1.1.3.5. 学習モデルを作成する¶
本項では、Alkanoを使用した時系列予測の学習モデルを作成する手順について記載します。
以下、Alkanoをインストールするサーバーインスタンスのことを「Alkanoサーバー」と呼びます。
また、以下の手順は作業端末で行います。
前提条件を確認する¶
あらかじめ、これまでの「1.1.3.4. Alkanoの環境構築をする」に記載されているすべての作業が完了していることを確認してください。
また、作業端末内に、学習データ「通過人数.csv」が保存されていることを確認してください。
なお、本項中の設定値の「< >」の表記については、利用の環境により各自入力いただく箇所となります("<"から">"までを設定値に置き換えてください)。
MSIPへのアクセス方法を確認する¶
注釈
- MSIPのバージョンが"1.8.0"、Alkanoのバージョンが"1.2.0"であればhttps接続が可能です。
- Alkanoサーバーに接続できる作業端末のブラウザーにて、「http://<AlkanoサーバーのIPアドレス>:8080/login」にアクセスします。
- 「1.1.3.4. Alkanoの環境構築をする - MSIPサービスを起動する」の「4.」と同様の手順でログインします。
ワークスペース、プロジェクト、シナリオを作成する¶
ワークスペースを作成する¶
MSIPへログインし、ワークスペースの作成画面を開きます。
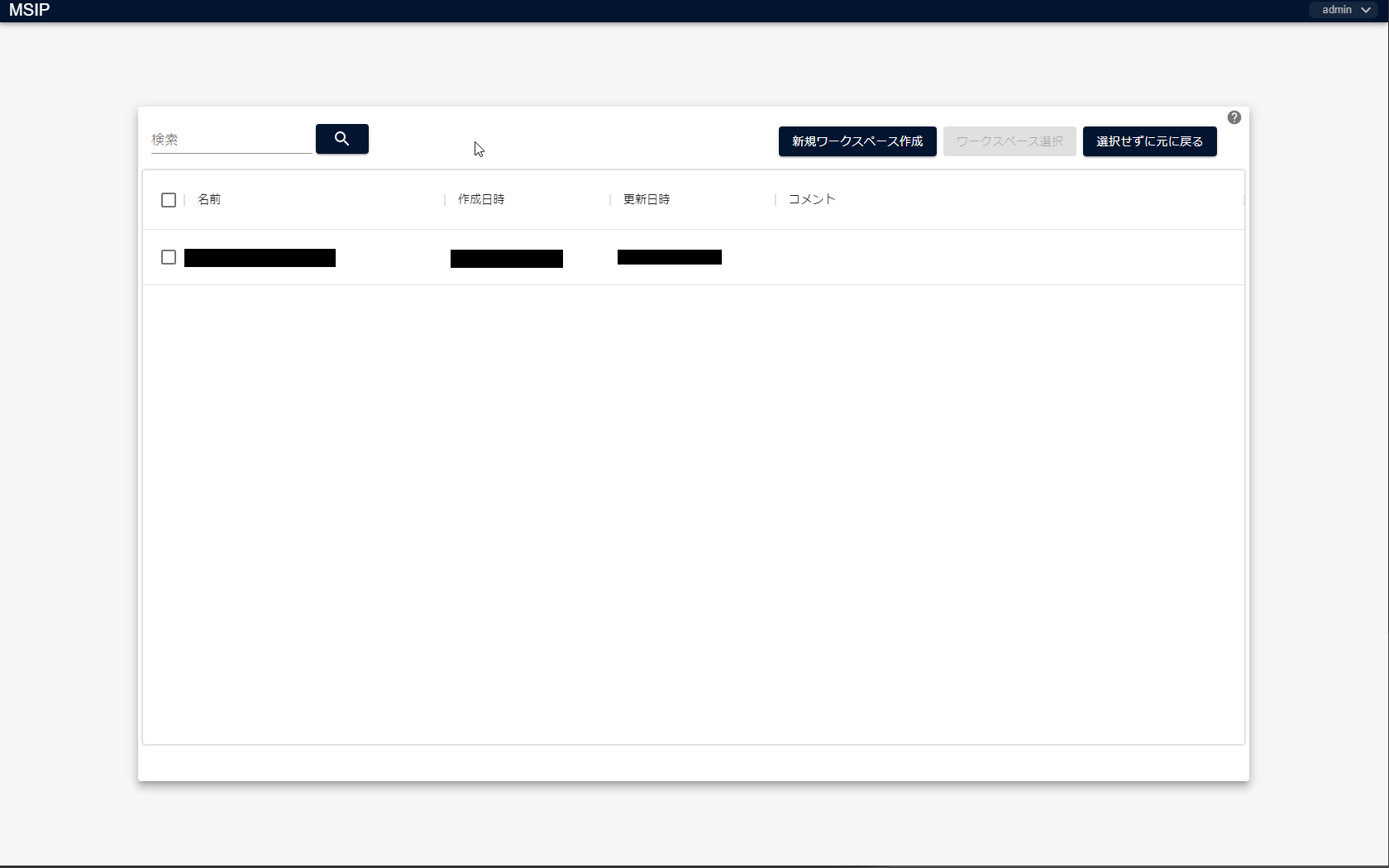
[新規ワークスペース作成]をクリックすると、「ワークスペース作成」画面が表示されます。名前欄に任意のワークスペース名(例:新しいワークスペース)を入力し、[作成]をクリックします。
