モニタリング¶
メニューの概要¶
概要¶
監視対象の死活確認、リソース不足
各設備の統計情報を確認することによるキャパシティ管理
故障発生状況の記録
メニューの特徴¶
機能一覧¶
本メニューでは以下の機能をご提供いたします。
項番 |
機能 |
内容 |
|---|---|---|
1 |
各種リソースからモニタリングに必要なデータを収集し、一定期間蓄積します。 |
|
2 |
お客さまがスクリプト等で収集したデータをモニタリングサーバーに蓄積できます。 |
|
3 |
モニタリングによって収集・蓄積したデータをグラフで表示できます。 |
|
4 |
各種リソースで収集したデータが設定した閾値を超過した際にアクションを実行できます。 |
|
5 |
アラーム設定を一覧で表示し、確認できます。 |
|
6 |
アラームの変更及び閾値超過の履歴を確認できます。 |
|
7 |
APIを利用して各種操作ができます。 |
|
8 |
ダッシュボード ※アドバンスドプランのみ |
複数リソースのモニタリングデータを1つの画面でまとめて確認できます。 |
9 |
データダウンロード ※アドバンスドプランのみ |
蓄積されているモニタリングのデータをダウンロードできます。 |
各機能の説明¶
1. データ収集・蓄積¶
各種リソースから監視項目に該当するデータを自動的に収集します。
収集されたデータはシステム上に蓄積され、後述のグラフ表示機能で利用できます。
データの蓄積期間は、ベーシックプランでは32日間(当日含む)です。アドバンスドプランでは397日間(当日含む)に延長可能です。
サーバーインスタンス コンピュート¶
メーター |
メーター表示名 |
メーター名 |
単位 |
収集元及び判定方法 |
備考 |
監視間隔 |
|---|---|---|---|---|---|---|
CPU使用率 ※1 |
CPU Utilization |
nova.cpu.utilization.percents |
percent |
サーバーインスタンスが起動しているHypervisor上で収集 |
監視間隔内の平均値を算出 |
5分 |
ディスク読取バイト数 |
Disk Read Bytes |
nova.disk.read.bytes |
byte |
サーバーインスタンスが起動しているHypervisor上で収集 |
監視間隔内の合計値を算出 |
5分 |
ディスク書込バイト数 |
Disk Write Bytes |
nova.disk.write.bytes |
byte |
サーバーインスタンスが起動しているHypervisor上で収集 |
監視間隔内の合計値を算出 |
5分 |
ディスク読取回数 |
Disk Read Requests |
nova.disk.read.requests |
request |
サーバーインスタンスが起動しているHypervisor上で収集 |
監視間隔内の合計値を算出 |
5分 |
ディスク書込回数 |
Disk Write Requests |
nova.disk.write.requests |
request |
サーバーインスタンスが起動しているHypervisor上で収集 |
監視間隔内の合計値を算出 |
5分 |
ネットワーク受信バイト数 |
Incoming Traffic |
nova.network.incoming.bytes |
byte |
サーバーインスタンスが起動しているHypervisor上で収集 |
監視間隔内の合計値を算出 |
5分 |
ネットワーク送信バイト数 |
Outgoing Traffic |
nova.network.outgoing.bytes |
byte |
サーバーインスタンスが起動しているHypervisor上で収集 |
監視間隔内の合計値を算出 |
5分 |
VM死活監視 ※2 |
VM Status ※3 |
nova.vm.status.bool |
boolean |
サーバーインスタンスが起動しているHypervisor上で収集
正常=0
故障=1
|
監視時の値 |
1分 |
HV死活監視 |
Hypervisor Status |
nova.hv.status.bool |
boolean |
サーバーインスタンスが起動しているHypervisor上で各サーバーインスタンスのネットワークインターフェースのステートにより判定
正常=0
故障=1
|
監視時の値 |
1分 |
注釈
※1 値の最大値は "100 percent x CPUのコア数" となります。(例:サーバーインスタンスが16CPUの場合、値は 0 ~ 1600 percentの範囲となります)
※2 "VM死活監視" はサーバーインスタンスを提供する基盤側からの監視結果を示しており、サーバーインスタンスが起動したままの状態で発生するインスタンス内部のトラブル(カーネルパニックやOSクラッシュ)による故障を検知することはできません。
※3 JP1、JP2リージョンでは "Virtual Machine Status" という名前で表示されます。
サーバーインスタンス ボリューム¶
メーター |
メーター表示名 |
メーター名 |
単位 |
収集元及び判定方法 |
備考 |
監視間隔 |
|---|---|---|---|---|---|---|
ディスク読取バイト数 |
Disk Read Bytes |
cinder.disk.read.bytes |
byte |
サーバーインスタンスが起動しているHypervisor上で収集 |
監視間隔内の合計値を算出 |
5分 |
ディスク書込バイト数 |
Disk Write Bytes |
cinder.disk.write.bytes |
byte |
サーバーインスタンスが起動しているHypervisor上で収集 |
監視間隔内の合計値を算出 |
5分 |
ディスク読取回数 |
Disk Read Requests |
cinder.disk.read.requests |
request |
サーバーインスタンスが起動しているHypervisor上で収集 |
監視間隔内の合計値を算出 |
5分 |
ディスク書込回数 |
Disk Write Requests |
cinder.disk.write.requests |
request |
サーバーインスタンスが起動しているHypervisor上で収集 |
監視間隔内の合計値を算出 |
5分 |
ベアメタルサーバー¶
メーター |
メーター表示名 |
メーター名 |
単位 |
収集元及び判定方法 |
備考 |
監視間隔 |
|---|---|---|---|---|---|---|
筐体電源 |
Chassis Power Status |
baremetal-server.chassis-power.status.bool |
boolean |
当該リソースからIPMIにより収集
オン=false(0)を送信
オフ=true(1)を送信
|
監視時の値 |
5分 |
ファン故障 |
Fan Status |
baremetal-server.fan.status.bool |
boolean |
当該リソースからIPMIにより収集したファン故障の有無により判定
1つでもファンが故障していたら、true(1)を送信
正常時は、false(0)を送信
|
監視時の値 |
5分 |
筐体電源故障 |
Power Supply Status |
baremetal-server.power-supply.status.bool |
boolean |
当該リソースからIPMIにより収集
1つでも電源が故障していたら、true(1)を送信
正常時は、false(0)を送信
|
監視時の値 |
5分 |
CPU故障 |
CPU Status |
baremetal-server.cpu.status.bool |
boolean |
当該リソースからIPMIにより収集したCPU故障の有無により判定
1つでもCPUが故障していたら、true(1)を送信
正常時は、false(0)を送信
|
監視時の値 |
5分 |
メモリ故障 |
Memory Status |
baremetal-server.memory.status.bool |
boolean |
当該リソースからIPMIにより収集したメモリ故障の有無により判定
1つでもメモリが故障していたら、true(1)を送信
正常時は、false(0)を送信
|
監視時の値 |
5分 |
HDD故障 |
Disk Status Failures |
baremetal-server.disk.status.failures |
int |
当該リソースからIPMIにより収集したHDD故障の有無により判定
故障しているディスクの本数を送信(0~36)
|
監視時の値 |
5分 |
NIC故障 |
NIC Status |
