1.1.3.6. 予測を定期実行する¶
本項では、Alkanoを使用した予測の定期実行手順、また予測結果データファイルをWasabiオブジェクトストレージ(以下Wasabi)に保存する手順について記載します。
以下の手順は「1.1.3.3. サーバーインスタンスを構築する」で構築したサーバー(以下Alkanoサーバー)で行います。
なお、本項中の設定値の「< >」の表記については、利用の環境により各自入力いただく箇所となります("<"から">"までを設定値に置き換えてください)。
前提条件を確認する¶
あらかじめ、これまでの「1.1.3.5. 学習モデルを作成する」に記載されているすべての作業が完了していることを確認してください。
予測用データを用意する¶
- Alkanoでの予測に用いる予測用データであるcsvファイルを作成します(本構成ガイドではファイル名を「sensor.csv」としています)。このcsvファイルは、「1.1.3.5. 学習モデルを作成する - 学習モデルを作成する(勾配ブースティング決定木アイコン)」で説明変数に選択した列と同じ列分、また行数は1日分のデータを用意したファイルになります。
上記csvデータをWasabiに配置します。本構成ガイドでは配置先を「alkano-bucket/alkano-csv」としています。
REST APIドキュメントを入手する¶
シナリオを自動実行する際に必要なREST APIドキュメントを入手します。
REST APIドキュメントの入手につきましては、当社営業までお問い合わせください。
お問い合わせ先およびAlkanoの詳細情報につきましては、「データ分析 Alkano」をご覧ください。
予測実行を行うためのシナリオを作成する¶
注釈
- 以下の作業は「1.1.3.5. 学習モデルを作成する」で作成したシナリオ上で行います。
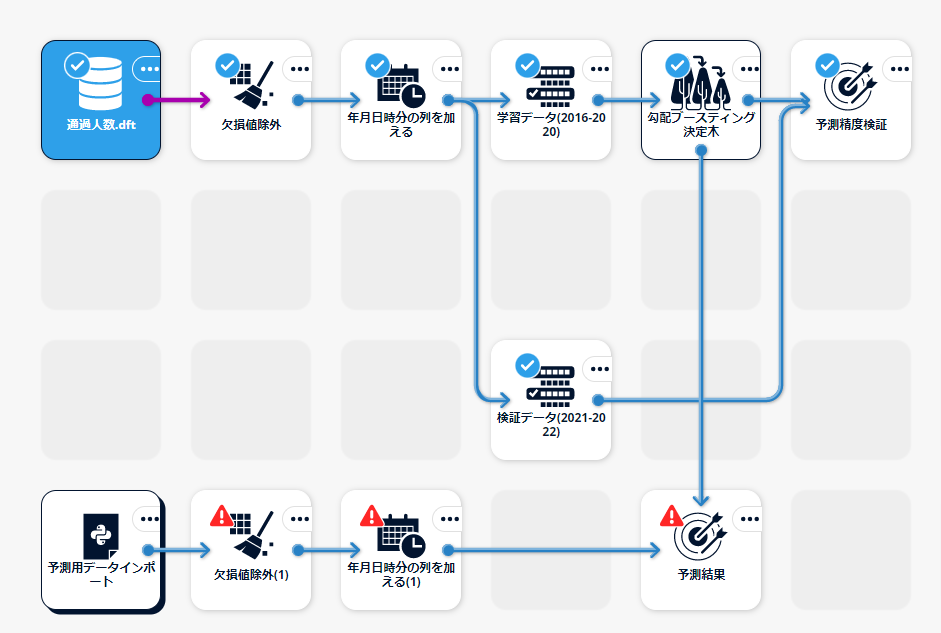
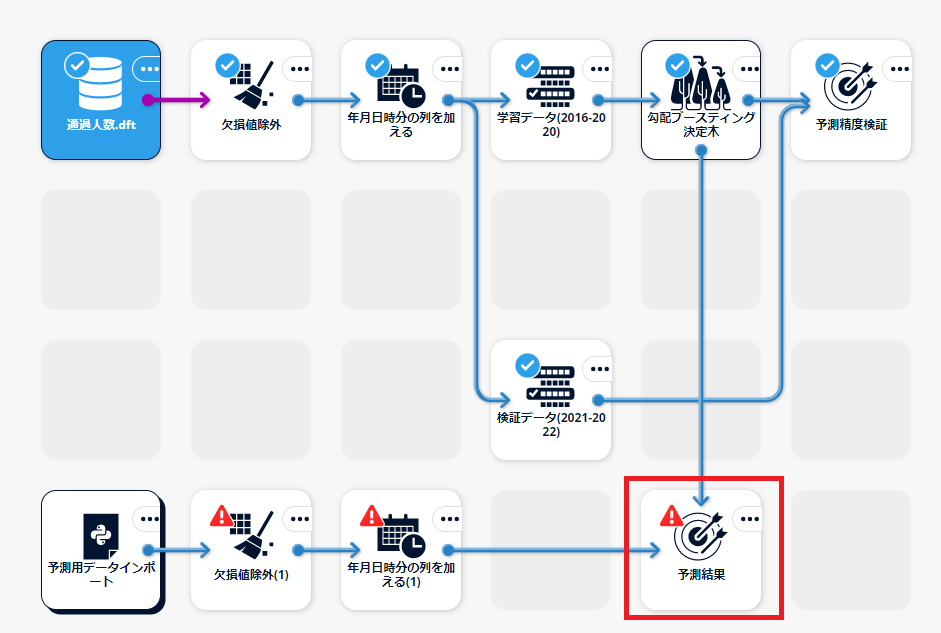
本構成ガイドで作成するシナリオの全体像は以下の図のとおりです。
メタパラメータを設定する¶
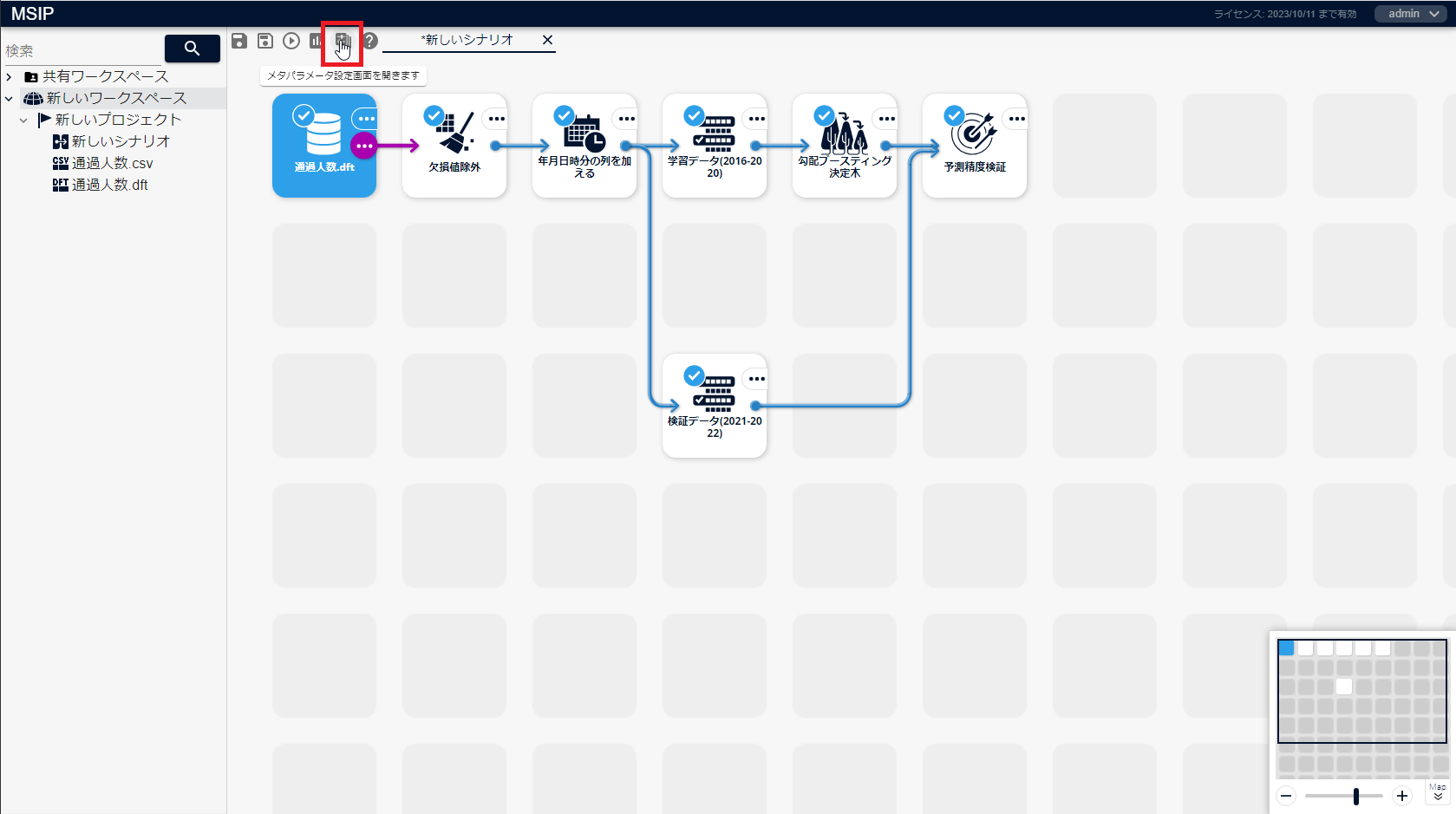
Pythonスクリプトアイコンで使用するメタパラメータを設定します。
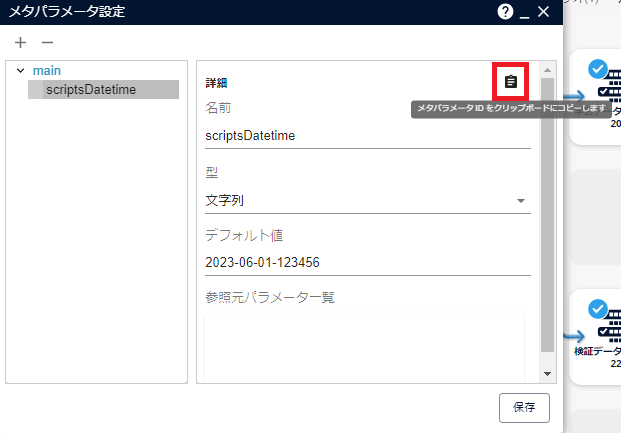
シナリオ画面上部にある、[メタパラメータ設定画面を開きます]アイコンをクリックします。
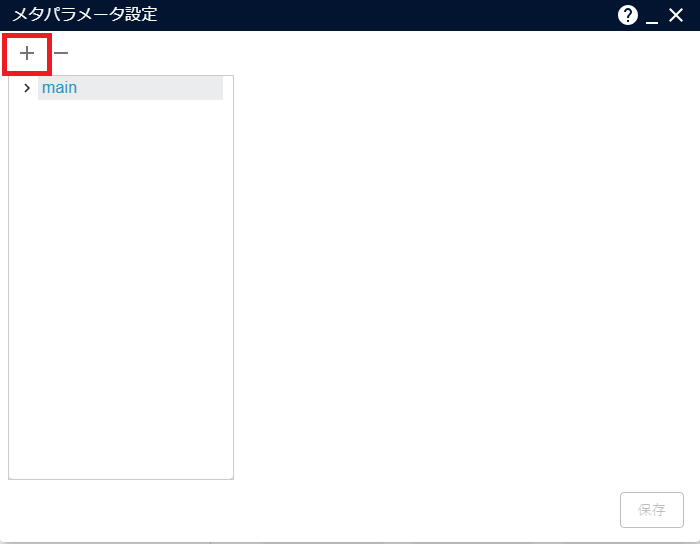
[+]をクリックし、メタパラメータを追加します。