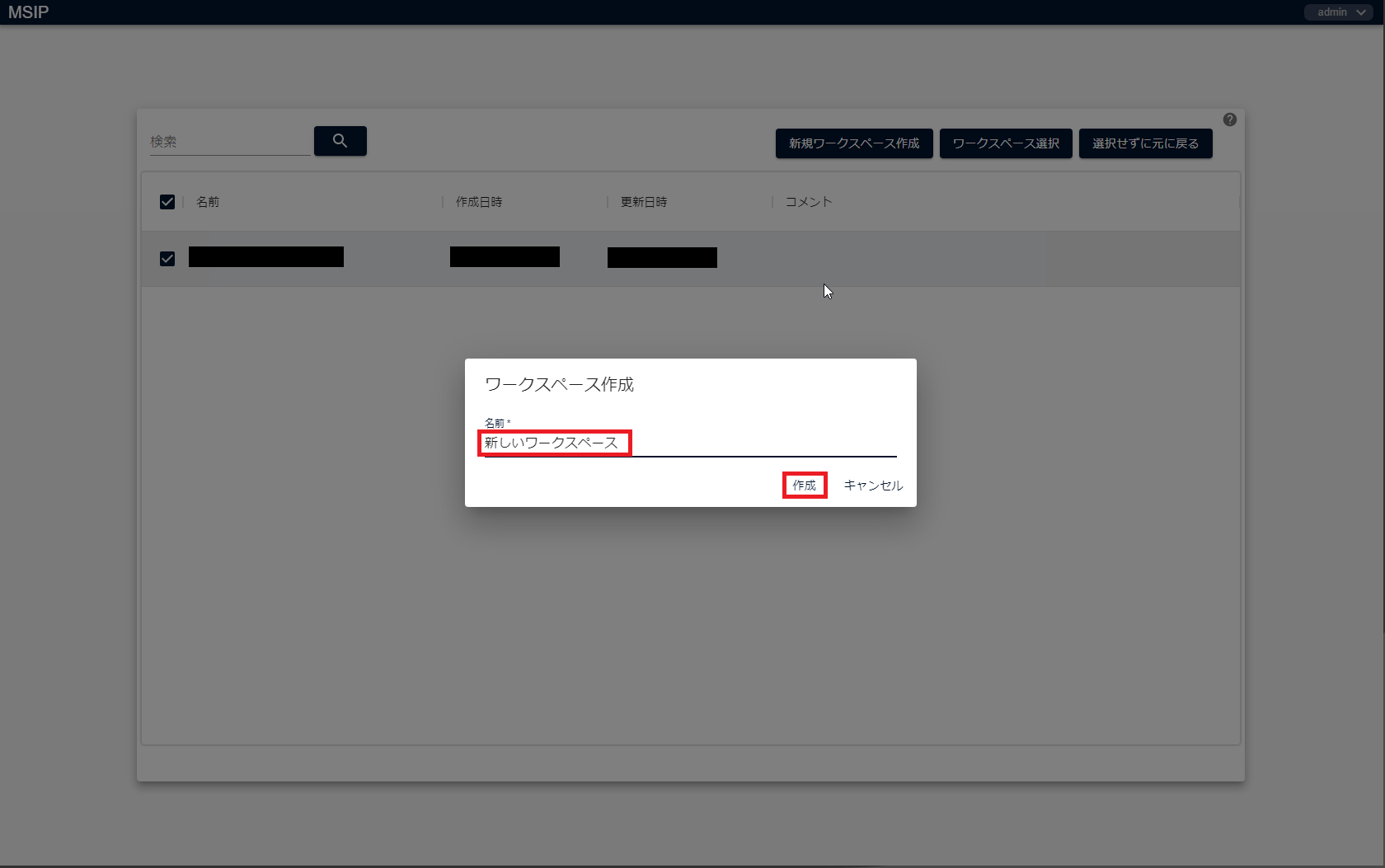
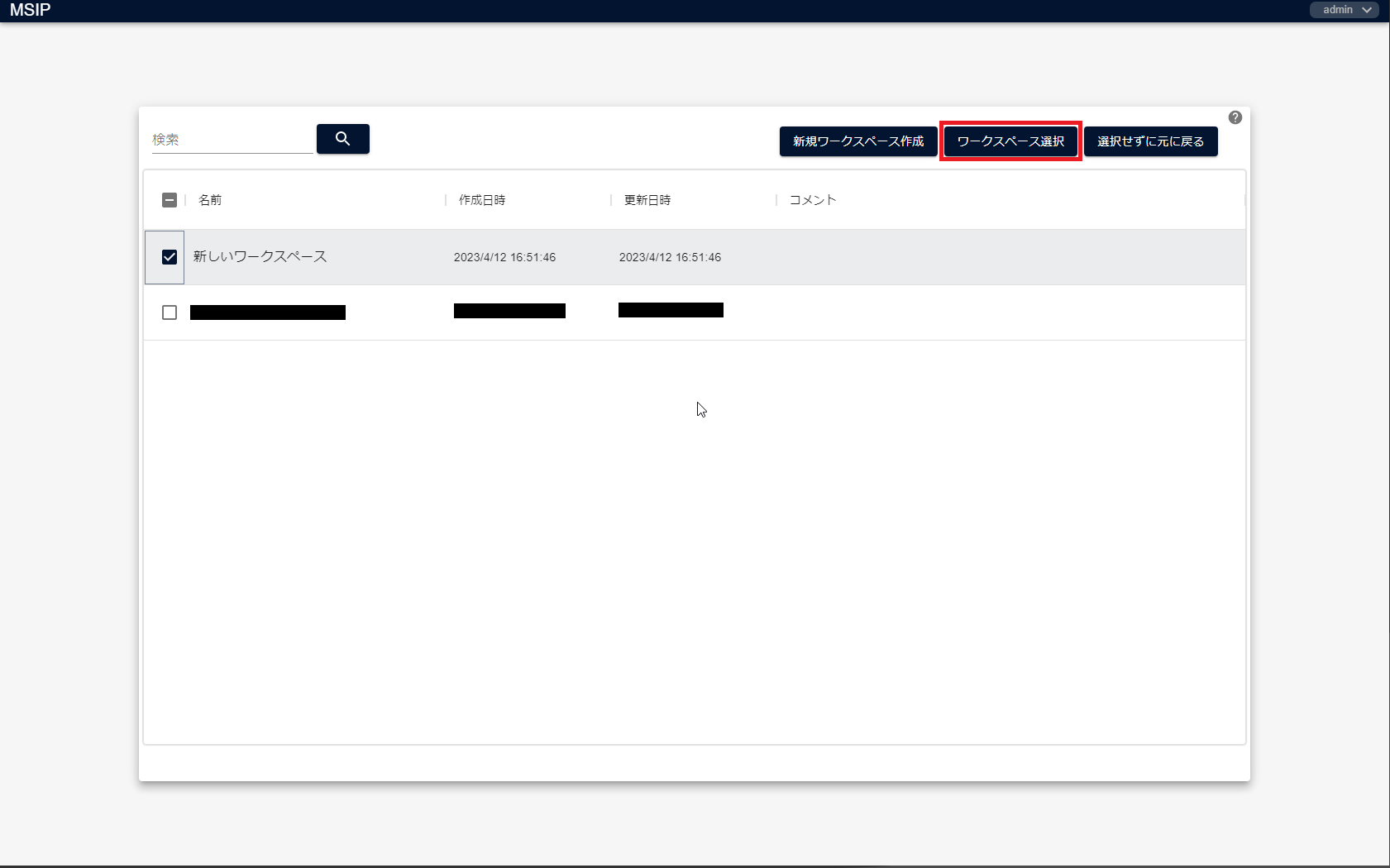
ワークスペースが作成されることを確認し、作成したワークスペースにチェックを入れて右上の[ワークスペース選択]をクリック、または作成したワークスペースをダブルクリックします。
作成したワークスペースが表示されることを確認します。
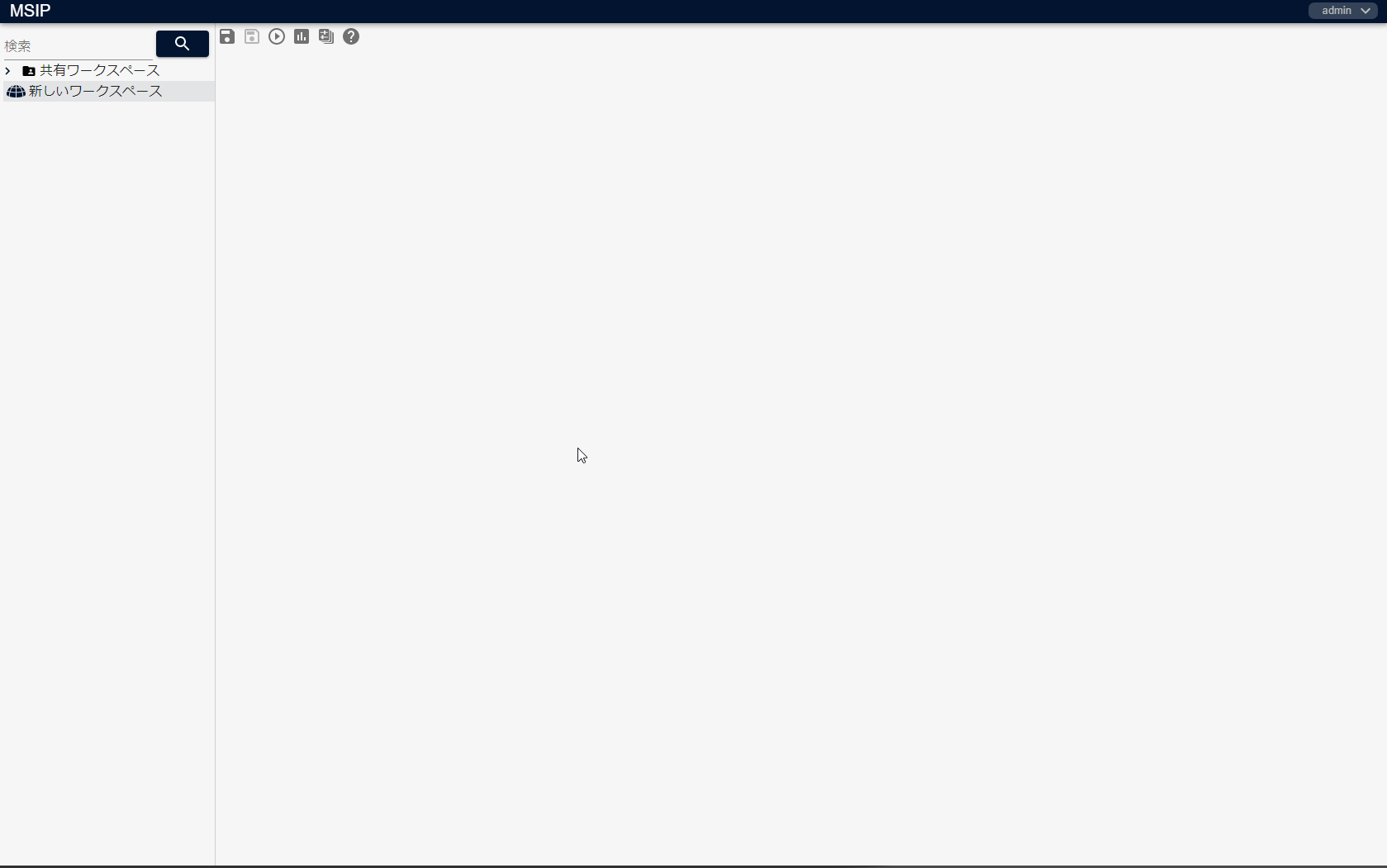
プロジェクトを作成する¶
作成したワークスペース名の上で右クリックし、[プロジェクト作成]をクリックします。
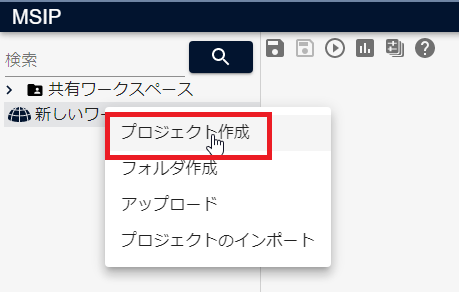
プロジェクトが作成されるので、任意のプロジェクト名(例:新しいプロジェクト)を入力し、Enterキーを押し確定します。
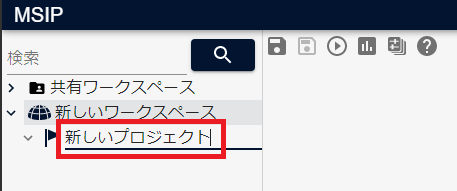
シナリオを作成する¶
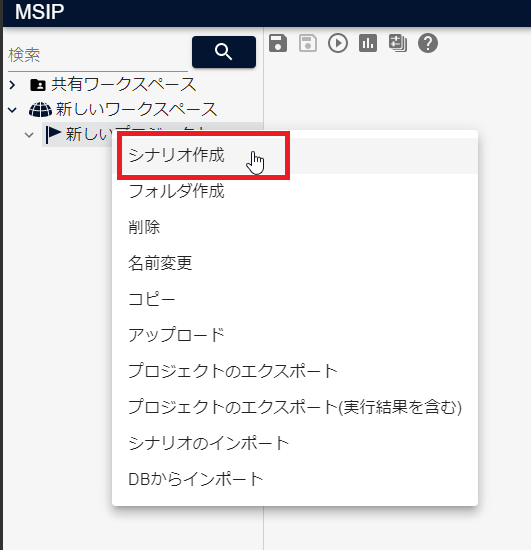
作成したプロジェクト名の上で右クリックし、[シナリオ作成]をクリックします。
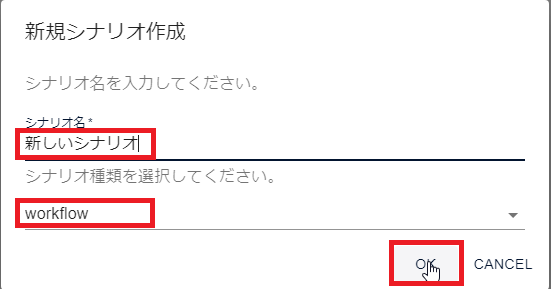
「新規シナリオ作成」画面が表示されるので、シナリオ名の欄に任意のシナリオ名(例:新しいシナリオ)を入力、シナリオ種類の欄から[workflow]を選択し[OK]をクリックします。
シナリオが作成され、画面右のシナリオエリアに作成した空のシナリオが表示されます。
作成するシナリオの全体像を確認する¶