baremetal-server.nic.status.bool |
boolean |
当該リソースからIPMIにより収集したNIC故障の有無により判定
1つでもNICが故障していたら、true(1)を送信
正常時は、false(0)を送信
※Workload Optimized 2では表示されません
|
監視時の値 |
5分 |
システムボード故障 |
System Board Status |
baremetal-server.system.board.status.bool |
boolean |
当該リソースからIPMIにより収集したシステムボード故障の有無により判定
1つでもシステムボードが故障していたら、true(1)を送信
正常時は、false(0)を送信
※Workload Optimized 2では表示されません
|
監視時の値 |
5分 |
その他故障 |
Other Statuses |
baremetal-server.etc.status.bool |
boolean |
当該リソースからIPMIにより収集した以下の故障の有無により判定
- RAIDコントローラー故障
- HDD情報が取得できなかった場合(Workload Optimaized 2のみ)
- その他の故障
上記を検知したら、true(1)を送信
正常時は、false(0)を送信
|
監視時の値 |
5分 |
クラウド/サーバー インターネット接続ゲートウェイ¶
メーター |
メーター表示名 |
メーター名 |
単位 |
収集元及び判定方法 |
備考 |
監視間隔 |
|---|---|---|---|---|---|---|
トラフィックIN |
Incoming Traffic |
internet-connectivity.traffic.in.bps |
bps |
当該リソースの機能が割り当てられたネットワーク機器から収集 |
監視間隔内の平均値を算出 |
5分 |
トラフィックOUT |
Outgoing Traffic |
internet-connectivity.traffic.out.bps |
bps |
当該リソースの機能が割り当てられたネットワーク機器から収集 |
監視間隔内の平均値を算出 |
5分 |
GW死活監視 |
Gateway Status |
internet-connectivity.internet_gateway.status.bool |
boolean |
インターネットゲートウェイのインフラストラクチャーのプライマリデバイスとセカンダリデバイスの管理インターフェイスに対してポーリングを行い、ゲートウェイインターフェイス(ロジカルネットワーク側インターフェイス)のリンクステータスを取得します。
リンクステータスがどちらかでもリンクアップの場合には正常と判断します。
リンクステータスがどちらもリンクダウンの場合には異常と判断します。
正常=0
故障=1
|
監視時の値 |
1分 |
GW-IF死活監視 |
Interface Status |
internet-gw-interface.gw_interface.status.bool |
boolean |
インターネットゲートウェイのインフラストラクチャーのプライマリデバイスとセカンダリデバイスの管理インターフェイスに対してポーリングを行い、ゲートウェイインターフェイス(ロジカルネットワーク側インターフェイス)の VRRP ステータスを取得します。
VRRP ステータスが Master と Backup または Backup と Master の場合には正常と判断します。
VRRP ステータスがどちらも Master またはどちらも Backup の場合には異常と判断します。
正常=0
故障=1
|
監視時の値 |
1分 |
注釈
インターネットゲートウェイに対するグローバルIPが存在しない場合、インターネット接続のトラフィックが発生しないため、トラフィックINとトラフィックOUTのサンプル値はモニタリングされません。
クラウド/サーバー Flexible InterConnect接続ゲートウェイ¶
メーター |
メーター表示名 |
メーター名 |
単位 |
収集元及び判定方法 |
備考 |
監視間隔 |
|---|---|---|---|---|---|---|
トラフィックIN |
Incoming Traffic |
fic-interface.traffic.in.bps |
bps |
当該リソースの機能が割り当てられたネットワーク機器から収集 |
監視間隔内の平均値を算出 |
5分 |
トラフィックOUT |
Outgoing Traffic |
fic-interface.traffic.out.bps |
bps |
当該リソースの機能が割り当てられたネットワーク機器から収集 |
監視間隔内の平均値を算出 |
5分 |
GW死活監視 |
Gateway Status |
fic-connectivity.fic_gateway.status.bool |
boolean |
当該リソースの機能が割り当てられたネットワーク機器からSNMPにより収集したステータスにより判定
冗長構成の全ての系がDOWN状態であれば故障
正常=0
故障=1
|
監視時の値 |
1分 |
GW-IF死活監視 |
Interface Status |
fic-gw-interface.gw_interface.status.bool |
boolean |
当該リソースの機能が割り当てられたネットワーク機器のVRRPステータスの正常性により判定
Flexible InterConnect GWのロジカルネットワークと接続されているIF
正常=0
故障=1
|
監視時の値 |
1分 |
IF死活監視 |
Interface Status |
fic-interface.fic_interface.status.bool |
boolean |
当該リソースの機能が割り当てられたネットワーク機器のBGPステータスの正常性により判定
Flexible InterConnect GWの網と接続されているIF
正常=0
故障=1
|
監視時の値 |
1分 |
クラウド/サーバー リージョン間接続¶
メーター |
メーター表示名 |
メーター名 |
単位 |
収集元及び判定方法 |
備考 |
監視間隔 |
|---|---|---|---|---|---|---|
トラフィックIN |
Incoming Traffic |
interdc-interface.traffic.in.bps |
bps |
当該リソースの機能が割り当てられたネットワーク機器から収集 |
監視間隔内の平均値を算出 |
5分 |
トラフィックOUT |
Outgoing Traffic |
interdc-interface.traffic.out.bps |
bps |
当該リソースの機能が割り当てられたネットワーク機器から収集 |
監視間隔内の平均値を算出 |
5分 |
GW死活監視 |
Gateway Status |
interdc-connectivity.interdc_gateway.status.bool |
boolean |
当該リソースの機能が割り当てられたネットワーク機器のSNMP応答の有無により判定
正常=0
故障=1
|
監視時の値 |
1分 |
GW-IF死活監視 |
Interface Status |
interdc-gw-interface.gw_interface.status.bool |
boolean |
当該リソースの機能が割り当てられたネットワーク機器のVRRPステータスの正常性により判定
Datacenter Inter-Connectivity GWのロジカルネットワークと接続されているIF
正常=0
故障=1
|
監視時の値 |
1分 |
IF死活監視 |
Interface Status |
interdc-interface.interdc_interface.status.bool |
boolean |
当該リソースの機能が割り当てられたネットワーク機器のVRRPステータスの正常性により判定
Datacenter Inter-Connectivity GWの網側と接続されているIF
正常=0
故障=1
|
監視時の値 |
1分 |
ロジカルネットワーク¶
メーター |
メーター表示名 |
メーター名 |
単位 |
収集元及び判定方法 |
備考 |
監視間隔 |
|---|---|---|---|---|---|---|
トラフィックIN |
Incoming Traffic |
logical-network-port.traffic.in.bps |
bps |
当該リソースの機能が割り当てられたネットワーク機器から収集 |
監視間隔内の平均値を算出 |
5分 |
トラフィックOUT |
Outgoing Traffic |
