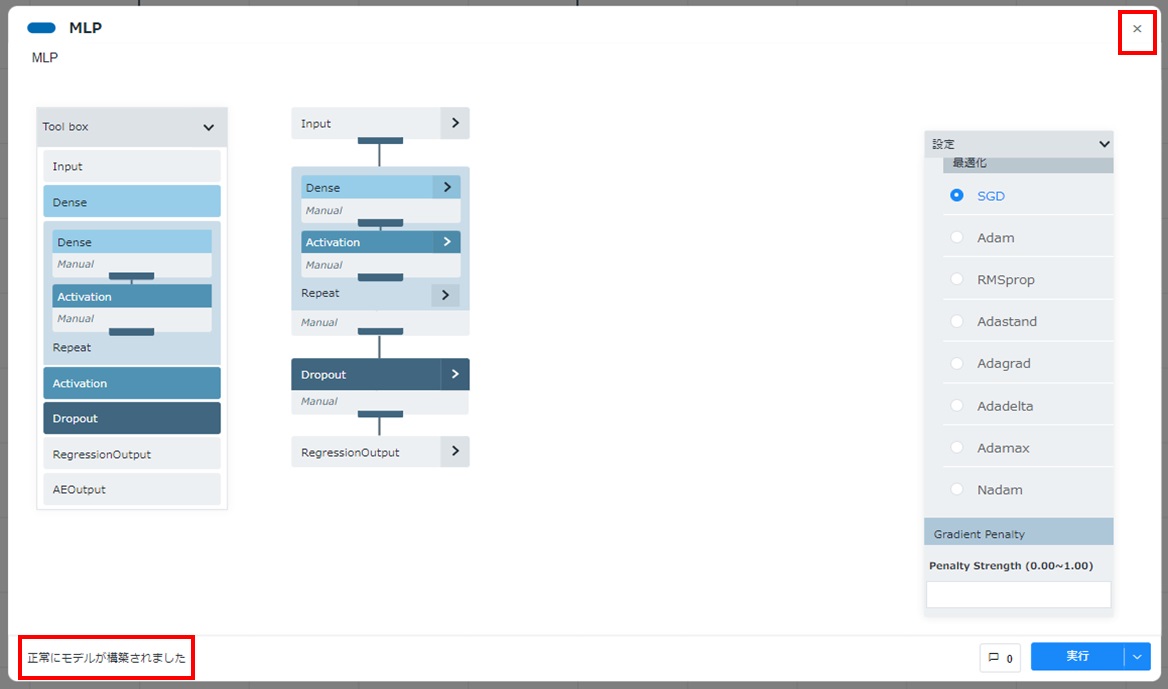
すべてのパラメーターを確認・修正し、[実行]をクリックします。
カードの左下に「正常にモデルが構築されました」と表示されることを確認します。カード右上の[×]をクリックしてカードを閉じます。
学習カードを設定し、モデルの学習を実施する¶
学習カードを用い、モデルの学習をします。
カード・設定パラメーターの詳細は「Node-AIマニュアル - 4.2.学習」を参照ください。
学習カードをドラッグし、「時間窓切り出し」カード(学習データ用)および「MLP」カードと結線しやすい位置に配置します。各カードのコネクタからドラッグして、新たに配置した学習カードのコネクタに結線します。