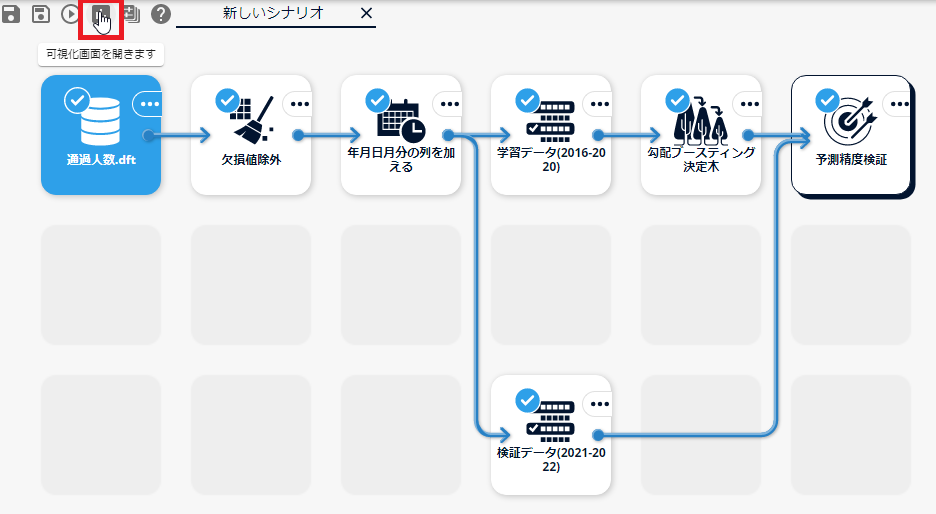
本構成ガイドで作成するシナリオの全体像は以下の図のとおりです。
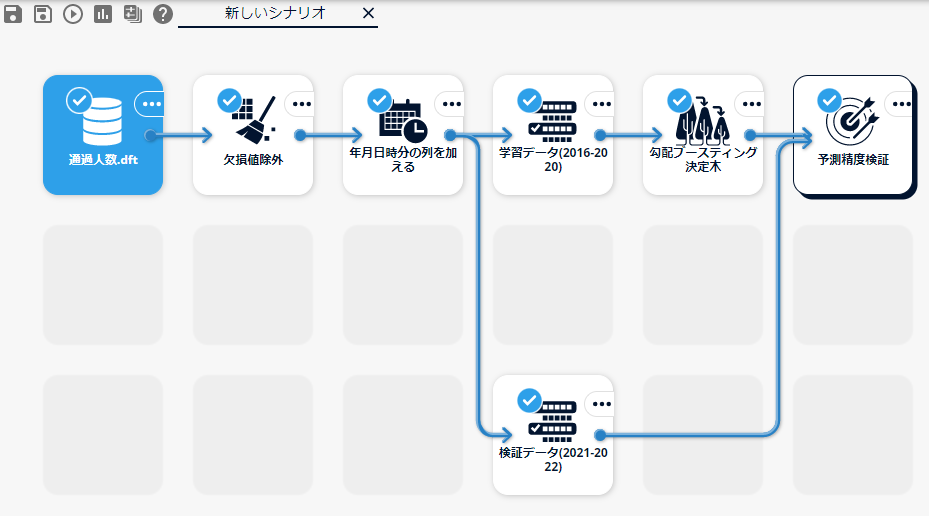
各アイコンの説明については以下の表のとおりです。 実際に学習モデルを作成する際は、ご自身の行いたい予測に合わせて適宜アイコンを配置してください。 アイコンの詳細は「MSIPマニュアル(http://<AlkanoサーバーのIPアドレス>:8080/help/index.html)」を参照してください。
アイコン 説明 通過人数.dft 学習データと検証データが含まれる1つの入力ファイルです。 欠損値除外 欠損値が含まれていると適切な学習ができないため、学習データ・検証データのうち、欠損値が含まれている行を削除します。 年月日時分の列を加える 日時情報は「2016/8/1 5:00」のような形式では説明変数として扱うことができないため、「年」・「月」・「日」・「時」・「分」の各列に分割します。 学習データ(2016-2020) 「通過人数.dft」から学習データの期間(2016/8/1-2020/12/31)を抜き出します。 検証データ(2021-2022) 「通過人数.dft」から検証データの期間(2021/1/1-2022/8/31)を抜き出します。 勾配ブースティング決定木 「勾配降下法」と「アンサンブル学習」と「決定木」の3つの手法を組み合わせた機械学習の手法である「勾配ブースティング決定木」の処理を行います。 予測精度検証 作成した学習モデルを検証データに適用し、予測値と学習モデルの精度を出力します。
学習データ・検証データをアップロードする¶