logical-network-port.traffic.out.bps |
bps |
当該リソースの機能が割り当てられたネットワーク機器から収集 |
監視間隔内の平均値を算出 |
5分 |
NW死活監視 |
Operational State |
logical-network.network.status.bool |
boolean |
NW死活監視は常に正常(0)が表示されます。正常性を確認したい際にはポート死活監視をご利用ください。
|
||
ポート死活監視 |
Operational State |
logical-network-port.port.status.bool |
boolean |
当該リソースの機能が割り当てられたネットワーク機器から収集
正常=0
故障=1
|
監視時の値 |
1分 |
ロードバランサー¶
メーター |
メーター表示名 |
メーター名 |
単位 |
収集元及び判定方法 |
備考 |
監視間隔 |
|---|---|---|---|---|---|---|
CPU使用率 |
CPU Utilization |
load-balancer.cpu.usage.percents |
percent |
当該リソースの機能が割り当てられたサーバーインスタンスからSNMPにより収集
コアごとの値を合算
|
監視間隔内の平均値を算出 |
5分 |
メモリ使用量 |
Memory Usage |
load-balancer.memory.usage.percents |
percent |
当該リソースの機能が割り当てられたサーバーインスタンスからSNMPにより収集 |
監視間隔内の平均値を算出 |
5分 |
リクエストHTTP数 |
HTTP Request Connections |
load-balancer.http.request.connections |
connection |
当該リソースの機能が割り当てられたサーバーインスタンスからSNMPにより収集 |
起動時から総リクエスト数 |
5分 |
TCPクライアントコネクション数 |
TCP Client Connections |
load-balancer.tcp.client.connections |
connection |
当該リソースの機能が割り当てられたサーバーインスタンスからSNMPにより収集 |
監視間隔内の平均値を算出 |
5分 |
TCPサーバーコネクション数 |
TCP Server Connections |
load-balancer.tcp.server.connections |
connection |
当該リソースの機能が割り当てられたサーバーインスタンスからSNMPにより収集 |
監視間隔内の平均値を算出 |
5分 |
LB死活監視 |
Load Balancer Status |
load-balancer.load_balancer.status.bool |
boolean |
当該リソースの機能が割り当てられたサーバーインスタンスからSNMPにより収集
正常=0
故障=1
|
監視時の値 |
1分 |
IF死活監視 |
Interface Status |
load-balancer-interface.load_balancer_interface.status.bool |
boolean |
当該リソースの機能が割り当てられたサーバーインスタンスからSNMPにより収集
正常=0
故障=1
|
監視時の値 |
1分 |
トラフィックIN |
Incoming Traffic |
load-balancer-interface.traffic.in.bps |
bps |
当該リソースの機能が割り当てられたサーバーインスタンスからSNMPにより収集 |
監視間隔内の平均値を算出 |
5分 |
トラフィックOUT |
Outgoing Traffic |
load-balancer-interface.traffic.out.bps |
bps |
当該リソースの機能が割り当てられたサーバーインスタンスからSNMPにより収集 |
監視間隔内の平均値を算出 |
5分 |
Managed Load Balancer¶
メーター |
メーター表示名 |
メーター名 |
単位 |
収集元及び判定方法 |
備考 |
監視間隔 |
|---|---|---|---|---|---|---|
CPU使用率 |
CPU Utilization |
managed-lb.cpu.utilization.percents |
percent |
当該リソースの機能が割り当てられたサーバーインスタンスからSNMPにより収集 |
監視間隔内の平均値を算出 |
5分 |
メモリ使用率 |
Memory Utilization |
managed-lb.memory.utilization.percents |
percent |
当該リソースの機能が割り当てられたサーバーインスタンスからSNMPにより収集 |
監視間隔内の平均値を算出 |
5分 |
トラフィックIN |
Incoming Traffic on interface-x (x = 1 〜 7) |
managed-lb.interface-x.traffic.in.bps |
bps |
当該リソースの機能が割り当てられたサーバーインスタンスからSNMPにより収集 |
監視時の直近300秒間の平均値 |
5分 |
トラフィックOUT |
Outgoing Traffic on interface-x (x = 1 〜 7) |
managed-lb.interface-x.traffic.out.bps |
bps |
当該リソースの機能が割り当てられたサーバーインスタンスからSNMPにより収集 |
監視時の直近300秒間の平均値 |
5分 |
TCP同時コネクション数 |
TCP Concurrent Connections |
managed-lb.tcp.concurrent.connections |
connection |
当該リソースの機能が割り当てられたサーバーインスタンスからSNMPにより収集 |
5分 |
|
TCP新規コネクション数 |
TCP New Connections |
managed-lb.tcp.new.connections |
connection |
当該リソースの機能が割り当てられたサーバーインスタンスからSNMPにより収集 |
前回の監視時の値と今回の監視時の値の差分を算出 |
5分 |
受付HTTPリクエスト数 |
Accepted Requests |
managed-lb.accepted.requests |
request |
当該リソースの機能が割り当てられたサーバーインスタンスからSNMPにより収集 |
前回の監視時の値と今回の監視時の値の差分を算出 |
5分 |
受付不可HTTPリクエスト数 |
Non-compliant Requests |
managed-lb.non-compliant.requests |
request |
当該リソースの機能が割り当てられたサーバーインスタンスからSNMPにより収集 |
前回の監視時の値と今回の監視時の値の差分を算出 |
5分 |
上限超過パケット数 |
Rejected Packets |
managed-lb.rejected.packets |
packet |
当該リソースの機能が割り当てられたサーバーインスタンスからSNMPにより収集 |
前回の監視時の値と今回の監視時の値の差分を算出 |
5分 |
非スティッキーHTTPリクエスト数 |
Non-sticky Requests |
managed-lb.non-sticky.requests |
request |
当該リソースの機能が割り当てられたサーバーインスタンスからSNMPにより収集 |
前回の監視時の値と今回の監視時の値の差分を算出 |
5分 |
TLSセッション確立失敗数 |
TLS Session Failures |
managed-lb.tls.session.failures |
count |
当該リソースの機能が割り当てられたサーバーインスタンスからSNMPにより収集 |
前回の監視時の値と今回の監視時の値の差分を算出 |
5分 |
アクティブゾーン/グループ |
Active Availability Zone |
managed-lb.availability-zone.active |
int |
当該リソースの機能が割り当てられたサーバーインスタンスが、どのゾーン/グループで動作しているかによって値を判定
ゾーン/グループ(プライマリー)で動作している=0
ゾーン/グループ(セカンダリー)で動作している=1
動作しているゾーン/グループが特定できない=2
|
1分 |
注釈