以下パラメーターを入力し[保存]をクリックします。
項目 値 名前 任意のメタパラメータ名(例:scriptsDatetime) 型 文字列 デフォルト値 <任意のデフォルト値(例:2023-06-01-123456)> 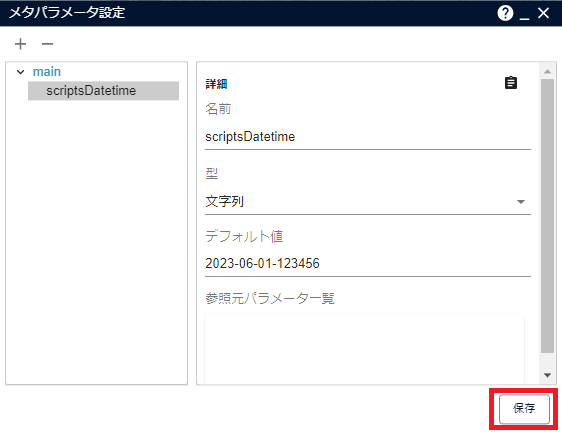
REST API実行用にメタパラメータID(メタパラメータ識別子)が必要になります。[メタパラメータIDをクリップボードにコピーします]をクリックしてコピーし、任意の場所に控えてください。
予測用データをインポートする(Pythonスクリプトアイコン)¶
Alkanoシナリオ内にWasabiから予測用データをインポートする「Pythonスクリプト」アイコンを配置します。
シナリオ画面内のアイコンが置かれていない場所を右クリックし、[Pythonスクリプトを追加]をクリックします。
[Python script]アイコンを右クリックし、[ノード名変更]をクリックします。

アイコンの名称を「予測用データインポート」に変更し、シナリオ画面の余白部分をクリックします。
[予測用データインポート]アイコンをダブルクリックして、パラメーター画面を開きます。
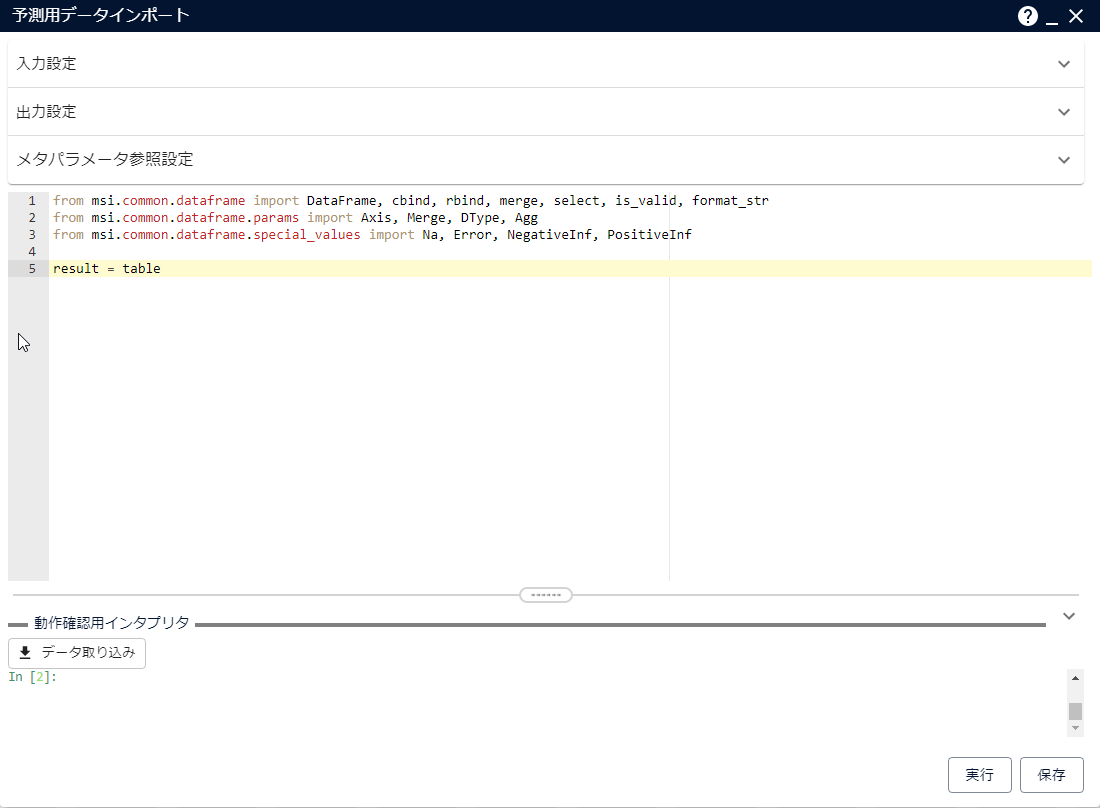
「入力設定」にデフォルトで設定されている変数「table」を、[-]をクリックして削除します。
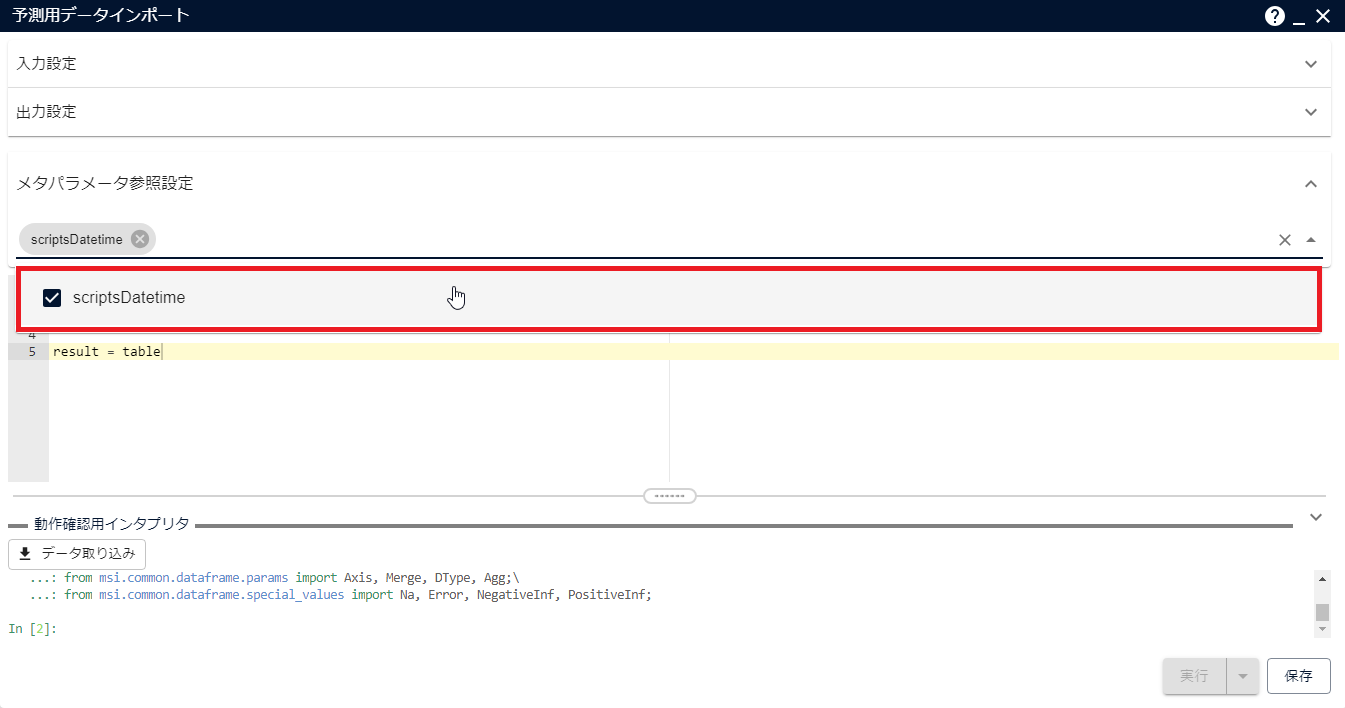
「メタパラメータ参照設定」に作成したメタパラメータを追加します。
スクリプト部分を以下の内容に書き換えて[保存]をクリックします(下記スクリプトはWasabiのリージョンが「ap-northeast-1」の場合です)。
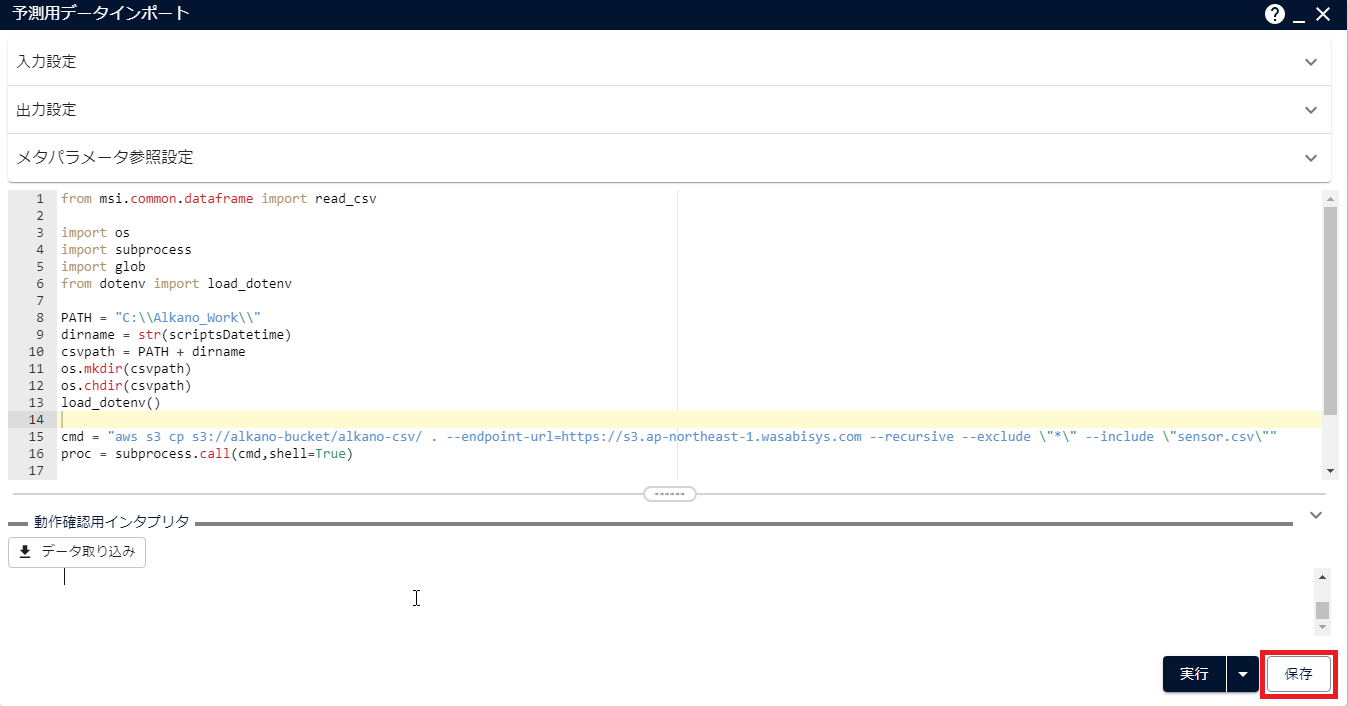
from msi.common.dataframe import read_csv import shutil import os import subprocess import glob from dotenv import load_dotenv PATH = "C:\\Alkano_Work\\" dirname = str(<作成したメタパラメータ名(例:scriptsDatetime)>) csvpath = PATH + dirname os.mkdir(csvpath) os.chdir(csvpath) load_dotenv() cmd = "aws s3 cp s3://alkano-bucket/alkano-csv/ . --endpoint-url=https://s3.ap-northeast-1.wasabisys-ntt.com --recursive --exclude \"*\" --include \"sensor.csv\"" proc = subprocess.call(cmd,shell=True) files = glob.glob(csvpath + '\\*.csv') for file in files: result = read_csv(file, datetime_formats=['%Y/%m/%d %H:%M:%S']) os.chdir("C:\\") shutil.rmtree(csvpath)
注釈
- 本スクリプトは動作確認用です。Wasabiからのファイル取得部分はCLI呼び出しの他に、APIで実施する方法もあります。
パラメーター画面右上の[×]をクリックし、パラメーター画面を閉じます。
「予測用データインポート」アイコン内のスクリプトを動作するにあたり、「dotenv」ライブラリをMSIP用のPython環境にインストールする必要があります。コマンドプロンプトを開き、以下のコマンドを実行します。
> C:\MSIP\python\Scripts\activate > python -m pip install dotenv
環境変数ファイルを作成する¶
上記Pythonスクリプト内で、Wasabiから予測用データをインポートする際に必要なアクセスキー・シークレットアクセスキー・リージョン名を保存する環境変数ファイルを作成します。
- エクスプローラで「C:\Alkano_Work」を開きます。
- 「C:\Alkano_Work」内に「.env」ファイルを作成し、そのファイルの内容を以下のように書き換えます。
AWS_Access_Key_ID='<※1>'
AWS_Secret_Access_Key='<※2>'
Default region name='<※3>'
注釈
- ※1:AWS_Access_Key_IDの値には「Alkano環境構築ソリューション - Wasabiオブジェクトストレージを設定する」で生成された「AccessKeyId」を入力してください。
- ※2:AWS_Secret_Access_Keyの値には「Alkano環境構築ソリューション - Wasabiオブジェクトストレージを設定する」で生成された「SecretAccessKey」を入力してください。
- ※3:Default region nameの値には「Alkano環境構築ソリューション - Pythonスクリプトを準備する」で指定した「wasabi_region」を入力してください。