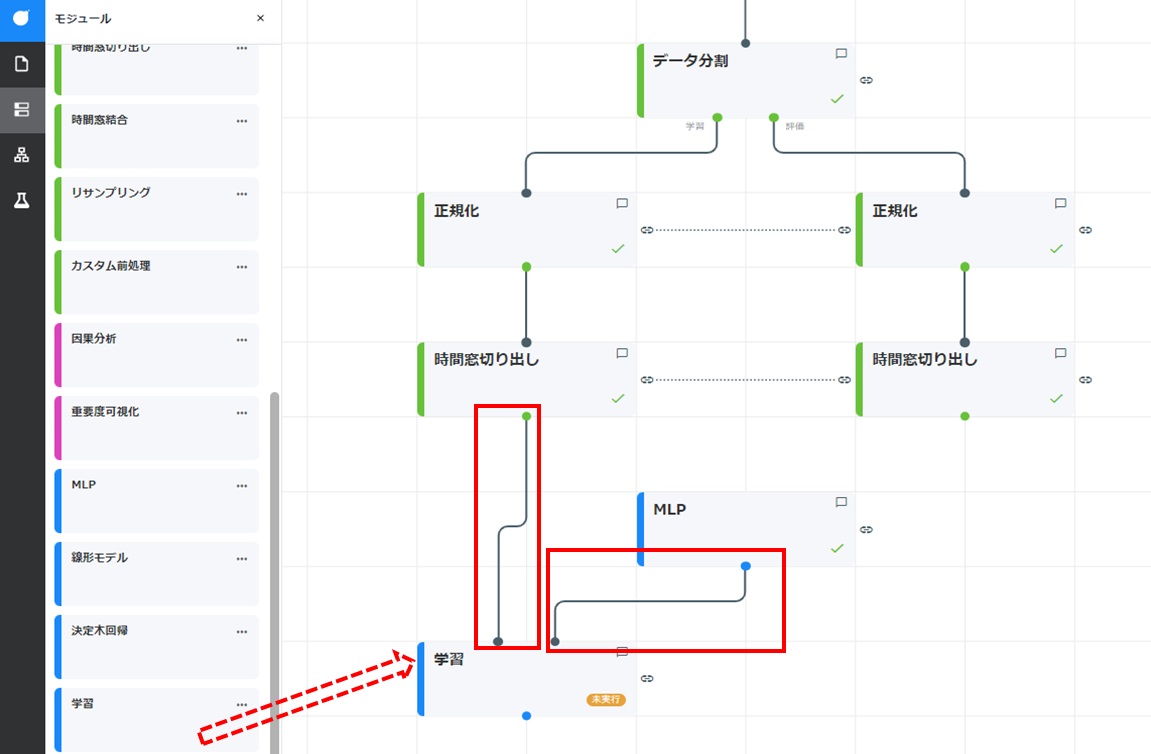
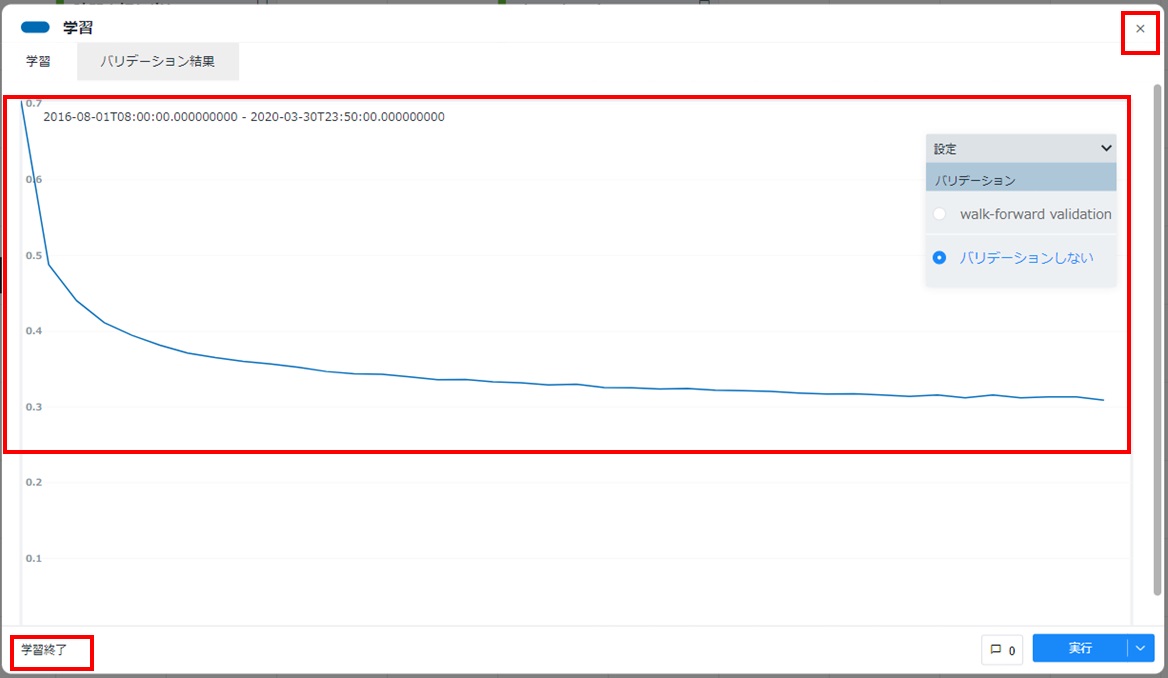
- 配置した学習カードをダブルクリックして開きます。[設定]をクリックし「バリデーション」にて、[バリデーションしない]が選択されていることを確認し、[実行]をクリックします。本項では「バリデーション」を[バリデーションしない]と選択していますが、ハイパーパラメーターの探索をする場合は[walk-forward validation]を利用します。
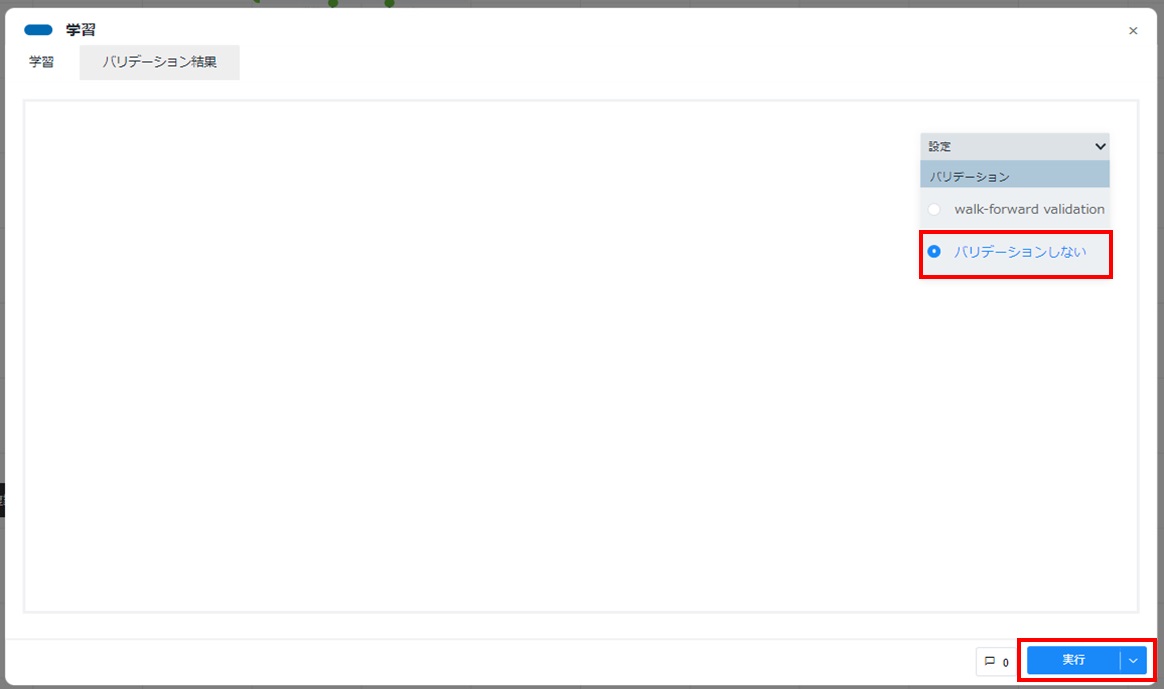