HA構成 (冗長構成) のプランをご利用の場合は、監視時に Active なリソースの値が表示されます。
お客さまのManaged Load Balancerが設置されているゾーン/グループは、「Managed Load Balancerの概要」に記載されています。「ゾーン/グループ(プライマリー)」「ゾーン/グループ(セカンダリー)」欄をご確認ください。なお、ゾーン/グループについて、詳しくは こちら をご参照ください。
2022年10月24日以前に作成されたインスタンスでは、以下のメーターの「メーター表示名」が本ページの表記と異なり、スペースで区切られる部分が「.」(ドット)で区切られていますので注意してください。(例:「Accepted Requests」 → 「Accepted.Requests」)
受付HTTPリクエスト数
非スティッキーHTTPリクエスト数
TLSセッション確立失敗数
アクティブゾーン/グループ
Managed Load Balancer Policy¶
メーター |
メーター表示名 |
メーター名 |
単位 |
収集元及び判定方法 |
備考 |
監視間隔 |
|---|---|---|---|---|---|---|
コネクション数 |
Total Connections |
managed-lb-policy.total.connections |
connection |
当該リソースの機能が割り当てられたサーバーインスタンスからHTTPにより収集 |
前回の監視時の値と今回の監視時の値の差分を算出 |
5分 |
正常メンバー数 |
Healthy Members |
managed-lb-policy.healthy.members |
count |
当該リソースの機能が割り当てられたサーバーインスタンスからHTTPにより収集 |
5分 |
|
異常メンバー数 |
Unhealthy Members |
managed-lb-policy.unhealthy.members |
count |
当該リソースの機能が割り当てられたサーバーインスタンスからHTTPにより収集 |
5分 |
|
HTTP 2xxレスポンス数 |
HTTP Status 2XX Count |
managed-lb-policy.http.status.2xx.count |
count |
当該リソースの機能が割り当てられたサーバーインスタンスからHTTPにより収集 |
前回の監視時の値と今回の監視時の値の差分を算出 |
5分 |
HTTP 3xxレスポンス数 |
HTTP Status 3XX Count |
managed-lb-policy.http.status.3xx.count |
count |
当該リソースの機能が割り当てられたサーバーインスタンスからHTTPにより収集 |
前回の監視時の値と今回の監視時の値の差分を算出 |
5分 |
HTTP 4xxレスポンス数 |
HTTP Status 4XX Count |
managed-lb-policy.http.status.4xx.count |
count |
当該リソースの機能が割り当てられたサーバーインスタンスからHTTPにより収集 |
前回の監視時の値と今回の監視時の値の差分を算出 |
5分 |
HTTP 5xxレスポンス数 |
HTTP Status 5XX Count |
managed-lb-policy.http.status.5xx.count |
count |
当該リソースの機能が割り当てられたサーバーインスタンスからHTTPにより収集 |
前回の監視時の値と今回の監視時の値の差分を算出 |
5分 |
HTTP 500レスポンス数 |
HTTP Status 500 Count |
managed-lb-policy.http.status.500.count |
count |
当該リソースの機能が割り当てられたサーバーインスタンスからHTTPにより収集 |
前回の監視時の値と今回の監視時の値の差分を算出 |
5分 |
HTTP 502レスポンス数 |
HTTP Status 502 Count |
managed-lb-policy.http.status.502.count |
count |
当該リソースの機能が割り当てられたサーバーインスタンスからHTTPにより収集 |
前回の監視時の値と今回の監視時の値の差分を算出 |
5分 |
HTTP 503レスポンス数 |
HTTP Status 503 Count |
managed-lb-policy.http.status.503.count |
count |
当該リソースの機能が割り当てられたサーバーインスタンスからHTTPにより収集 |
前回の監視時の値と今回の監視時の値の差分を算出 |
5分 |
HTTP 504レスポンス数 |
HTTP Status 504 Count |
managed-lb-policy.http.status.504.count |
count |
当該リソースの機能が割り当てられたサーバーインスタンスからHTTPにより収集 |
前回の監視時の値と今回の監視時の値の差分を算出 |
5分 |
注釈
HA構成 (冗長構成) のプランをご利用の場合は、毎分の監視時にActiveなリソースの値を取得し、その平均値が表示されます。そのため、取得間隔(5 分間等)の中で毎分の連続した取得結果の平均でなくなる可能性がございます 。
2022年10月24日以前に作成されたインスタンスでは、以下のメーターの「メーター表示名」が本ページの表記と異なり、スペースで区切られる部分が「.」(ドット)で区切られていますので注意してください。(例:「HTTP Status 2XX Count」 → 「HTTP.Status.2XX.Count」 )
HTTP 2xx レスポンス数
HTTP 3xx レスポンス数
HTTP 4xx レスポンス数
HTTP 5xx レスポンス数
HTTP 500 レスポンス数
HTTP 502 レスポンス数
HTTP 503 レスポンス数
HTTP 504 レスポンス数
Managed Load Balancer SSL証明書¶
メーター |
メーター表示名 |
メーター名 |
単位 |
収集元及び判定方法 |
備考 |
監視間隔 |
|---|---|---|---|---|---|---|
CA証明書の有効残日数 |
CA Certificate Remaining Days |
managed-lb-certificate.ca_cert.remaining.days |
day |
当該リソースより収集
・正の値 : CA証明書の有効期限までの残り日数を表示
・0 : CA証明書の有効期限が切れている
|
監視時の値 |
60 分 |
CA証明書の有効性 |
CA Certificate Validity |
managed-lb-certificate.ca_cert.is_valid |
int |
当該リソースより収集
・0 : CA証明書は有効期限内である
・1 : CA証明書の有効期限が切れている
|
監視時の値 |
60分 |
SSL証明書の有効残日数 |
SSL Certificate Remaining Days |
managed-lb-certificate.ssl_cert.remaining.days |
day |
当該リソースより収集
・正の値 : SSL証明書の有効期限までの残り日数を表示
・0 : SSL証明書の有効期限が切れている
|
監視時の値 |
60分 |
SSL証明書の有効性 |
SSL Certificate Validity |
managed-lb-certificate.ssl_cert.is_valid |
int |
当該リソースより収集
・0 : SSL証明書は有効期限内である
・1 : SSL証明書の有効期限が切れている
|
監視時の値 |
60分 |
注釈
SSL秘密鍵/SSL証明書/CA証明書(中間証明書)の全てがアップロードされているSSL証明書のみ監視できます。
ファイアウォール¶
メーター |
メーター表示名 |
メーター名 |
単位 |
収集元及び判定方法 |
備考 |
監視間隔 |
|---|---|---|---|---|---|---|
CPU使用率(RE) |
CPU Utilization(RE) |
vsrx.cpu.utilization-re.percents |
percent |
vSRX の RE(CPU処理部分)のCPU usage(%) |
監視間隔内の平均値を算出 |
5分 |
CPU使用率(FPC) |
CPU Utilization(FPC) |
vsrx.cpu.utilization-fpc.percents |
percent |
vSRX FPC(Packet転送部分)のCPU usage(%) |
監視間隔内の平均値を算出 |
5分 |
メモリ使用率(RE) |