学習データ・検証データをMSIPにアップロードし、シナリオ内に配置します。
MSIPへのアップロードの際は、「データをサーバーにアップロードする」、「データ形式を指定してインポートする」という2つの作業をします。
注釈
- 本構成ガイドでは学習データ・検証データを「通過人数.dft」として説明しています。
作成したプロジェクト名の上で右クリックし、[アップロード]をクリックします。
「データアップロード」画面が表示されるので、[ファイルを選択]ボタンをクリックします。

分析に用いる学習データ・検証データであるcsvデータを選択すると、「データアップロード」画面に戻るので[OK]をクリックします。

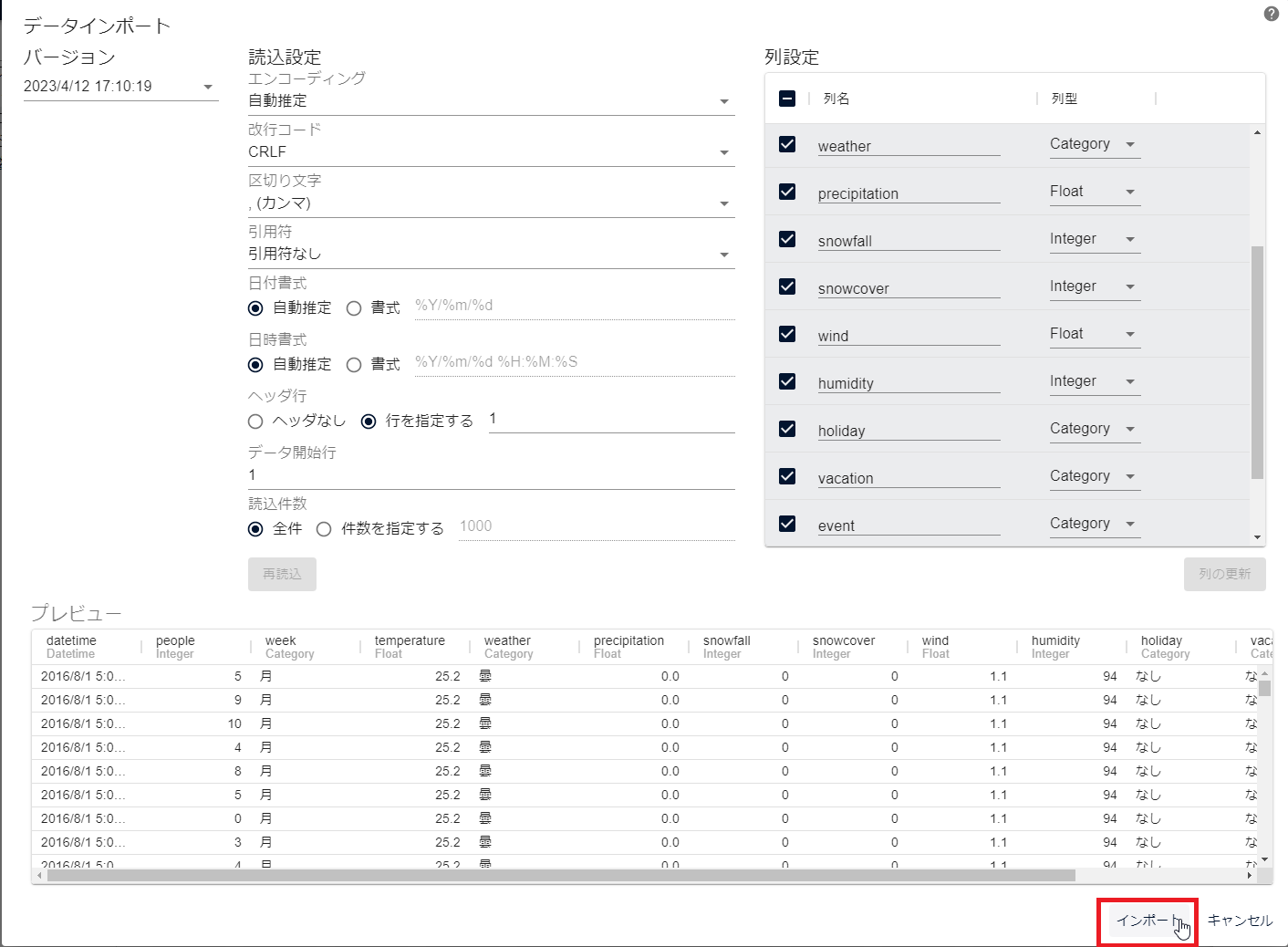
しばらく待つと「データインポート」画面が表示されるので、画面右の「列設定」にて列型が間違っていないかを確認し、[インポート]をクリックします。
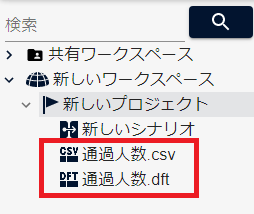
元の画面に戻るので、csvファイルとdftファイルが追加されていることを確認します。
注釈
- シナリオの中ではdftファイルを利用します。csvファイルは使いません。
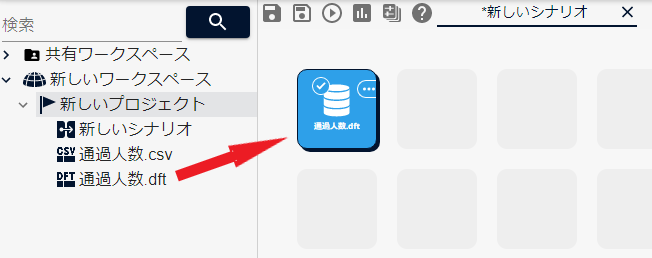
アップロードしたdftファイルをシナリオへドラッグアンドドロップして配置します。
前処理を実行する¶
学習モデルの作成が適切に行えるよう、インポートしたデータに対して前処理を行う必要があります。
本項では、データの前処理を行うアイコンの設定手順を記載します。
欠損値を除外する(クリーニングアイコン)¶