前処理アイコン・予測アイコンを配置する¶
予測用データに対する前処理・予測をするアイコンを配置します。
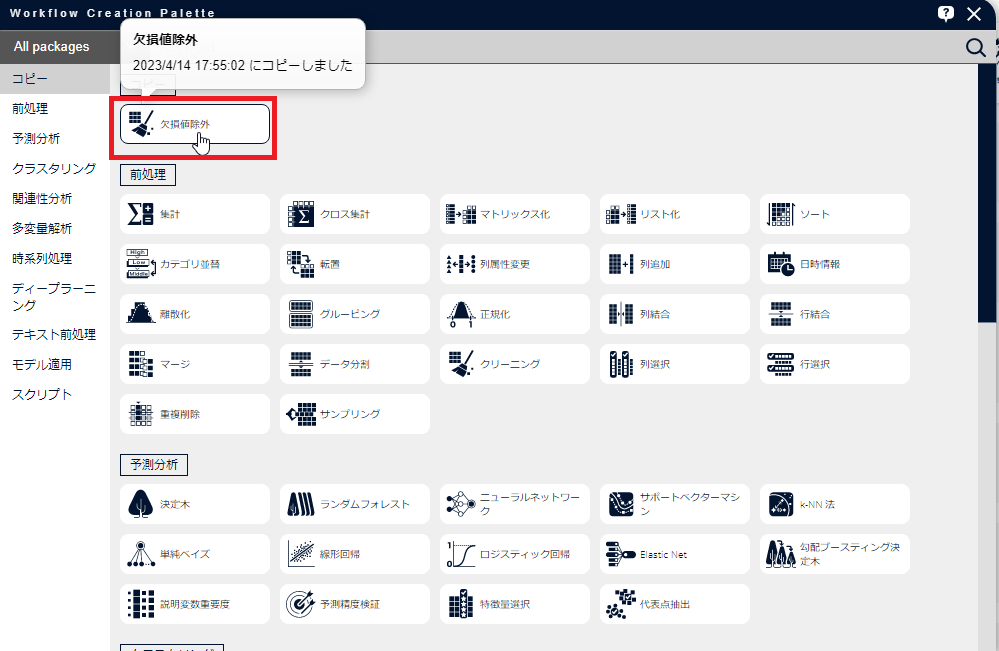
[欠損値除外]アイコンを右クリックし、[ノードをコピー]をクリックします。
[予測用データインポートアイコン]を右クリックし、[ノードを追加]をクリックします。
「コピー」の中に表示されている[欠損値除外]アイコンをクリックします。
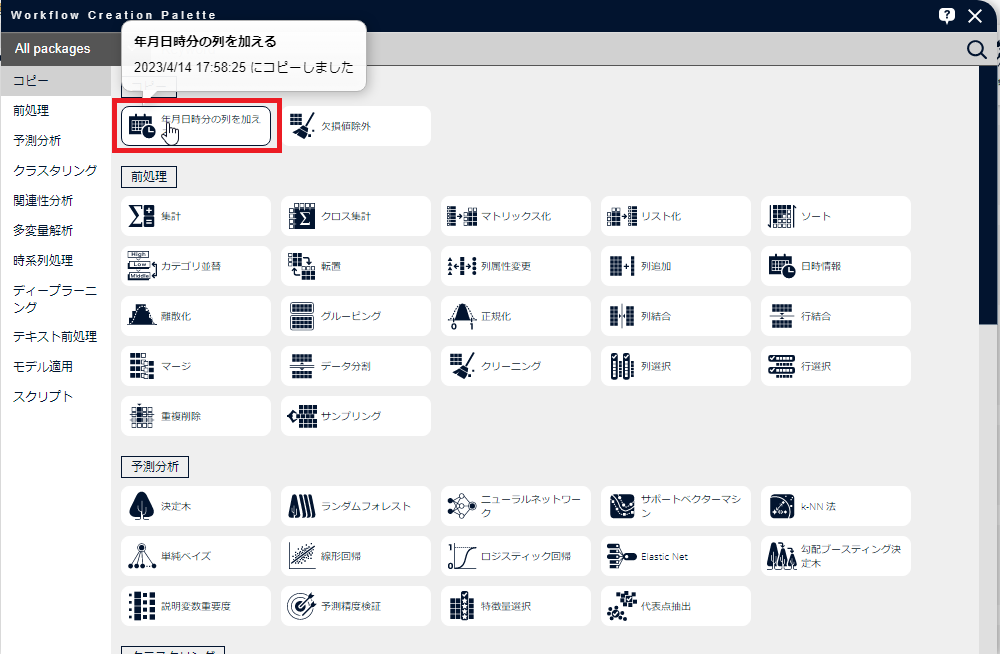
[年月日時分の列を加える]アイコンを右クリックし、[ノードをコピー]をクリックします。

[欠損値除外(1)]を右クリックし、[ノードを追加]をクリックします。

「コピー」の中に表示されている[年月日時分の列を加える]アイコンをクリックします。
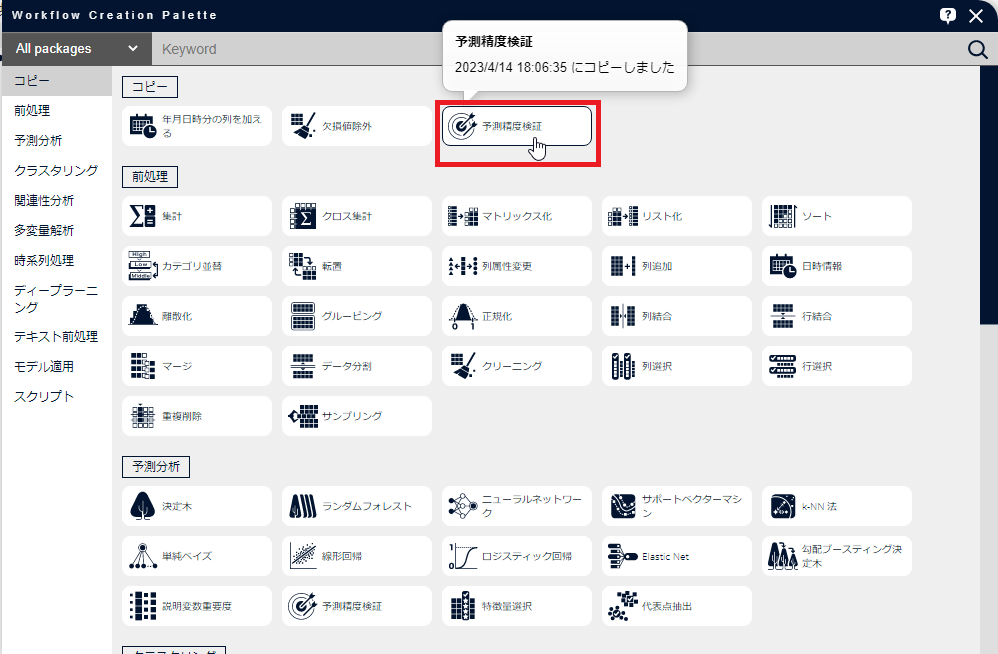
[予測精度検証]アイコンを右クリックし、[ノードをコピー]をクリックします。

[年月日時分の列を加える(1)]を右クリックし、[ノードを追加]をクリックします。

「コピー」の中に表示されている[予測精度検証]アイコンをクリックします。
[予測精度検証(1)]アイコンを右クリックし、[ノード名変更]をクリックします。

アイコンの名称を「予測結果」に変更し、シナリオ画面の余白部分をクリックします。

[勾配ブースティング決定木]アイコンを右クリックし、[接続リンクを追加]をクリックします。
[予測結果]アイコンをクリックし、接続リンクが追加されることを確認します。
REST API実行環境を準備する¶
REST API利用のための準備をする¶
REST APIを利用するにあたり「requests」ライブラリをインストールし、パッチを当てる必要があります。
「1.1.3.4. Alkanoの環境構築をする - 作業用ディレクトリを作成する」で作成した作業用ディレクトリに、REST APIドキュメントに含まれている「batch_tutorial\batch_tools.py」をコピーします。また、MSIPインストールディレクトリ(例:C:\MSIP)に「batch_tutorial\patch_for_batch_tools.js」をコピーします。
コマンドプロンプトを開き、以下のコマンドを実行します。
> cd C:\Alkano_Work > C:\MSIP\python\Scripts\activate > python -m pip install requests > cd C:\MSIP > node patch_for_batch_tools.js