Memory Utilization(RE) |
vsrx.memory.utilization-re.percents |
percent |
vSRX の RE(CPU処理部分)のMemory usage(%) |
監視間隔内の平均値を算出 |
5分 |
メモリ使用率(FPC) |
Memory Utilization(FPC) |
vsrx.memory.utilization-fpc.percents |
percent |
vSRX の FPC(Packet転送部分)のMemory usage(%) |
監視間隔内の平均値を算出 |
5分 |
TCPアクティブ接続数 |
TCP Active Connections |
vsrx.tcp.active.connections |
cps(connections per sec) |
vSRXから累積値を取得し、差分をcps(connections per sec)に変換して表示 |
5分間の平均値 |
5分 |
TCPパッシブ接続数 |
TCP Passive Connections |
vsrx.tcp.passive.connections |
connection |
vSRXから累積値を取得し、差分をcps(connections per sec)に変換して表示 |
5分間の平均値 |
5分 |
死活監視1(sysUptime) |
OS Monitoring Status |
vsrx.os.monitoring.status.bool |
boolean |
vSRXから SNMP sysUptime を取得した返り値から、snmpによるモニタリングが正常かどうかを判定
正常=0
故障=1
|
監視時の値 |
1分 |
死活監視2(vSRX GuestOS) |
OS Login Status |
vsrx.os.login.status.bool |
boolean |
vSRX へ rest API でログイン処理実施可能かどうかを判定
正常=0(200 OK)
故障=1(401 Unauthorized)
|
監視時の値 |
1分 |
死活監視3(nova VM) |
VM Status |
vsrx.vm.status.bool |
boolean |
サーバーインスタンスが起動しているHypervisor上で収集
正常=0(200 OK & Status Active)
故障=1(200 OK & Status Shut Off)
|
監視時の値 |
1分 |
トラフィックIN |
Incoming Traffic for ge-00X |
vsrx.ge-00X.traffic.in.bps |
bps |
vSRXからは累積値を収集(ifHCInOctets)し、前回との差分をbyteからbps(bit per sec)に変換して表示
"ge-00X"は、Interface毎に表示
|
監視間隔内の平均値を算出 |
5分 |
トラフィックOUT |
Outgoing Traffic for ge-00X |
vsrx.ge-00X.traffic.out.bps |
bps |
vSRXからは累積値を収集(ifHCInOctets)し、前回との差分をbyteからbps(bit per sec)に変換して表示
"ge-00X"は、Interface毎に表示
|
監視間隔内の平均値を算出 |
5分 |
注釈
vSRXのメーターでは、インターフェース数が15port分表示されますが、ge-008〜ge-014のインターフェースは利用されていません。したがって、モニタリングデータも表示はされませんのでご注意ください。
メモリ使用率(FPC)は、Juniper社vSRXの仕様上、バージョン19.2R1.8の場合71%、20.4R2の場合63%、22.4R1の場合67%を常に使用した状態となります。したがって、各プランの定常的なメモリ使用率(FPC)を超えるメモリを使用した場合に値が変動します。
カスタムリソース¶
カスタムリソースは、カスタムメーター機能でお客さまが任意に作成可能な監視リソースです。
Smart Data Platform以外の場所に存在するサーバー等のリソースを監視する際などにご利用いただけます。
カスタムリソースの作成方法については、カスタムメーターの欄をご参照ください。
2. カスタムメーター¶
カスタムメーターは、お客さまが任意のスクリプト等によって収集したデータをモニタリングサーバーに蓄積させる機能です。
これにより、任意の値を他のメーターと同様にグラフ化・アラーム設定が可能です。
データの送信にはAPIを利用する必要があります。そのため、APIの送信元となる機器はインターネットに接続されている必要があります。
カスタムメーター作成時にお客さまが任意の名前をリソースIDに指定することで、指定した名前のカスタムリソースが作成できます。
カスタムメーターの仕組み¶
カスタムメーターの機能¶
機能 |
内容 |
|---|---|
カスタムメーターの新規作成(API) |
カスタムメーターのデータ格納領域を作成できます。
データ格納領域を作成した後でデータの登録が可能になり、新規作成とデータ登録は同時にできませんのでご注意ください。
|
カスタムメーターデータの登録(API) |
作成されたデータ格納領域にモニタリングで管理するデータ(サンプル値)を登録できます。 |
カスタムメーターの編集(API) |
一度作成したカスタムメーターの各パラメータを変更できます。 |
カスタムメーターのステータス¶
ステータス |
説明 |
|---|---|
アクティブカスタムメーター |
実際に利用中で課金対象のカスタムメーターを表します。カスタムメーターにサンプル値を登録すると、このステータスに遷移します。
同時に存在することが可能なアクティブカスタムメーターの数は最大30個までとなります。これを超える場合、31個目の作成時にエラーとなります。
|
非アクティブカスタムメーター |
24時間サンプル値の登録が行われなかったアクティブカスタムメーターは非アクティブカスタムメーターに遷移します。
このステータスになった場合、アクティブカスタムメーターとしてカウントされなくなるため、新たに別のアクティブカスタムメーターを利用することができます。
なお、それまでに蓄積されたサンプル値は設定された保存期間中(デフォルトでは31日、メーター保存期間延長機能を組み合わせることで397日)は保持されます。
また、一度非アクティブになったカスタムメーターに値登録を実行した場合、アクティブカスタムメーターとして再びカウントされます。
同時に存在する事が可能な非アクティブカスタムメーターとアクティブカスタムメーターの合計数は最大120個までとなります。これを超える場合、121個目の作成時にエラーとなります。
|
注釈
カスタムメーターの作成上限は120個となります。
Smart Data Platform環境上のサーバインスタンス等からカスタムメーターを定期送信する場合、Smart Data Platformのネットワークやゲートウェイのメンテナンスおよび故障によってMonitoring APIエンドポイントに到達できなくなり、データの登録が一時的に不可能となる場合がございます。
Smart Data Platform環境上でカスタムメーターをご利用の際はネットワークのメンテナンス・故障情報にご注意ください。
カスタムメーターエージェント¶
カスタムメーターエージェントで取得可能なメーター
No |
分類 |
メーター名 |
内容 |
単位 |
収集元及び判定方法 |
任意 |
監視間隔 |
|---|---|---|---|---|---|---|---|
1 |
CPU使用率 |
cpu.user.percents |
CPU使用率(ユーザーモード) |
percent |
/proc/statを参照し、前回収集値との差分から算出 |
監視間隔内の平均値を算出 |
任意 |
2 |
CPU使用率 |
cpu.nice.percents |
CPU使用率(低優先度のユーザーモード) |
percent |
/proc/statを参照し、前回収集値との差分から算出 |
監視間隔内の平均値を算出 |
任意 |
3 |
CPU使用率 |
cpu.system.percents |
CPU使用率(システムモード) |
percent |
/proc/statを参照し、前回収集値との差分から算出 |
監視間隔内の平均値を算出 |
任意 |
4 |
CPU使用率 |
cpu.idle.percents |
CPU使用率(タスク待ち) |
percent |
/proc/statを参照し、前回収集値との差分から算出 |
監視間隔内の平均値を算出 |
任意 |
5 |
CPU使用率 |
cpu.iowait.percents |
CPU使用率(I/O待ち) |