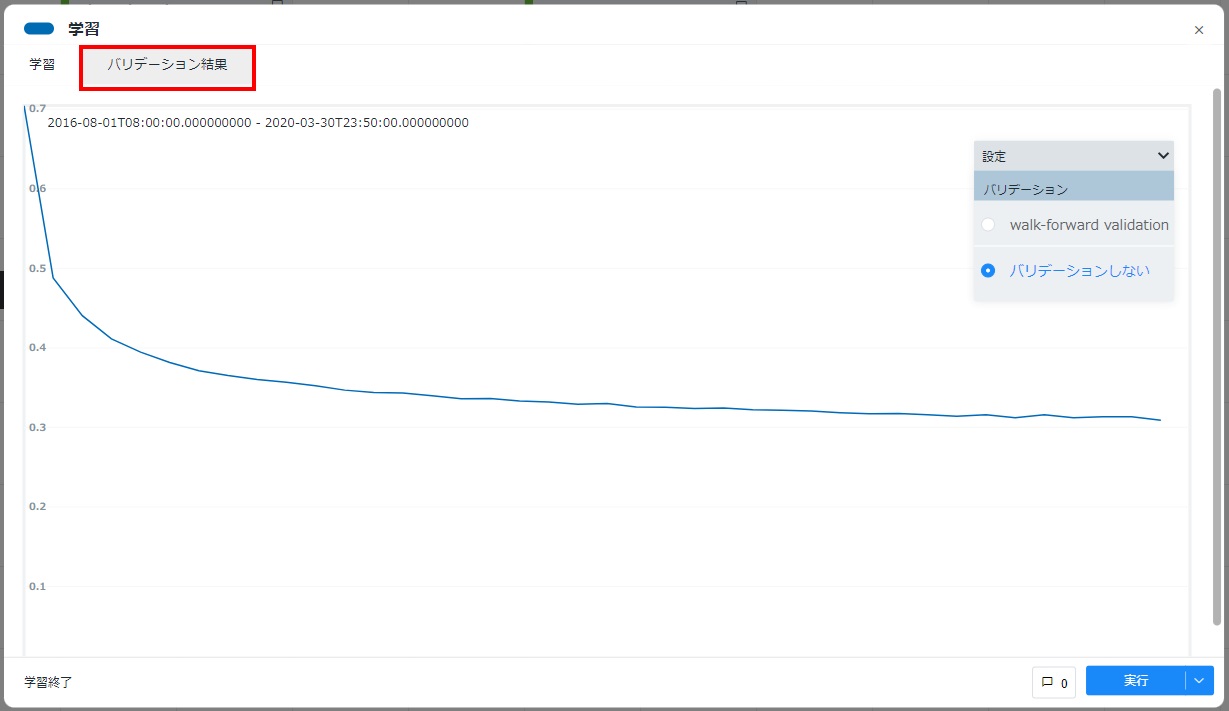
[実行]をクリックすると学習処理が行われます。また、学習の進行に併せて学習曲線が描画されます。学習処理が終わるまで待機し、カードの左下に「学習終了」と表示されることを確認します。カード右上の[×]をクリックしてカードを閉じます。
学習モデルを評価する¶
評価カードを用い、作成した学習モデルを評価します。
実測値と、学習モデルを用いた予測値をグラフ上に重ねて表示させることができます。
カード・設定パラメーターの詳細は「Node-AIマニュアル - 5.1.評価」を参照ください。
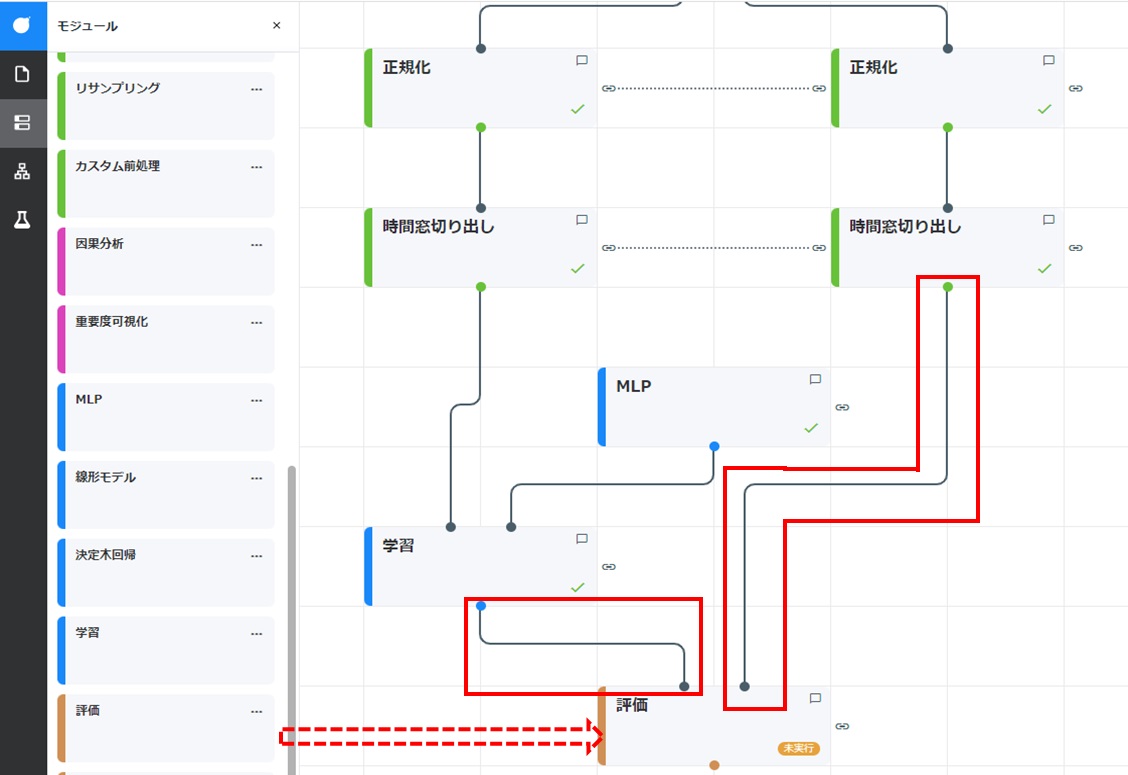