アクセストークンを取得する¶
REST API実行に必要なアクセストークンを取得します。
「1.1.3.4. Alkanoの環境構築をする - 作業用ディレクトリを作成する」で作成した作業用ディレクトリにて、アクセストークンを取得するスクリプト「getAccessToken.py」を以下のとおり作成してください。
getAccessToken.py
from datetime import datetime from dateutil import tz import json from batch_tools import create_accesstoken url = "http://localhost:8080" username = "<ユーザー名>" password = "<パスワード>" targets = ["roles, core"] application_name = "external-application-1" expiration = datetime(<年>, <月>, <日>, tzinfo=tz.gettz("Asia/Tokyo")) # アクセストークンの有効期限を指定します。 accesstoken = create_accesstoken(url, username, password, targets, application_name, expiration) print(json.dumps(accesstoken, indent=2))
注釈
- 「username」・「password」には「Alkano/MSIPのインストール方法 - インストール」で入力した初期ユーザー名とパスワードを入力してください。
以下のコマンドを実行し、上で作成したスクリプトを実行します。
> cd C:\Alkano_Work > C:\MSIP\python\Scripts\activate > python getAccessToken.py
以下のようなコンソール出力が表示されることを確認し、"payload"の"value"の値(アクセストークン)を控えておきます。
{ ... "payload":{ ... "value":"xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" }, ... }
注釈
- アクセストークンの有効期限が切れた場合はスクリプト内のアクセストークンの有効期限を書き換えて上記手順を再度実行してください。
分析フローの実行・実行結果の取得・予測結果データファイルをWasabiに保存するスクリプトを作成する¶