インポートしたデータから欠損値のある行を除外します。
アップロードした[通過人数.dft]アイコンを右クリックし、[ノードを追加]をクリックします。
[クリーニング]をクリックします。
[クリーニング]アイコンを右クリックし、[ノード名変更]をクリックします。
アイコンの名称を「欠損値除外」に変更し、シナリオ画面の余白部分をクリックします。

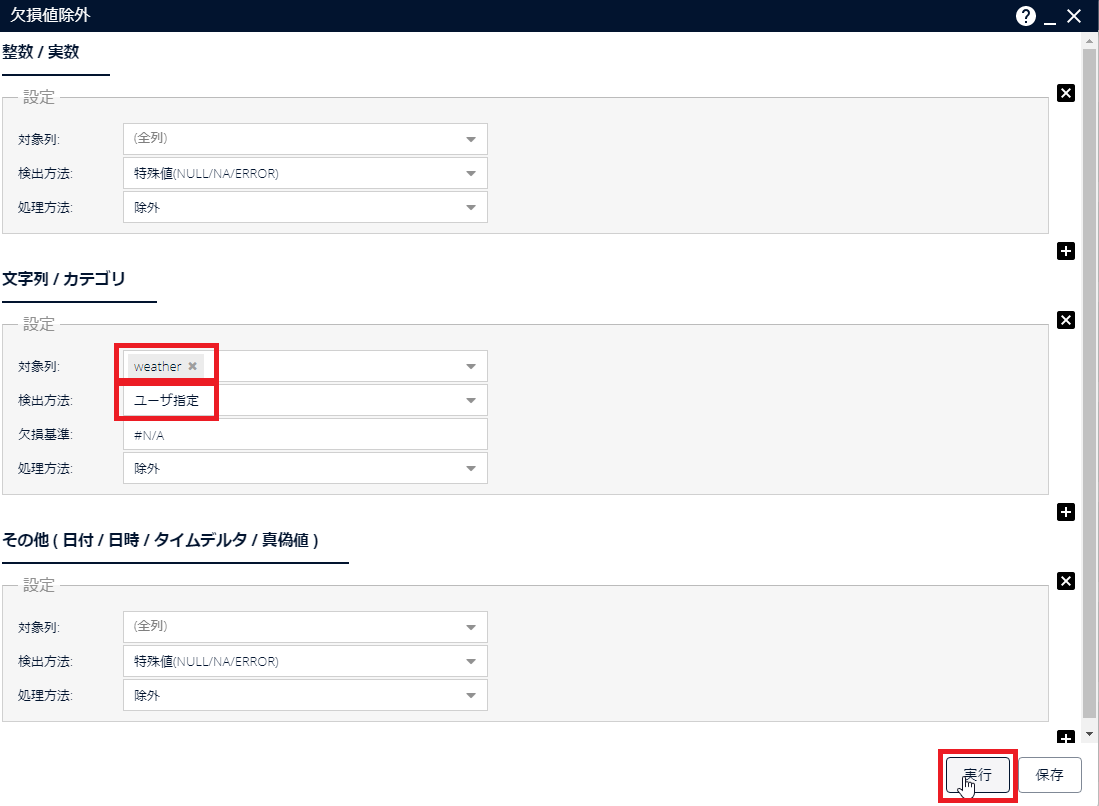
[欠損値除外]アイコンをダブルクリックして、パラメーター画面を開きます。各列の適切でないデータが入っている行が除外されるようにパラメーターを設定し、[実行]をクリックします(ここでは「weather」列に入っている値が「#N/A」である行を除外するようにパラメーターを設定しています)。
パラメーター画面を閉じ、実行が終了するまで待ちます(実行が終了すると画面左下に、以下のようなコメントが表示されます)。

年月日時分列を加える(日時情報アイコン)¶
インポートしたデータに[年][月][日][時][分]の列を追加します。
[欠損値除外]アイコンを右クリックし、[ノードを追加]をクリックします。
[日時情報]アイコンをクリックします。
[日時情報]アイコンを右クリックし、[ノード名変更]をクリックします。
アイコンの名称を「年月日時分の列を加える」に変更し、シナリオ画面の余白部分をクリックします。
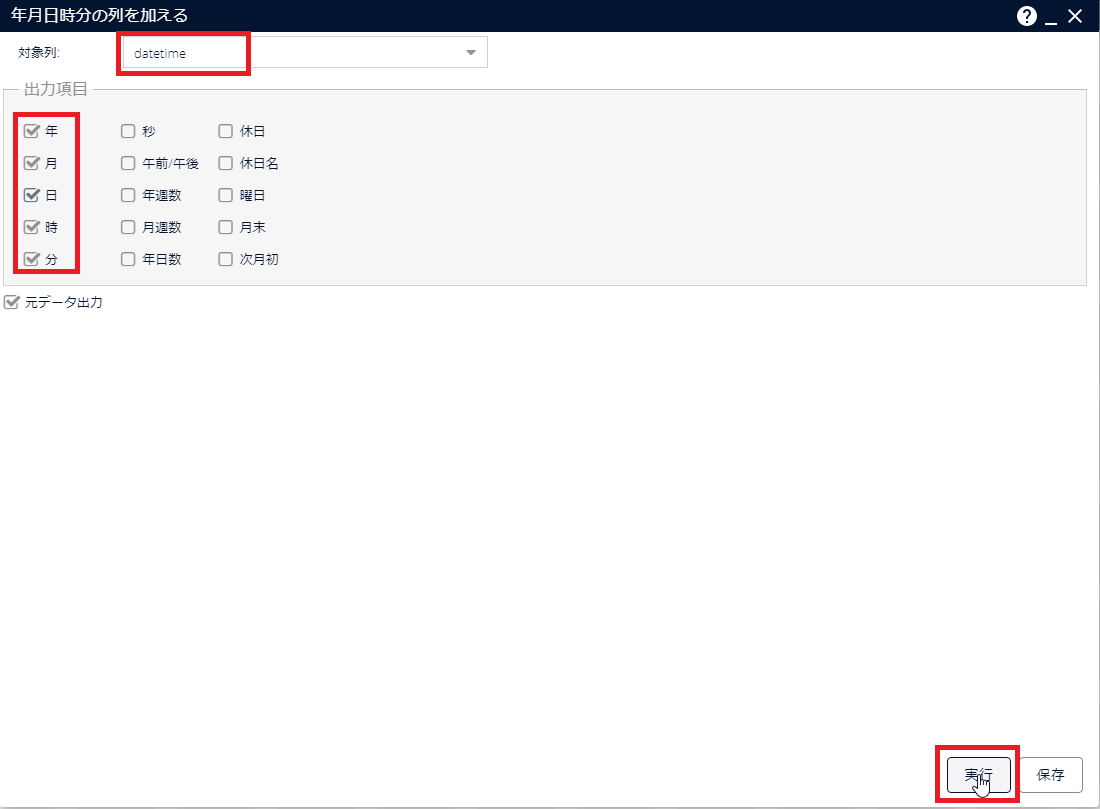
[年月日時分の列を加える]アイコンをダブルクリックして、パラメーター画面を開きます。対象列から[datetime]を選択し、[年][月][日][時][分]にチェックを入れ、[実行]をクリックします。