評価カードを学習カードと評価データの時間窓切り出しカードの各カードと結線しやすい位置に配置し、各カードと結線します。
評価カードをドラッグし、「学習」カードおよび「時間窓切り出し」カード(テストデータ用)と結線しやすい位置に配置します。各カードのコネクタからドラッグして、新たに配置した評価カードのコネクタに結線します。
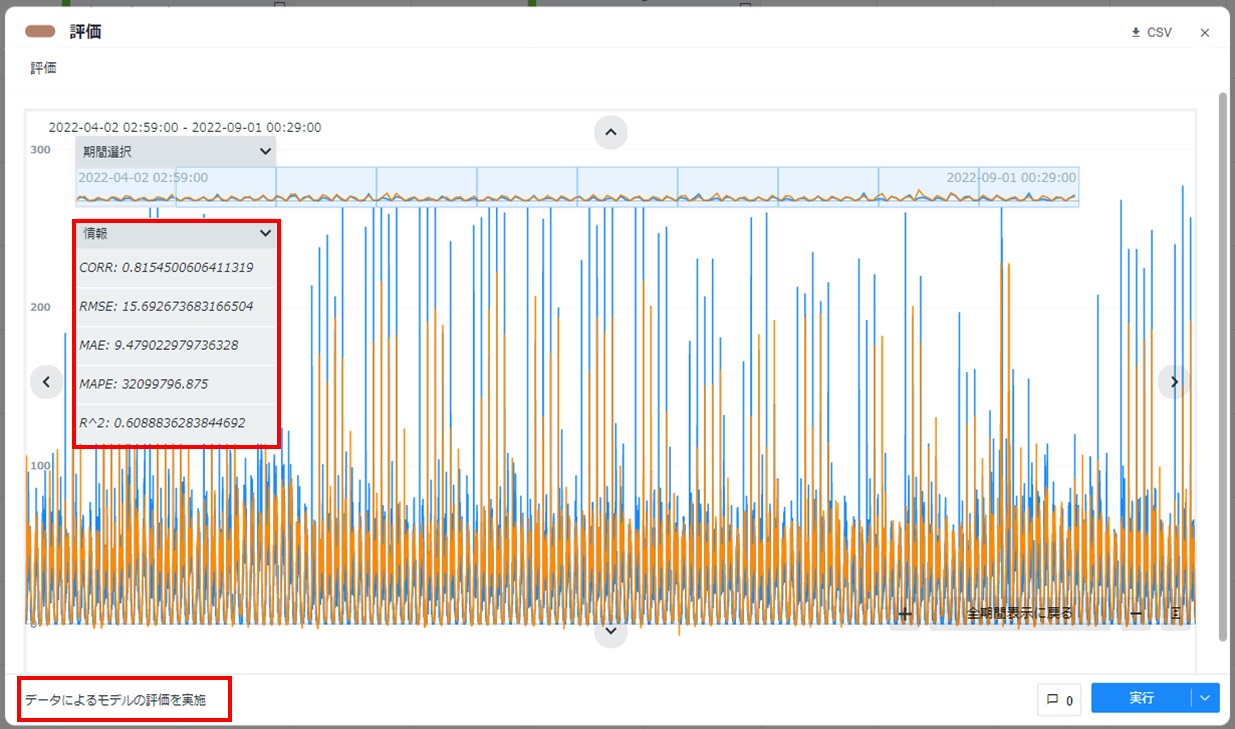
配置した評価カードをダブルクリックして開き、[実行]をクリックします。

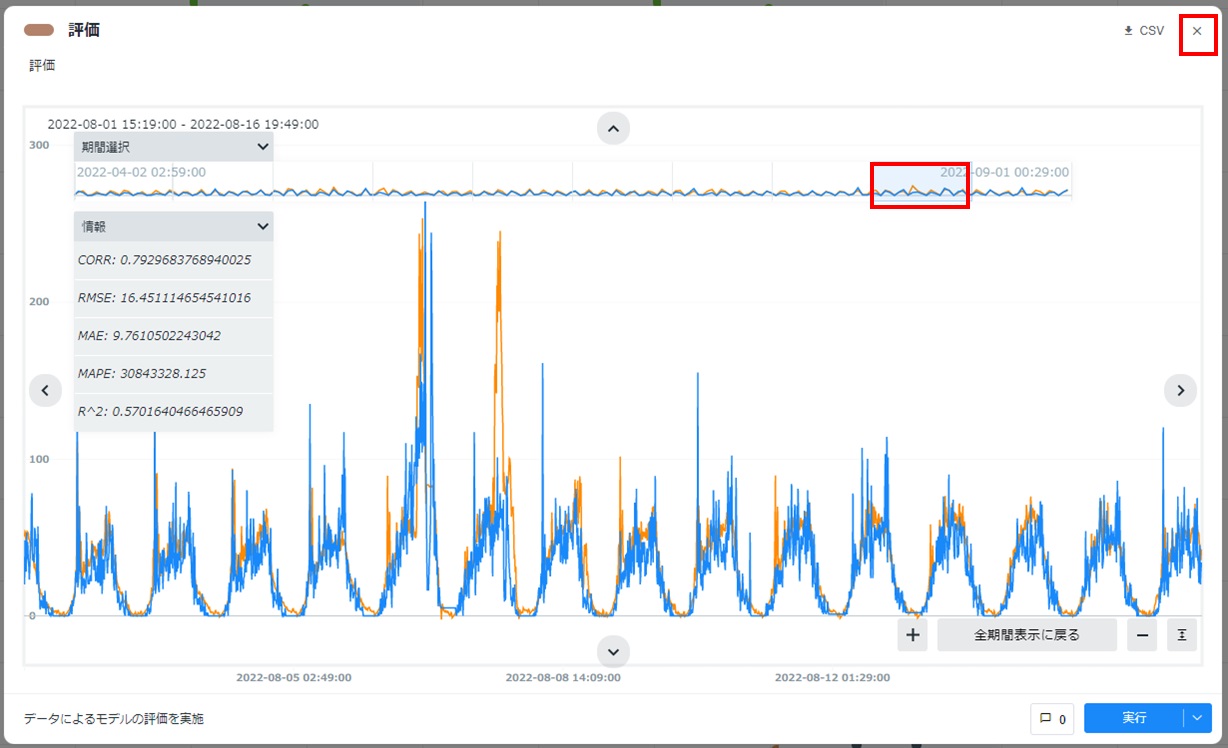