- "Alkanoシナリオ実行"・"実行結果の取得"・"予測結果データファイルをWasabiに保存"を行うスクリプトを作成します(本構成ガイドでは、Wasabiにおける予測結果データファイルの配置先を「alkano-bucket/alkano-csv」としています)。
「1.1.3.4. Alkanoの環境構築をする - 作業用ディレクトリを作成する」で作成した作業用ディレクトリにて以下のスクリプト「prediction.py」を作成してください。
注釈
- 「accesstoken」には「1.1.3.6. 予測を定期実行する - アクセストークンを取得する」で控えておいたアクセストークンを入力してください。
- 「target_scenario_name」には「1.1.3.5. 学習モデルを作成する - シナリオを作成する」で入力したシナリオ名を入力してください。
- 「target_node_names」・「target_nodes_to_output_files」には「1.1.3.6. 予測を定期実行する - 前処理アイコン・予測アイコンを配置する」の手順11で設定したアイコン名を入力してください。
- 「output_dir」には予測結果データファイルを書き出すディレクトリ名を入力してください。
- 「作成したメタパラメータのID(メタパラメータ識別子)」には「1.1.3.6. 予測を定期実行する - メタパラメータを設定する」で控えておいたメタパラメータID(メタパラメータ識別子)を入力してください。
- このスクリプトは予測結果データファイルの配置先であるWasabiのリージョンが「ap-northeast-1」の場合です。
- 本スクリプトは動作確認用です。Wasabiへのファイル送信部分はCLI呼び出しの他に、APIで実施する方法もあります。
prediction.py
from batch_tools import (
get_scenario_resources,
run_scenario_resource,
wait_job,
get_result,
write_files,
)
import datetime
url = "http://localhost:8080"
accesstoken = "<作成したアクセストークン(例:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx)>"
target_scenario_name = "<シナリオ名(例:新しいシナリオ)>"
target_node_names = ["<実行するノード名(例:予測結果)>"]