パラメーター画面を閉じ、実行が終了するまで待ちます。
学習データと検証データに分ける(行選択アイコン・行結合アイコン)¶
インポートしたデータを学習データと検証データに分割します。
本項では、期間が「2016/8/1~2022/8/31」である元データを以下のとおり分割します。
- 学習データ: 2016/8/1~2020/12/31
- 検証データ: 2021/1/1~2022/8/31
[年月日時分の列を加える]アイコンを右クリックし、[ノードを追加]をクリックします。

[行選択]アイコンをクリックします。
[行選択]アイコンを右クリックし、[ノード名変更]をクリックします。
アイコンの名称を「学習データ(2016-2020)」に変更し、シナリオ画面の余白部分をクリックします。
[学習データ(2016-2020)]アイコンをダブルクリックして、パラメーター画面を開きます。「年」の列の値は、2016~2020である行が選択されるように以下のとおりパラメーターを設定し、[実行]をクリックします。
列名 列型 条件式 年 integer <= 2020 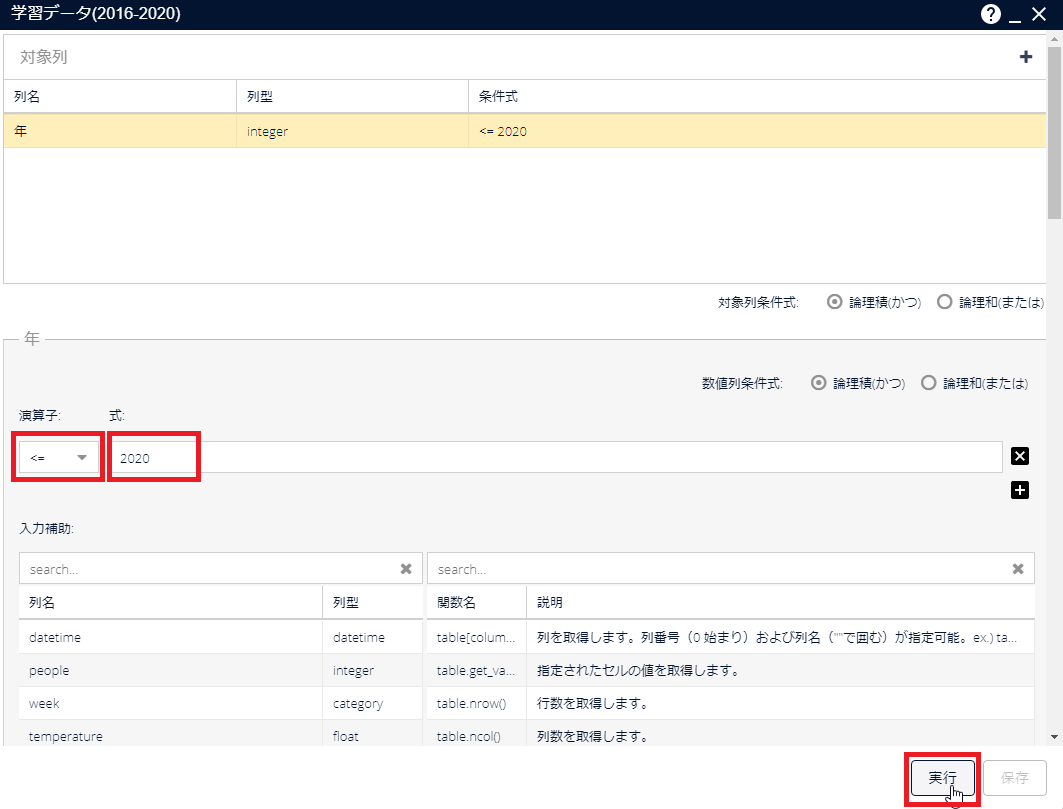
パラメーター画面を閉じ、実行が終了するまで待ちます。
[年月日時分の列を加える]アイコンを右クリックし、[ノードを追加]をクリックします。
[行選択]アイコンをクリックします。
[行選択]アイコンを右クリックし、[ノード名変更]をクリックします。
アイコンの名称を「検証データ(2021-2022)」に変更し、シナリオ画面の余白部分をクリックします。