percent |
/proc/statを参照し、前回収集値との差分から算出 |
監視間隔内の平均値を算出 |
任意 |
6 |
CPU使用率 |
cpu.irq.percents |
CPU使用率(割り込み) |
percent |
/proc/statを参照し、前回収集値との差分から算出 |
監視間隔内の平均値を算出 |
任意 |
7 |
CPU使用率 |
cpu.softirq.percents |
CPU使用率(ソフト割り込み) |
percent |
/proc/statを参照し、前回収集値との差分から算出 |
監視間隔内の平均値を算出 |
任意 |
8 |
CPU使用率 |
cpu.steal.percents |
CPU使用率(仮想化環境で他のOSで使用した時間) |
percent |
/proc/statを参照し、前回収集値との差分から算出 |
監視間隔内の平均値を算出 |
任意 |
9 |
CPU使用率 |
cpu.guest.percents |
CPU使用率(ゲストOSの仮想CPU) |
percent |
/proc/statを参照し、前回収集値との差分から算出 |
監視間隔内の平均値を算出 |
任意 |
10 |
ディスク |
disk.{device名}.reads.completed.count |
完了読み込みIO数 |
count |
監視対象のdeviceを調べ、/proc/diskstatsの該当行を参照し、前回収集値との差分から算出 |
監視間隔内の合計値を算出 |
任意 |
11 |
ディスク |
disk.{device名}.reads.merged.count |
マージ読み込みIO数 |
count |
監視対象のdeviceを調べ、/proc/diskstatsの該当行を参照し、前回収集値との差分から算出 |
監視間隔内の合計値を算出 |
任意 |
12 |
ディスク |
disk.{device名}.reads.sectors.count |
読み込みセクター数 |
count |
監視対象のdeviceを調べ、/proc/diskstatsの該当行を参照し、前回収集値との差分から算出 |
監視間隔内の合計値を算出 |
任意 |
13 |
ディスク |
disk.{device名}.reads.milliseconds |
読み込みミリ秒数 |
millisecond |
監視対象のdeviceを調べ、/proc/diskstatsの該当行を参照し、前回収集値との差分から算出 |
監視間隔内の合計値を算出 |
任意 |
14 |
ディスク |
disk.{device名}.writes.completed.count |
完了書き込みIO数 |
count |
監視対象のdeviceを調べ、/proc/diskstatsの該当行を参照し、前回収集値との差分から算出 |
監視間隔内の合計値を算出 |
任意 |
15 |
ディスク |
disk.{device名}.writes.merged.count |
マージ書き込みIO数 |
count |
監視対象のdeviceを調べ、/proc/diskstatsの該当行を参照し、前回収集値との差分から算出 |
監視間隔内の合計値を算出 |
任意 |
16 |
ディスク |
disk.{device名}.writes.sectors.count |
書き込みセクター数 |
count |
監視対象のdeviceを調べ、/proc/diskstatsの該当行を参照し、前回収集値との差分から算出 |
監視間隔内の合計値を算出 |
任意 |
17 |
ディスク |
disk.{device名}.writes.milliseconds |
書き込み秒数 |
millisecond |
監視対象のdeviceを調べ、/proc/diskstatsの該当行を参照し、前回収集値との差分から算出 |
監視間隔内の合計値を算出 |
任意 |
18 |
ディスク |
disk.{device名}.currently.ios.count |
実行中のI/O数 |
count |
監視対象のdeviceを調べ、/proc/diskstatsの該当行を参照し、前回収集値との差分から算出 |
監視時の値 |
任意 |
19 |
ディスク |
disk.{device名}.ios.milliseconds |
IO実行秒数 |
millisecond |
監視対象のdeviceを調べ、/proc/diskstatsの該当行を参照し、前回収集値との差分から算出 |
監視間隔内の合計値を算出 |
任意 |
20 |
ディスク |
disk.{device名}.weighted.ios.milliseconds |
重み付きIO実行秒数 |
millisecond |
監視対象のdeviceを調べ、/proc/diskstatsの該当行を参照し、前回収集値との差分から算出 |
監視間隔内の合計値を算出 |
任意 |
21 |
ネットワーク |
network.{nwif名}.receive.bytes |
受信バイト数 |
byte |
/proc/net/devを参照し、前回収集値との差分から算出。NWインターフェースごとの値を算出 |
監視間隔内の合計値を算出 |
任意 |
22 |
ネットワーク |
network.{nwif名}.receive.packets.count |
受信パケット数 |
count |
/proc/net/devを参照し、前回収集値との差分から算出。NWインターフェースごとの値を算出 |
監視間隔内の合計値を算出 |
任意 |
23 |
ネットワーク |
network.{nwif名}.receive.errs.count |
エラーが発生した受信パケット数 |
count |
/proc/net/devを参照し、前回収集値との差分から算出。NWインターフェースごとの値を算出 |
監視間隔内の合計値を算出 |
任意 |
24 |
ネットワーク |
network.{nwif名}.receive.drop.count |
dropされた受信パケット数 |
count |
/proc/net/devを参照し、前回収集値との差分から算出。NWインターフェースごとの値を算出 |
監視間隔内の合計値を算出 |
任意 |
25 |
ネットワーク |
network.{nwif名}.receive.fifo.count |
FIFOエラーが発生した受信パケット数 |
count |
/proc/net/devを参照し、前回収集値との差分から算出。NWインターフェースごとの値を算出 |
監視間隔内の合計値を算出 |
任意 |
26 |
ネットワーク |
network.{nwif名}.receive.frame.count |
フレームエラーが発生した受信パケット数 |
count |
/proc/net/devを参照し、前回収集値との差分から算出。NWインターフェースごとの値を算出 |
監視間隔内の合計値を算出 |
任意 |
27 |
ネットワーク |
network.{nwif名}.receive.compressed.count |
圧縮された受信パケット数 |
count |
/proc/net/devを参照し、前回収集値との差分から算出。NWインターフェースごとの値を算出 |
監視間隔内の合計値を算出 |
任意 |
28 |
ネットワーク |
network.{nwif名}.receive.multicast.count |
マルチキャストで送られた受信パケット数 |
count |
/proc/net/devを参照し、前回収集値との差分から算出。NWインターフェースごとの値を算出 |
監視間隔内の合計値を算出 |
任意 |
29 |
ネットワーク |
network.{nwif名}.transmit.bytes |
送信バイト数 |
byte |
/proc/net/devを参照し、前回収集値との差分から算出。NWインターフェースごとの値を算出 |
監視間隔内の合計値を算出 |
任意 |
30 |
ネットワーク |
network.{nwif名}.transmit.packets.count |
送信パケット数 |
count |
/proc/net/devを参照し、前回収集値との差分から算出。NWインターフェースごとの値を算出 |
監視間隔内の合計値を算出 |
任意 |
31 |
ネットワーク |
network.{nwif名}.transmit.errs.count |
エラーが発生した送信パケット数 |
count |
/proc/net/devを参照し、前回収集値との差分から算出。NWインターフェースごとの値を算出 |
監視間隔内の合計値を算出 |
任意 |
32 |
ネットワーク |
network.{nwif名}.transmit.drop.count |
dropされた送信パケット数 |
count |