- 評価カードの左下に「データによるモデルの評価を実施」と表示され、グラフが表示されること、カードの左側に評価指標が表示されることを確認します。グラフは一部の時間帯を切り出したり、拡大/縮小したり、CSVファイル形式で出力できます。詳しくは「Node-AIマニュアル - 5.1.評価」を参照ください。カード右上の[×]をクリックしてカードを閉じます。
学習モデルをアップロードする¶
Node-AI Berryを用いた予測のAPI化のため、これまでの手順で作成した学習モデルをWasabiへアップロードします。
「Node-AIマニュアル - モデルのアップロード 」も併せて参照ください。
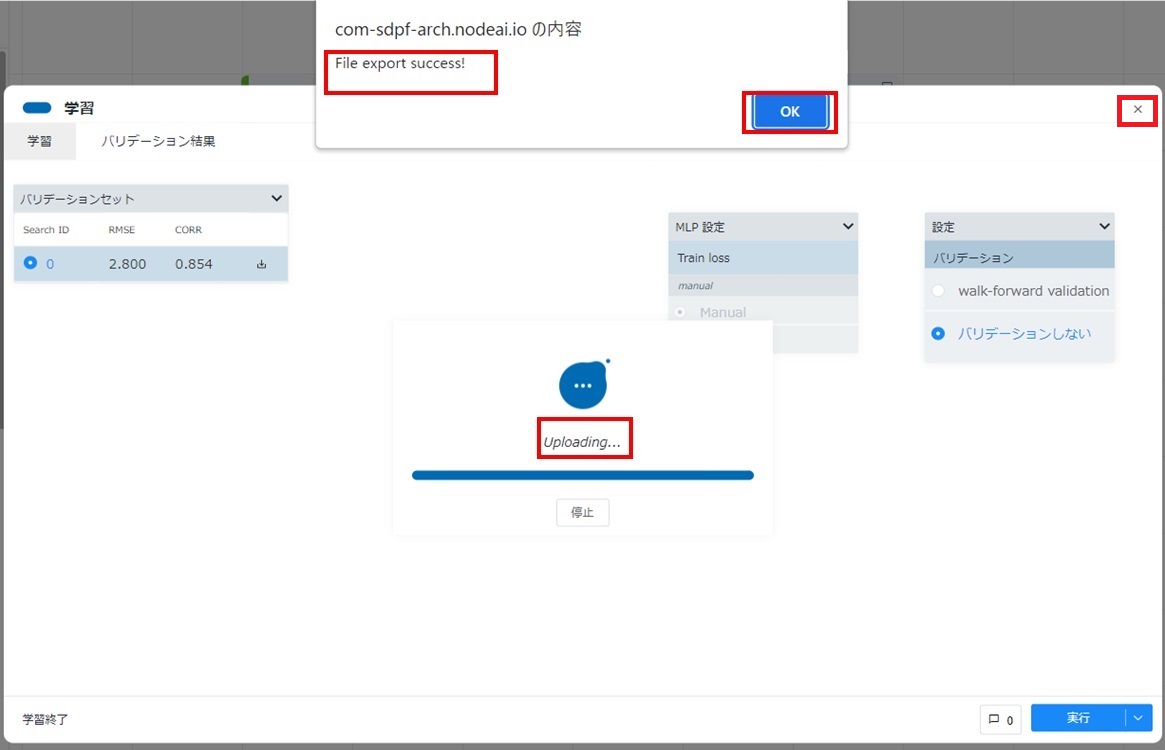