[検証データ(2021-2022)]アイコンをダブルクリックして、パラメーター画面を開きます。「年」の列の値が2021~2022である行が選択されるように以下のとおりパラメーターを設定し、[実行]をクリックします。
列名 列型 条件式 年 integer >= 2021 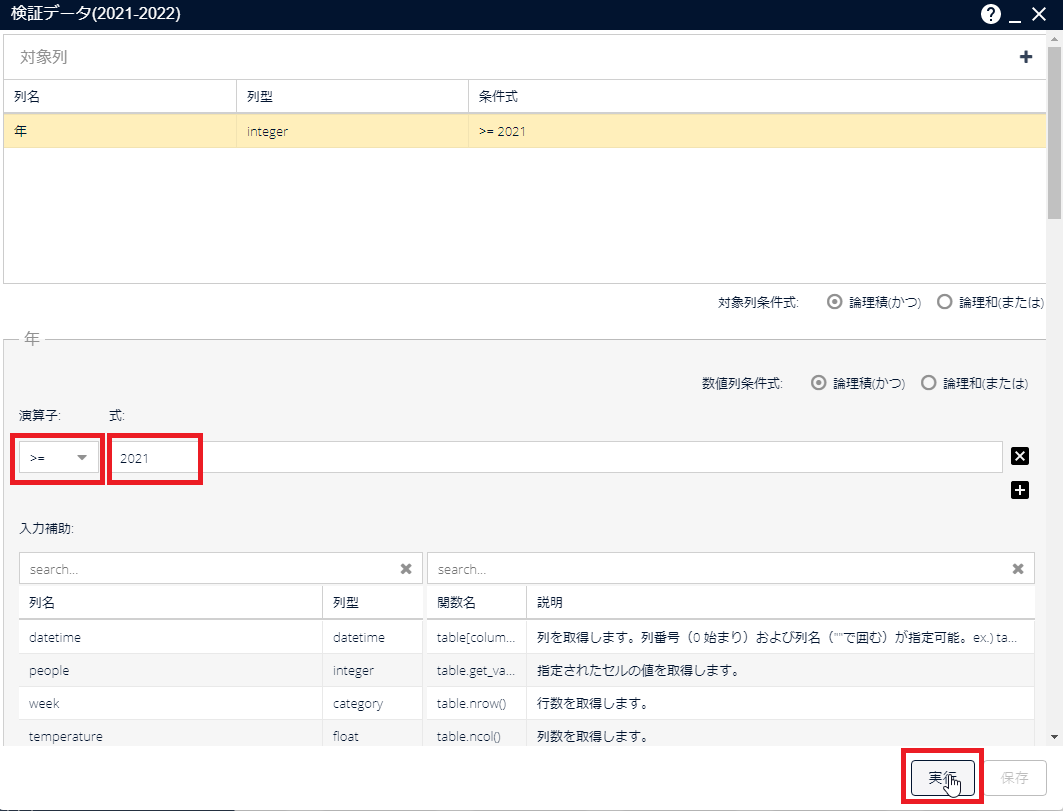
パラメーター画面を閉じ、実行が終了するまで待ちます。
学習モデルを作成・検証する¶
前処理を行ったデータを用いて学習モデルを作成し、学習モデルの予測精度を確認します。
学習モデルを作成する(勾配ブースティング決定木アイコン)¶
勾配ブースティング決定木を用いて学習モデルを作成します。
以下の手順は学習データにのみ行います。
[学習データ(2016-2020)]アイコンを右クリックし、[ノードを追加]をクリックします。
[勾配ブースティング決定木]アイコンをクリックします。
[勾配ブースティング決定木]アイコンをダブルクリックして、パラメーター画面を開きます。
パラメーター画面にて、目的変数と説明変数(本構成ガイドでは目的変数は「people」、説明変数は「week」、「temperature」など)を指定します。また、学習のパラメーターも併せて設定し、[実行]をクリックします。
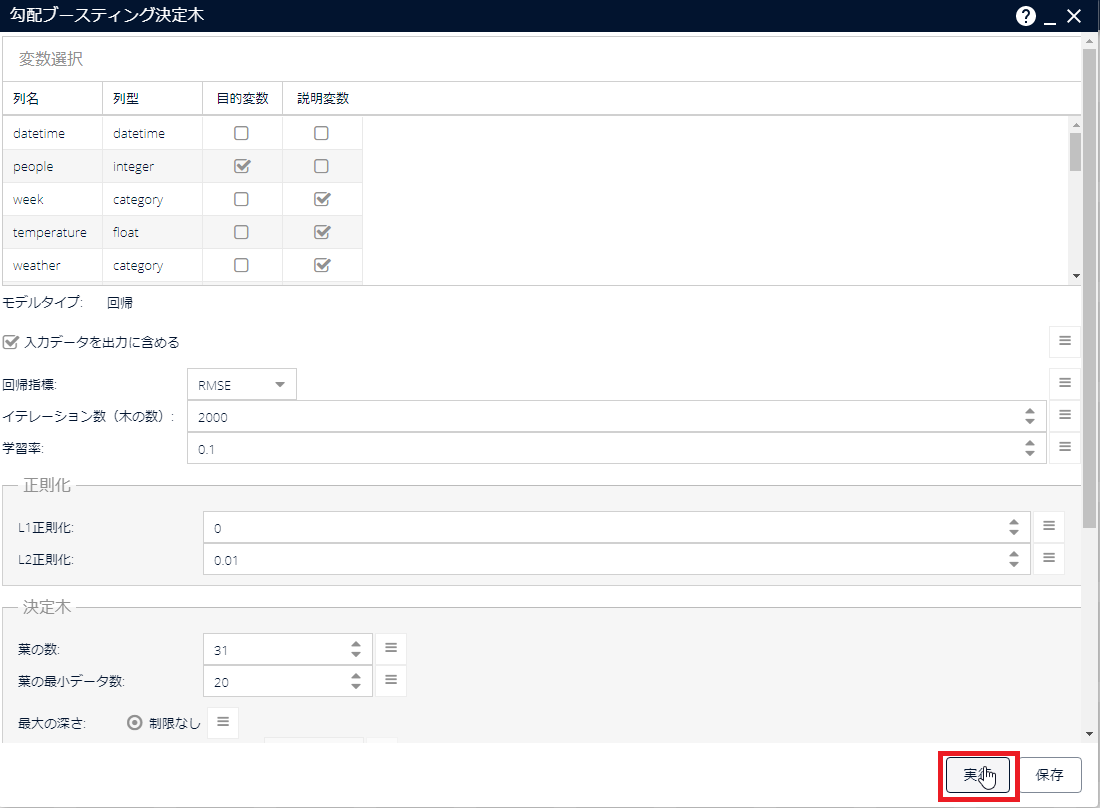
パラメーター画面を閉じ、実行が終了するまで待ちます。
学習モデルを評価する(予測精度検証)¶
作成した学習モデルを評価するため予測精度を出力します。
[勾配ブースティング決定木]アイコンを右クリックし、[ノードを追加]をクリックします。

[予測精度検証]アイコンをクリックします。