/proc/net/devを参照し、前回収集値との差分から算出。NWインターフェースごとの値を算出 |
監視間隔内の合計値を算出 |
任意 |
33 |
ネットワーク |
network.{nwif名}.transmit.fifo.count |
FIFOエラーが発生した送信パケット数 |
count |
/proc/net/devを参照し、前回収集値との差分から算出。NWインターフェースごとの値を算出 |
監視間隔内の合計値を算出 |
任意 |
34 |
ネットワーク |
network.{nwif名}.transmit.colls.count |
コリジョンが発生した送信パケット数 |
count |
/proc/net/devを参照し、前回収集値との差分から算出。NWインターフェースごとの値を算出 |
監視間隔内の合計値を算出 |
任意 |
35 |
ネットワーク |
network.{nwif名}.transmit.carrier.count |
キャリアロスされた送信パケット数 |
count |
/proc/net/devを参照し、前回収集値との差分から算出。NWインターフェースごとの値を算出 |
監視間隔内の合計値を算出 |
任意 |
36 |
ネットワーク |
network.{nwif名}.transmit.compressed.count |
圧縮された送信パケット数 |
count |
/proc/net/devを参照し、前回収集値との差分から算出。NWインターフェースごとの値を算出 |
監視間隔内の合計値を算出 |
任意 |
37 |
ロードアベレージ |
loadavg.1.count |
ロードアベレージ(1分) |
count |
/proc/loadavgを参照 |
監視時における過去1分間の平均値 |
任意 |
38 |
ロードアベレージ |
loadavg.5.count |
ロードアベレージ(5分) |
count |
/proc/loadavgを参照 |
監視時における過去5分間の平均値 |
任意 |
39 |
ロードアベレージ |
loadavg.15.count |
ロードアベレージ(15分) |
count |
/proc/loadavgを参照 |
監視時における過去15分間の平均値 |
任意 |
40 |
メモリ |
memory.memtotal.kilobytes |
メモリ総容量 |
kilobyte |
/proc/meminfoを参照 |
監視時の値 |
任意 |
41 |
メモリ |
memory.memfree.kilobytes |
空きメモリ容量 |
kilobyte |
/proc/meminfoを参照 |
監視時の値 |
任意 |
42 |
メモリ |
memory.buffers.kilobytes |
バッファメモリ容量 |
kilobyte |
/proc/meminfoを参照 |
監視時の値 |
任意 |
43 |
メモリ |
memory.cached.kilobytes |
キャッシュメモリ容量 |
kilobyte |
/proc/meminfoを参照 |
監視時の値 |
任意 |
44 |
メモリ |
memory.swapcached.kilobytes |
スワップキャッシュメモリ容量 |
kilobyte |
/proc/meminfoを参照 |
監視時の値 |
任意 |
45 |
メモリ |
memory.active.kilobytes |
アクティブメモリ容量 |
kilobyte |
/proc/meminfoを参照 |
監視時の値 |
任意 |
46 |
メモリ |
memory.inactive.kilobytes |
インアクティブメモリ容量 |
kilobyte |
/proc/meminfoを参照 |
監視時の値 |
任意 |
47 |
メモリ |
memory.swaptotal.kilobytes |
スワップ総容量 |
kilobyte |
/proc/meminfoを参照 |
監視時の値 |
任意 |
48 |
メモリ |
memory.swapfree.kilobytes |
スワップ空き容量 |
kilobyte |
/proc/meminfoを参照 |
監視時の値 |
任意 |
49 |
メモリ |
memory.usedtotal.kilobytes |
使用メモリ容量 |
kilobyte |
/proc/meminfoのMemTotal, MemFree, Buffers, Cachedから算出 |
監視時の値 |
任意 |
注釈
カスタムメーターエージェントを動作させるサーバーからインターネットを介してモニタリングAPIエンドポイントに疎通可能である必要があります。
カスタムメーターエージェントが起動するインスタンスが停止した場合やインターネットとの疎通が途絶えた場合は、収集した値はモニタリングサーバーへ蓄積されません。
カスタムメーターエージェントの動作対象OSは、以下の通りとなります。(記載以外のLinux環境でも動作いたしますが、サポート対象外とさせていただきます)
CentOS 7.7-1908
CentOS 7.9-2009
Red Hat Enterprise Linux 7.7
Red Hat Enterprise Linux 7.9
Red Hat Enterprise Linux 8.4
Red Hat Enterprise Linux 8.6
Red Hat Enterprise Linux 8.8
Rocky Linux 8.5
Ubuntu 20.04.1
Ubuntu 22.04.2
カスタムメーターエージェントはSmart Data Platformのサーバーインスタンス上での使用・動作することを目的としており、その場合においてご利用いただく権利を提供します。
お客さまがこれとは異なるサーバー上で動作させる場合にはお客さまの責任において実施するものとし、NTTドコモビジネスはこれをサポートすることはできません。
なお、お客さまは、NTTドコモビジネスが提供するベーシックサポートにおいて以下の質問・相談を行うことができます。
カスタムメーターエージェントについての仕様、操作方法に関する質問
カスタムメーターエージェントが正常に動作しない場合における原因調査、回避措置に関する質問・相談
NTTドコモビジネスが、問題解決のために有効だと判断した場合、カスタムメーターエージェントの修正版の開発および修正版の提供を行います。ただし、修正版の提供に関わるリードタイムは当社が判断した期間とします。
カスタムメーターエージェントのパッケージを提供するリポジトリサーバーの稼働率や通信速度につきましてはベストエフォートです。
その他のご注意¶
1つのカスタムメーターに対するデータの登録上限回数は1日あたり1500回です。そのため、最大で約1分に1回の間隔で値を登録することができます。
1日あたりの登録数は0:00(UTC)にリセットされます。
カスタムメーターの編集アクションに関しては1日あたりの上限(1500回)の対象外となります。
1回のAPIリクエストで100個のカスタムメーターの作成・データの登録を行うことができます。ただし、同一のカスタムメーターに対して「カスタムメーターの新規作成」と「データの登録」は同時に実施できません。
お客さま操作によってカスタムメーターを削除することはできません。カスタムメーターは非アクティブカスタムメーターとなった後、設定された保存期間を超過すると自動的に削除されます。(非アクティブカスタムメーターは課金の対象外です)
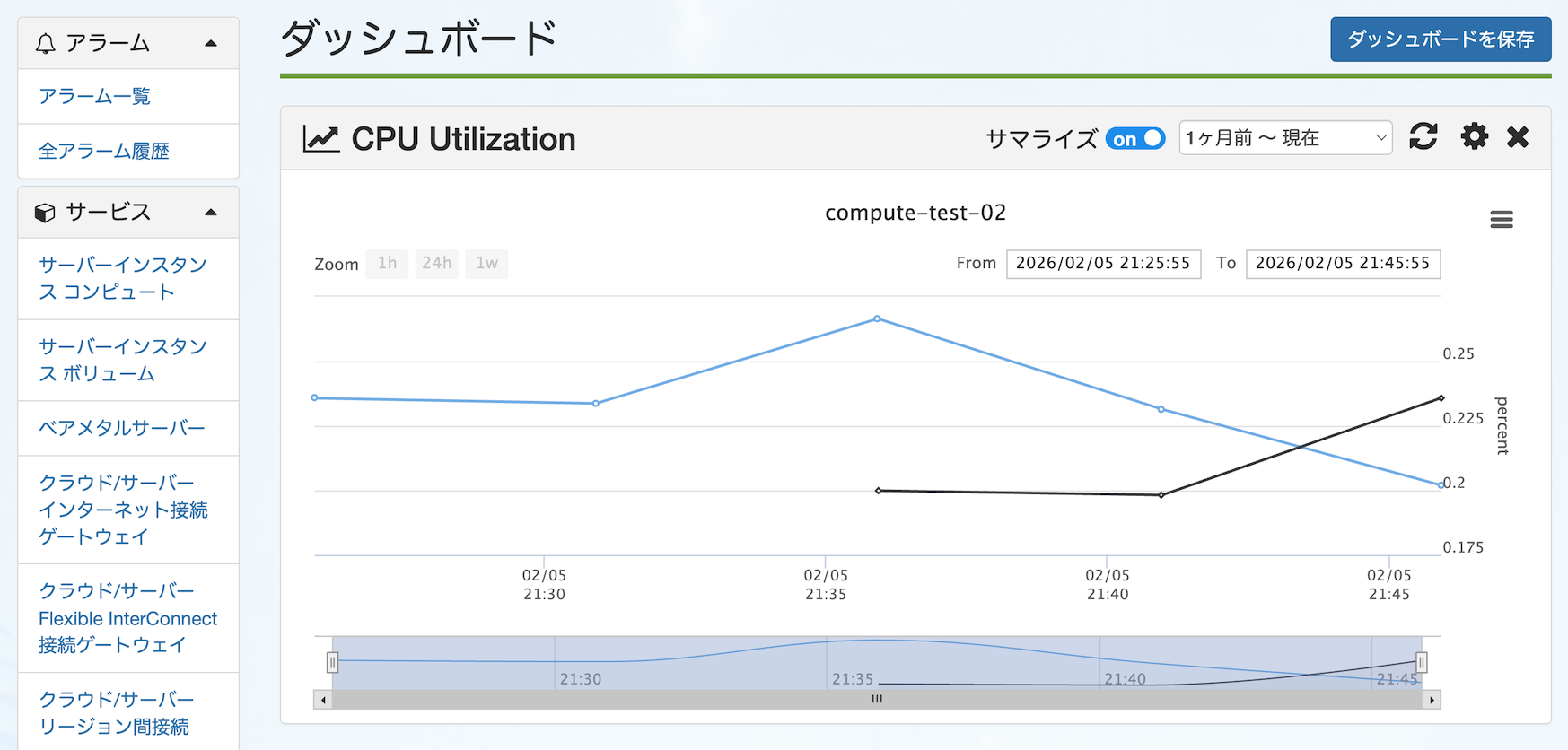
3. グラフ生成機能¶
収集・蓄積されたデータを元にグラフを生成・表示する機能を提供します。
複数のメーターのデータを1つのグラフに表示することも可能です。
サマライズ設定をONにした場合、一定数以上の値がグラフの表示対象になった際に平均化された値が表示されます。
サマライズ設定をOFFにした場合、常にすべての値が表示されます。

注釈
モニタリングの設備故障などにより各メーターのデータを取得できない場合、その時刻の値は存在せず、グラフ上に表示されません。
4. アラーム作成機能¶
監視項目に対してアラーム条件及びアラーム発生時のアクションを設定する機能を提供します。
本機能を利用することで、障害発生時やリソース不足時に通知を行うことができます。
監視項目がアラームの条件を満たす場合、アラームのステータスは「ALARM」に変化します。アラーム条件を満たさない場合にはステータスは「OK」に変化します。
本機能ではアラームのステータスが「ALARM」、もしくは「OK」に変化した際に実行するアクションを設定できます。
設定したアクションは、アラームが該当のステータスに変化した際、即時に実行されます。
1アラーム設定につき5つのアクションを設定できます。