[学習]カードをダブルクリックして開き、[バリデーション結果]タブをクリックします。
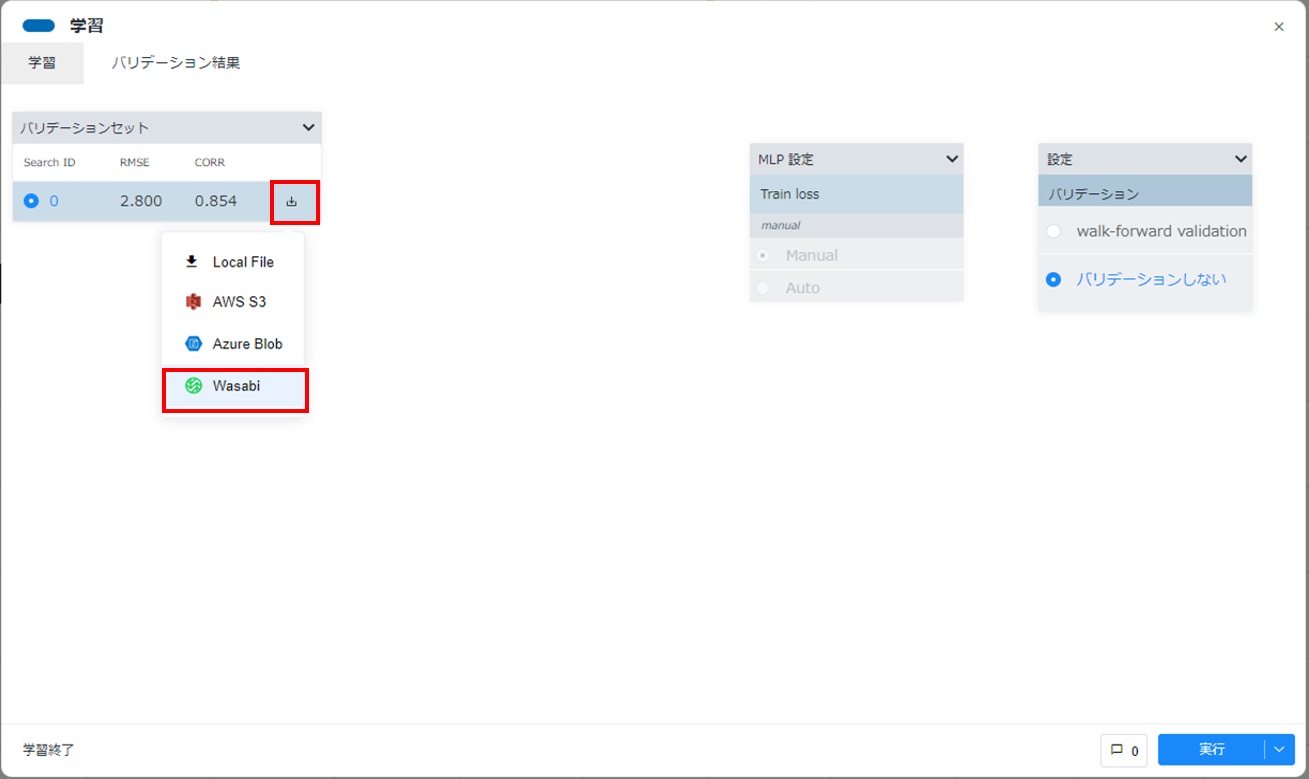
「バリデーションセット」に表示されている、[保存]マークをクリックし、メニューから[Wasabi]をクリックします。
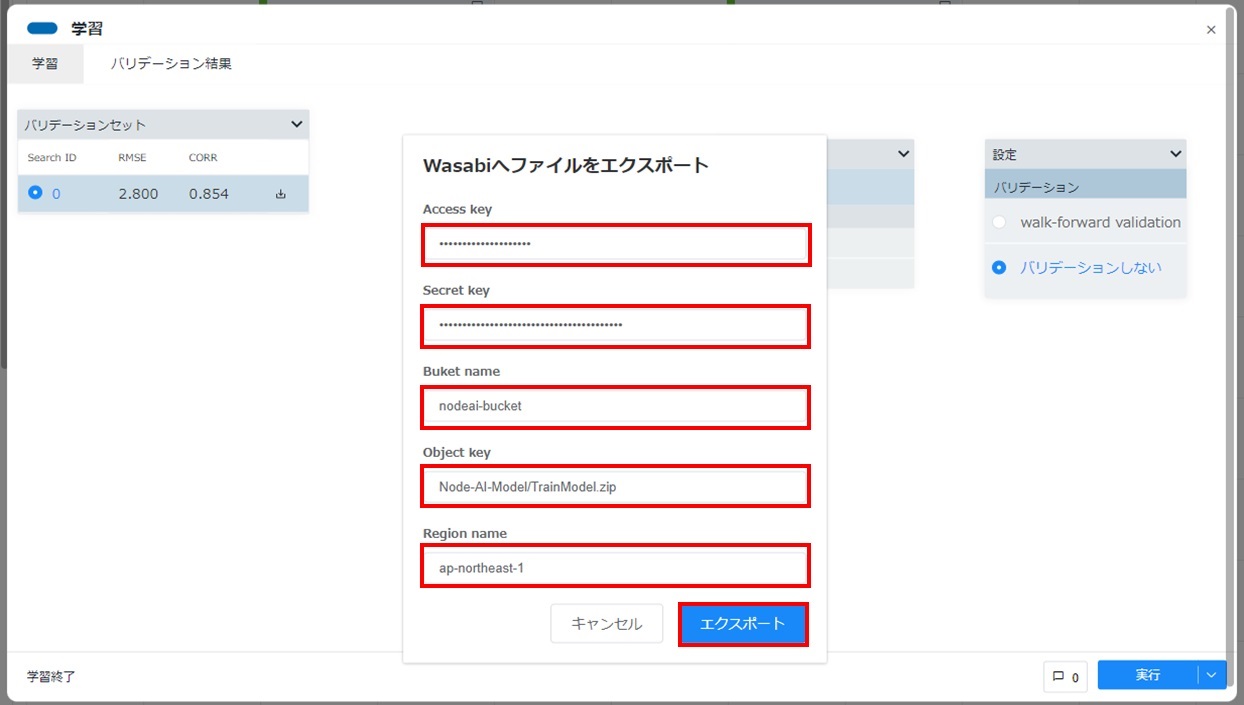
Wasabiに関するパラメーターには下記を設定し、[エクスポート]をクリックします。
項目
値
備考
Access key
<Node-AI Berry用Wasabiユーザーの「アクセスキー」>
「 1.1.3.1. Wasabiオブジェクトストレージを設定する - Node-AI Berry用ユーザーを作成する 」で取得した「アクセスキー」を入力してください。
Secret key
<Node-AI Berry用Wasabiユーザーの「秘密鍵」>
「 1.1.3.1. Wasabiオブジェクトストレージを設定する - Node-AI Berry用ユーザーを作成する 」で取得した「秘密鍵」を入力してください。
Bucket name
<学習モデルを保管するバケットの名前(例:nodeai-bucket)>
「 1.1.3.1. Wasabiオブジェクトストレージを設定する - バケットを作成する 」で作成したバケット名を入力してください。
Object key
<バケット内のファイルパス(例:Node-AI-Model/TrainModel.zip)>
アップロードする学習モデルを保存するバケット内のファイルパスを入力してください。
Region name
<バケットのリージョン(例:ap-northeast-1)>
「 1.1.3.1. Wasabiオブジェクトストレージを設定する - バケットを作成する 」で指定したリージョンを入力してください。
転送中であることを表す画面に切り替わるのでしばらく待機します。転送が完了し、「File export success!」のダイアログが表示されることを確認します。[OK]ボタンをクリックし、カード右上の[×]をクリックしてカードを閉じます。