target_nodes_to_output_files = ["<書き出すノード名(例:予測結果)>"]
output_dir = "<出力先ディレクトリ名(例:output)>"
datetime_now = datetime.datetime.now()
dirname = (datetime_now.utcnow() + datetime.timedelta(hours=9)).strftime('%Y-%m-%d-%H%M%S')
params = {
"<作成したメタパラメータのID(メタパラメータ識別子)(例:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx)>":{
"value": dirname,
"type": "string"
}
}
if __name__ == "__main__":
print("シナリオリソース一覧を取得")
resources = get_scenario_resources(url, accesstoken)
target_scenario_resource = [
resource
for resource in resources
if resource["payload"]["name"] == target_scenario_name
]
if len(target_scenario_resource) == 1:
print("シナリオを取得")
target_scenario_resource = target_scenario_resource[0]
print("シナリオを実行開始")
job = run_scenario_resource(url, accesstoken, target_scenario_resource, target_node_names, params)
job = wait_job(url, accesstoken, job)
print("シナリオの実行終了")
print("実行結果を取得")
result = get_result(
url,
accesstoken,
job,
)
print("実行結果を書出開始")
write_files(
url,
accesstoken,
result,
target_nodes_to_output_files,
output_dir,
)
print("実行結果を書出終了")
else:
print("同名のシナリオが無いか重複があります")
import subprocess