[検証データ(2021-2022)]アイコンを右クリックし、[接続リンクを追加]をクリックします。
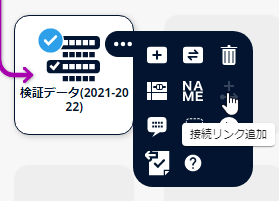
[予測精度検証]アイコンをクリックします。
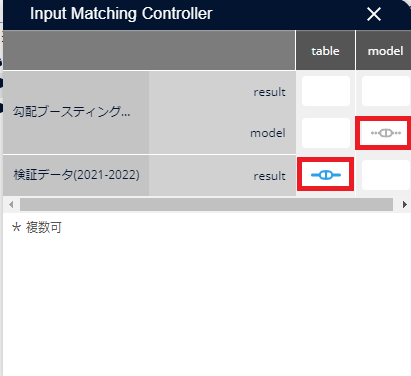
[予測精度検証]アイコンを右クリックし、[インプット設定]をクリックします。

「予測精度検証」アイコンに入力するデータを選択します。「table」列には「検証データ(2021-2022)」の[result]を、「model」列には「勾配ブースティング決定木」の[model]をそれぞれ選択し、シナリオ画面の余白部分をクリックします。
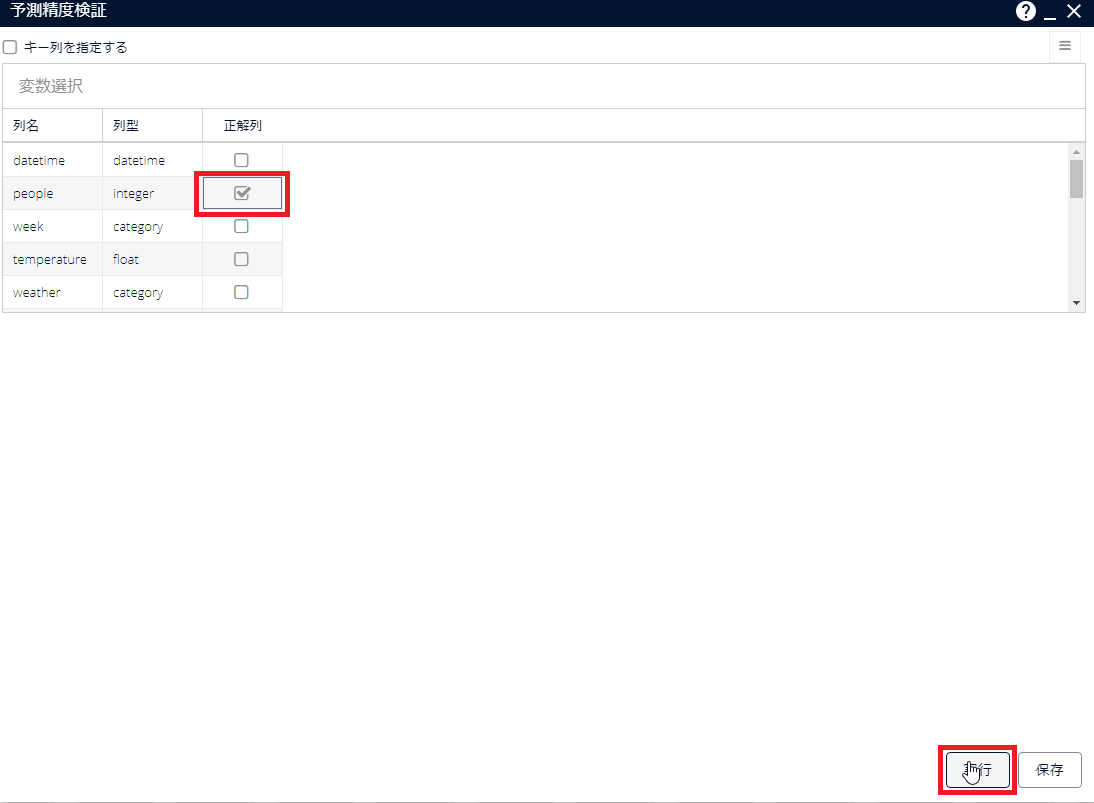
[予測精度検証]アイコンをダブルクリックして、パラメーター画面を開きます。「正解列」にて目的変数を選び、[実行]をクリックします。
パラメーター画面を閉じ、実行が終了するまで待ちます。
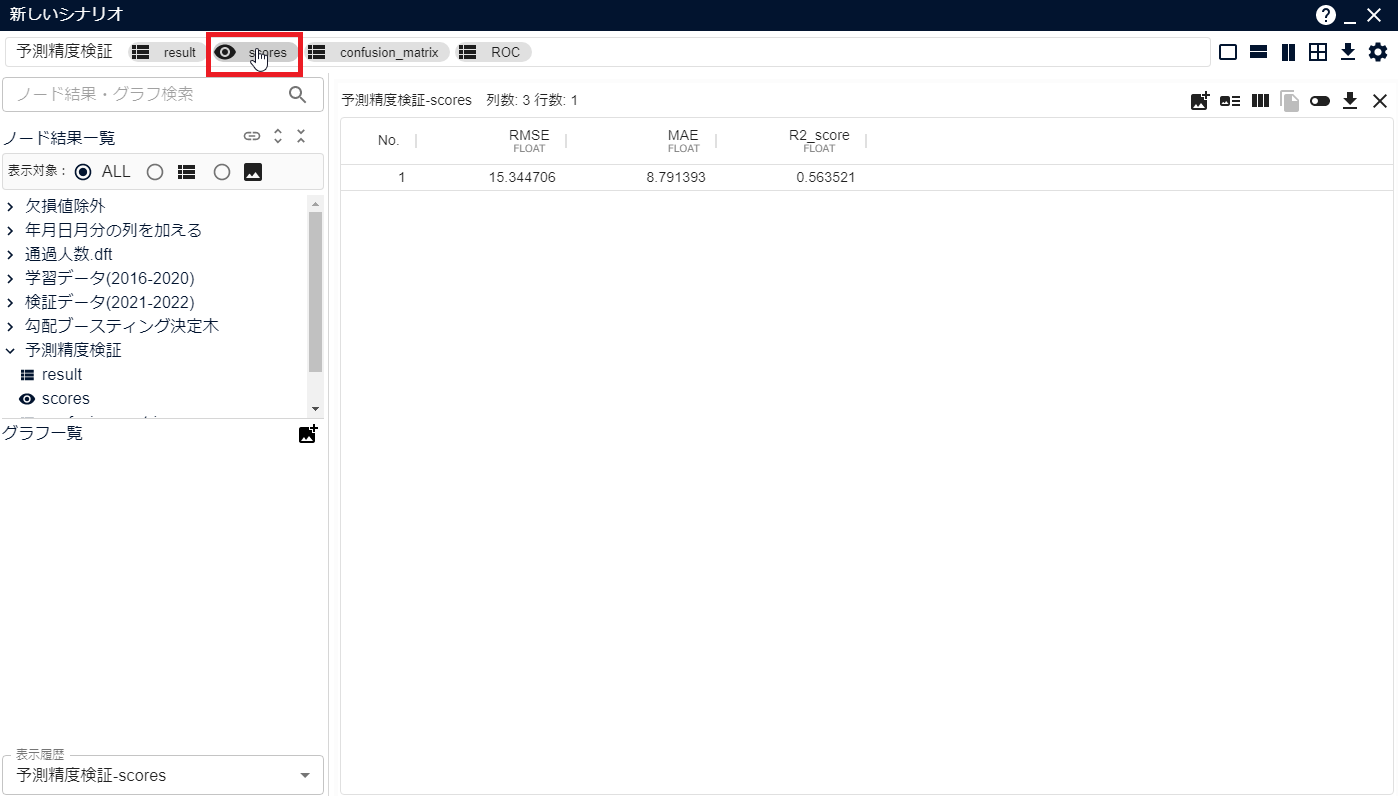
実行が終了したら、[予測精度検証]アイコンを選択した状態で[可視化画面を開きます]をクリックして可視化画面を開きます。
可視化画面内の[scores]をクリックし、予測精度を確認します。
注釈
- scoresのうち、たとえばR2_scoreは決定係数を表しており、予測値が実測値に比べてどれだけ近いかを客観的に示す指標です。一般的に0.5以上で良い精度とされています。実際には、データの前処理・予測分析アイコンのハイパーパラメーターなどの改良と予測結果の評価を繰り返しながら予測精度を高めていきます。