cmd = "aws s3 cp C://Alkano_Work/<出力先ディレクトリ名(例:output)> s3://alkano-bucket/alkano-csv --endpoint-url=https://s3.ap-northeast-1.wasabisys.com --recursive --exclude \"*\" --include \"<実行するノード名(例:予測結果)>.result.csv\""
proc = subprocess.run(cmd,shell=true)
タスクスケジューラでPythonスクリプトを自動実行する¶
上記Pythonスクリプトをタスクスケジューラで時間ごとに自動実行します。
タスクスケジューラを起動します。タスクバーの検索アイコンをクリックし、「task」と入力、[タスクスケジューラ]をクリックします。
[タスクの作成...]をクリックします。
「全般」タブの「名前」に任意の名前(例:シナリオ定期実行)を入力します。

[操作]タブを開き[新規]をクリックします。
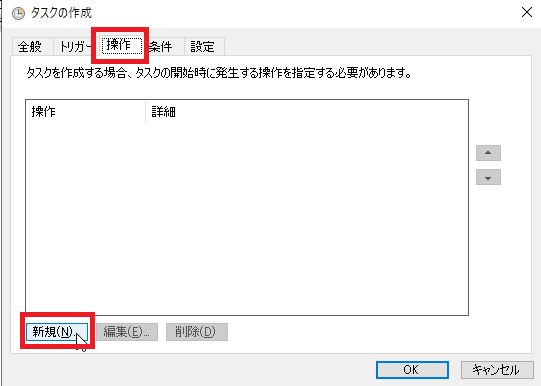
以下の値をそれぞれ入力し[OK]をクリックします。
項目 値 プログラム/スクリプト(P): C:\MSIP\python\Scripts\python.exe 引数の追加(オプション)(A): Pythonスクリプト名(例:prediction.py) 開始(オプション)(T:) Pythonスクリプトがあるファイルパス(例:C:\Alkano_Work) 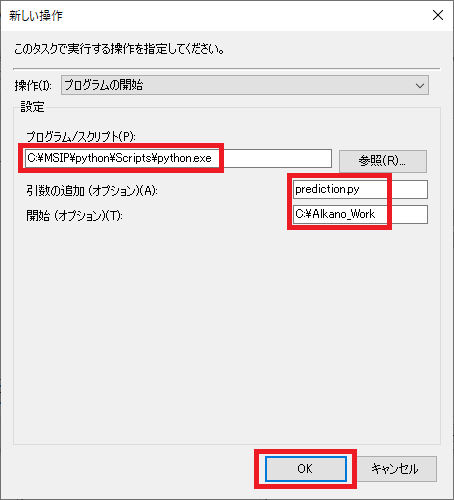
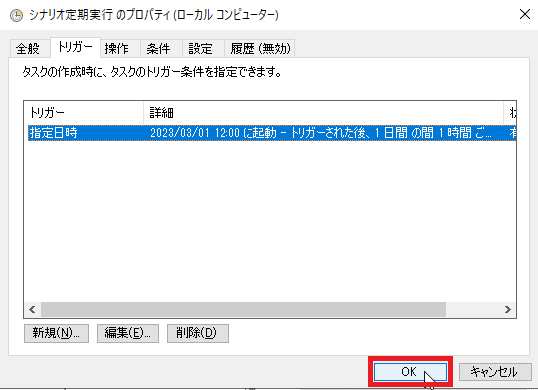
[トリガー]タブを開き、[新規]をクリックします。
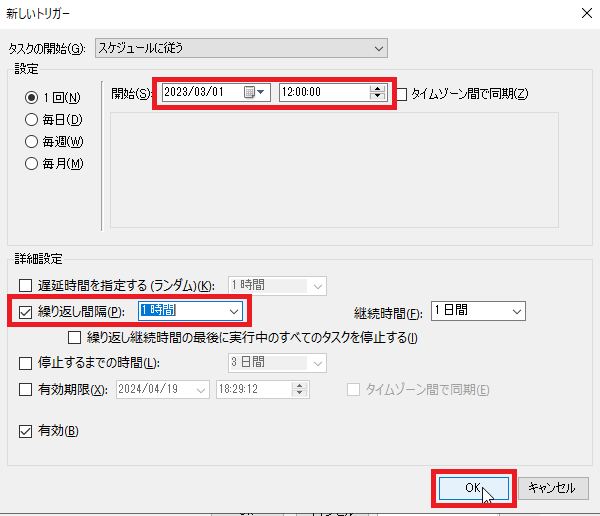
「設定」画面にて、自動実行を始めたい時間(例:2023/03/01 12:00:00)、また「詳細設定」の「繰り返し間隔」にて繰り返したい時間間隔(例:1時間)を入力し、チェックを入れ[OK]をクリックします。
[OK]をクリックし、タスクスケジューラを閉じます。
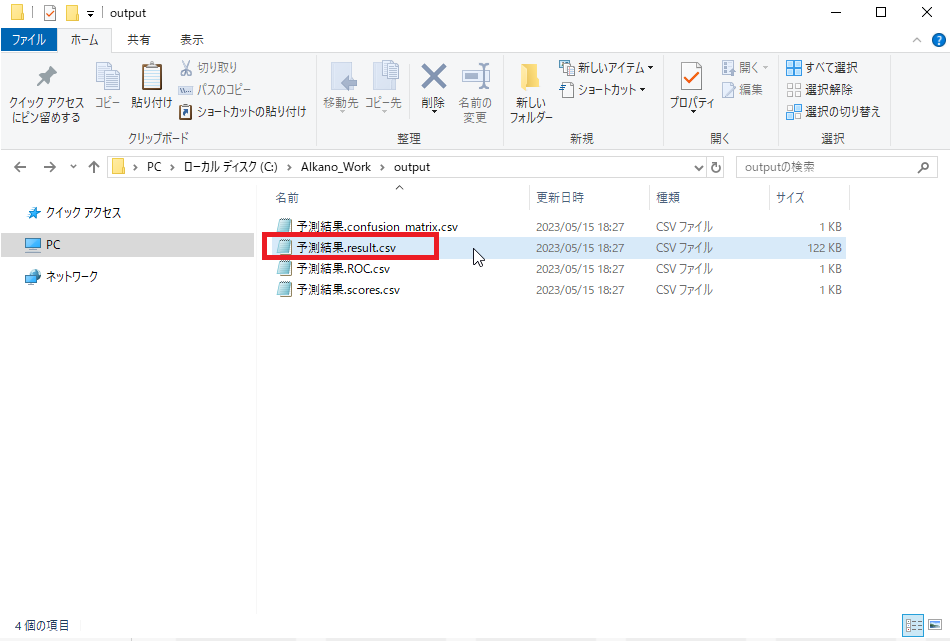
「1.1.3.4. Alkanoの環境構築をする - 作業用ディレクトリを作成する」で作成した作業用ディレクトリ下に「output/予測結果.result.csv」が作成されていることを確認してください。これが予測用データに対する予測結果です。
予測結果データファイルがWasabiに(本構成ガイドでは、予測結果データファイルの配置先は「alkano-bucket/alkano-csv」です)あることを確認してください。