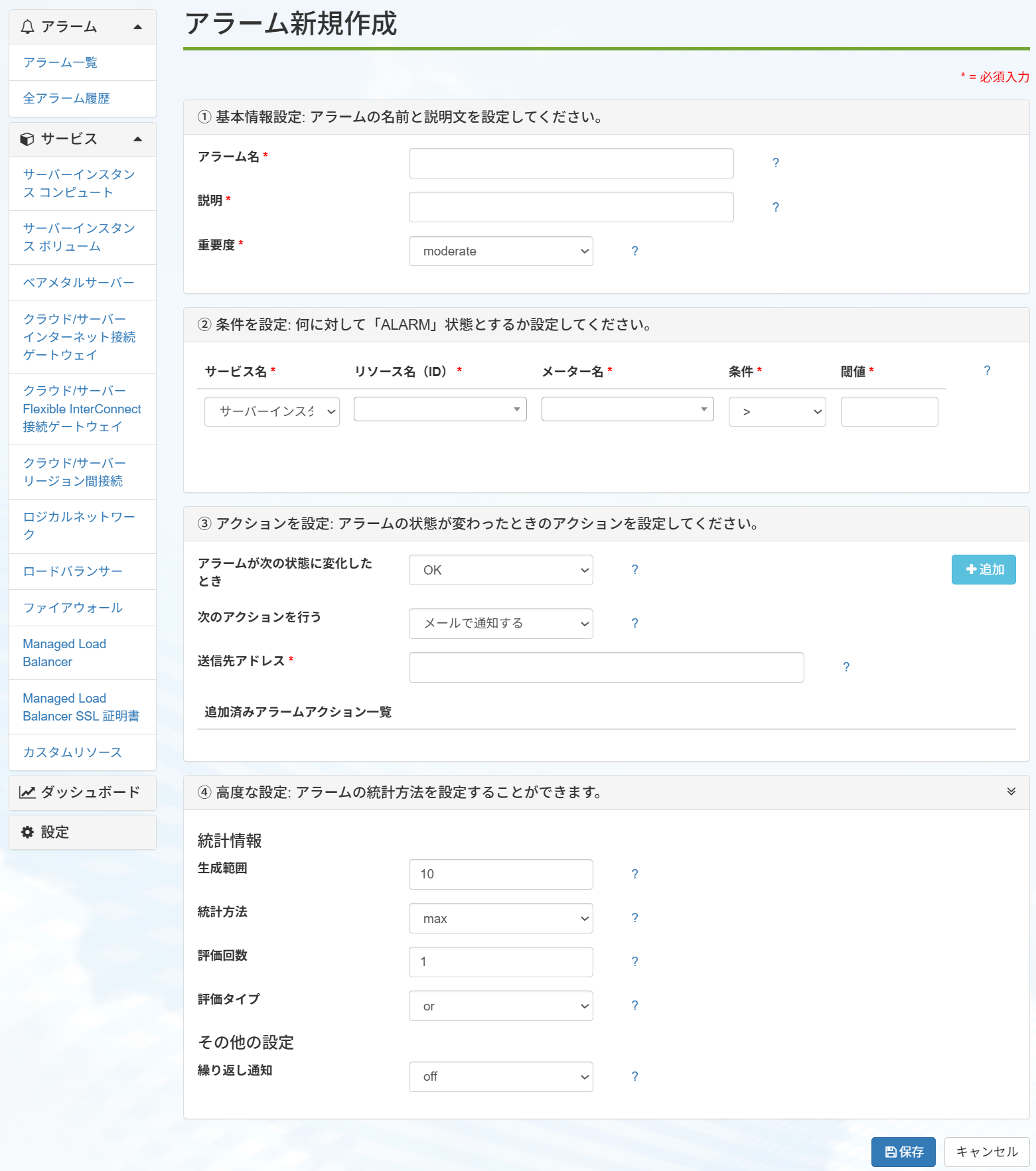
アラームの設定¶
1. 基本情報設定
項目名 |
説明 |
|---|---|
アラーム名 |
アラームの名前を入力します。 |
説明 |
アラームの目的や設定内容を入力します。 |
重要度 |
low、moderate、criticalから選択できます。
選択した内容はアラーム一覧画面、および通知メールに表示されます。(システム処理や通知挙動への影響はありません)
|
2. 条件
項目名 |
説明 |
|---|---|
サービス名 |
監視対象のサービスを選択します。 |
リソース名(ID) |
監視対象のリソースを選択します。 |
メーター名 |
監視対象のメーターを選択します。 |
条件 |
ALARM状態と見なす条件を設定します。
以下の値から選択できます。(>, >=, =, <=, <, !=)
|
閾値 |
ALARM状態とする閾値を入力します。
入力できる値は整数12桁、小数4桁までの数値となります。(範囲:0.0000~999999999999.9999)
|
3. アクション
項目名 |
説明 |
|---|---|
アラームが次の状態に変化したとき |
アラームがどのステータスのときにアクションを実行するか設定します。
「ALARM」を選択した場合、「2. 条件」で設定された条件に当てはまった際に、選んだアクションが実行されます。
「OK」を選択した場合、「2. 条件」で設定された条件に当てはまらないときに、選んだアクションが実行されます。
|
次のアクションを行う |
アクションの種類を設定します。
設定可能な項目は後述の「アクションの種類」を参照ください。
|
送信先アドレス |
通知先のアドレスを入力します。 |
4. 高度な設定
「高度な設定」を利用して統計方法を設定することで、アラームの条件を拡張できます。
「高度な設定」の項目にはデフォルトから値が設定されており、監視間隔が10秒以内の場合においてはアラームの条件に影響します。
各メーターの監視間隔は こちら をご参照ください。
項目名 |
説明 |
|---|---|
生成範囲 |
統計情報を生成する範囲を秒単位で指定します。 |
統計方法 |
以下の値から選択できます。
|
評価回数 |
評価を行う生成範囲の個数を指定します。 |
評価タイプ |
アクションの実行条件を指定します。
評価回数の内のいずれか1回でも条件を満たす場合に「ALARM」状態と判定するときは「or」に設定します。
行った全ての評価で条件を満たす場合に「ALARM」状態と判定するときは「and」に設定します。
|
繰り返し通知 |
アラームの繰り返し通知の有無を選択します。
「on」を設定すると、「ALARM」状態継続中は5分毎にアラームアクションが実行されます。
|
アクション実行のタイミング¶
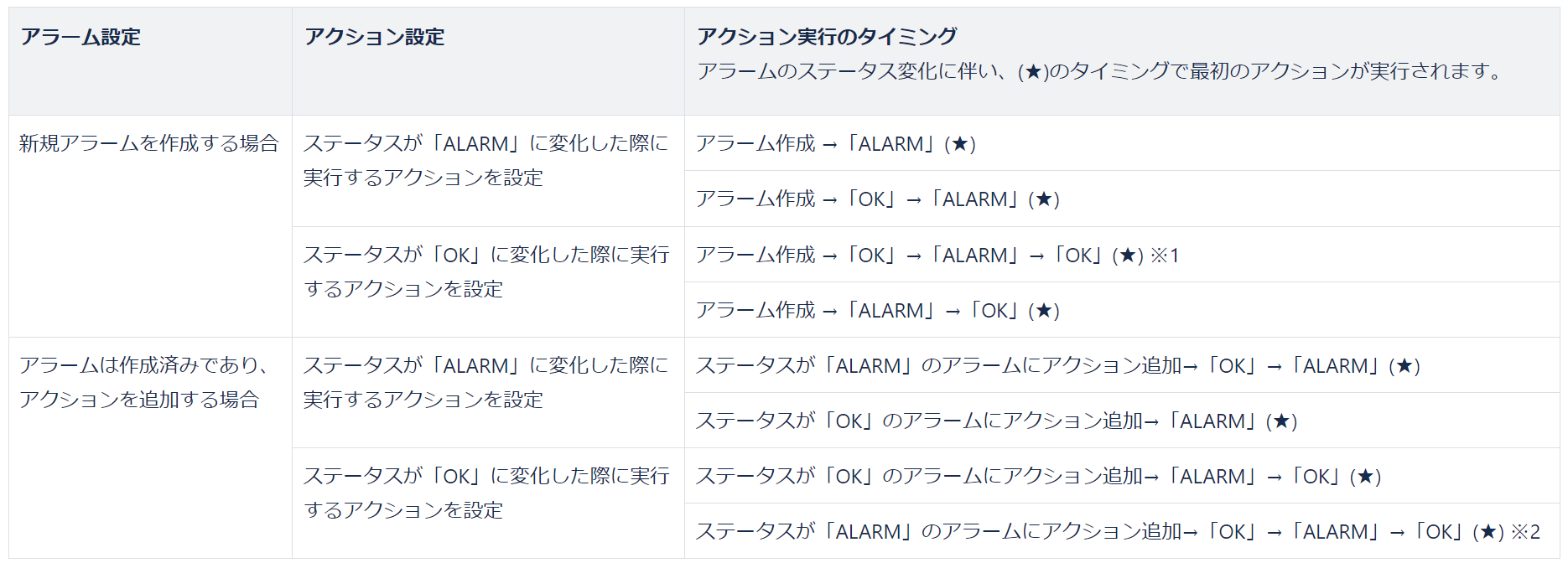
注釈
「ALARM」に変化した際に実行するアクション設定と「OK」に変化した際に実行するアクション設定では、一部の挙動が異なります。
「OK」に変化した際のアクションを設定する場合、新規で改めてアラームを作成するか、もしくはステータスが「OK」の作成済みアラームにおいてアクションを設定することを推奨します。
作成済みのアラームが「ALARM」のステータスにおいて「OK」アクションを追加した場合、最初に「OK」に変化したタイミングではアクションが実行されないためご注意ください。
再度「ALARM」に変化後、「OK」に変化した際に設定したアクションが実行されます。
アクションの種類¶
メール
POSTリクエストの送信
注釈
ネットワーク遅延やサーバー負荷等により過去のアラームが通知される場合がございます。アラームが通知された場合は、ポータル上で最新の状況をご確認ください。
モニタリングの設備故障などにより各メーターのデータが取得できない場合、その時刻の値は存在せず、アラーム検知の対象外となります。
モニタリングのアラームにおいて、アラーム通知が複数回発生してしまう事象を確認しています。詳細は 既知の事象 ページを参照ください。
通知内容(メール)¶
項目 |
説明 |
|---|---|
アラーム名 |
アラーム作成時に指定した値が表示されます |
説明 |
アラーム作成時に指定した値が表示されます |
要因 |
アクションを実行する要因となった時刻と値が表示されます |
ステータス |
ステータスが表示されます(ALARM or OK) |
重要度 |
アラーム作成時に指定した値が表示されます |
閾値 |
アラーム作成時に指定した値が表示されます |
テナント |
アラーム設定が行われたテナントIDが表示されます |
生成範囲 |
アラーム作成時に指定した値が表示されます |
評価回数 |
アラーム作成時に指定した値が表示されます |
統計方法 |
アラーム作成時に指定した値が表示されます |
評価タイプ |
アラーム作成時に指定した値が表示されます |
リージョン |
アラーム設定の存在するリージョンが表示されます |
サービス名 |
アラーム設定の条件で指定した値が表示されます |
メーター ID |
アラーム設定の条件で指定した値が表示されます |
メーター名 |
アラーム設定の条件で指定した値が表示されます |
リソース ID |
アラーム設定の条件で指定した値が表示されます |
リソース名 |
アラーム設定の条件で指定した値が表示されます |
単位 |
アラーム設定の条件で指定したメーターの単位が表示されます |
メール例
アラーム (sample) の状態が OK に切り替わりました。
アラーム詳細:
- アラーム名: sample
- 説明: sample alarm
- 要因: 2023-01-01T00:00:03+09:00 時点でアラームが ALARM 状態に変化しました。 最新の値: 1
- ステータス: ALARM
- 重要度: moderate
- 閾値: メーター = 1.0
- テナント: a7f56d0b1d9046df9328cdde855a61a5
- 統計情報:
-- 生成範囲: 10
-- 評価回数: 1
-- 統計方法: max
-- 評価タイプ: or
メーター詳細:
- リージョン: jp1
- サービス名: nova
- メーター ID: nova.hv.status.bool
- メーター名: Hypervisor Status
- リソース ID: nova_6fce4a87-d8a3-490b-be65-dacd8867955c
- リソース名: sample_resource
- 単位: boolean
通知内容(POSTリクエスト)¶
項目 |
説明 |
|---|---|
current |
ステータスが表示されます(ALARM or OK) |
alarm_id |
対象アラーム設定のIDが表示されます |
reason |
アクションを実行する要因となった時刻と値が英語で表示されます |
reason_jp |
アクションを実行する要因となった時刻と値が日本語で表示されます |
most_recent |
最新の値が表示されます |
type |
「threshold」という値が固定で表示されます |
disposition |
「inside」もしくは「outside」という値が固定で表示されます |
POSTリクエスト例
{
"current": "OK",
"alarm_id": "d1ae7fb6-452a-456d-8baa-61752c92c909",
"reason": "Transition to alarm at 2015-11-04T01:01:01Z, most recent: 1",
"reason_jp": "2015-11-04T10:01:01+09:00 時点でアラームが ALARM 状態に変化しました。 最新の値: 1",
"reason_data": {
"most_recent": "1",
"type": "threshold"
"disposition": "outside"
}
}
5. アラーム一覧¶
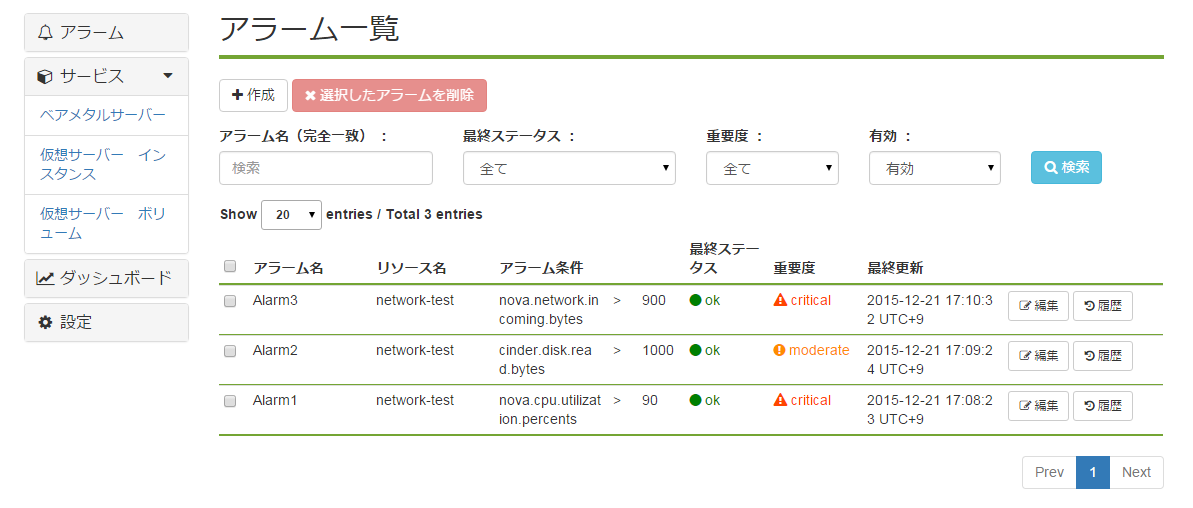
注釈
アラームの対象リソースが削除された場合、それに紐づくアラーム設定も自動で削除されます。
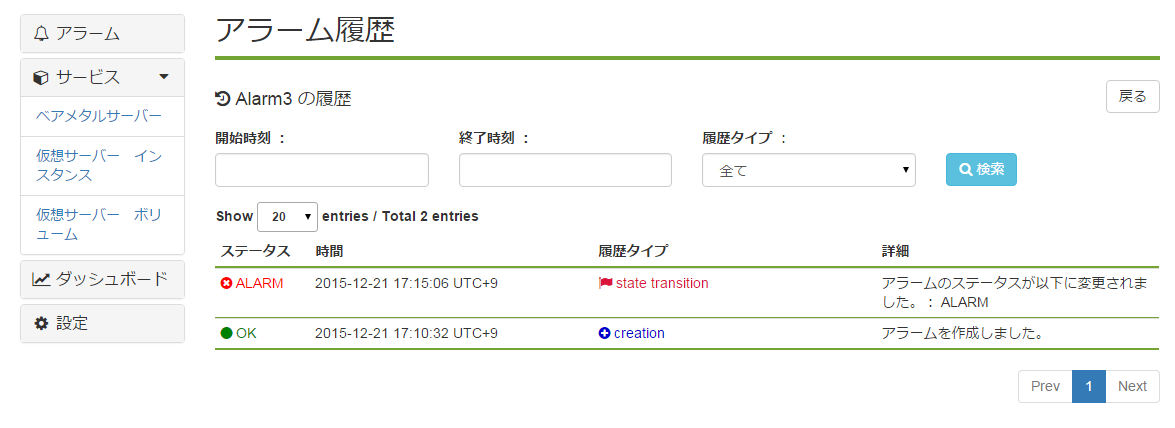
7. API¶
8. ダッシュボード ※アドバンスドプランのみ¶
9. データダウンロード ※アドバンスドプランのみ¶
プラン¶
プラン一覧¶
ベーシックプラン |
アドバンスドプラン |
|
|---|---|---|
料金 |
無料 |
有料 |
データの保存期間 |
32日間(当日含む) |
397日間(当日含む)
※デフォルトで設定されているメーター保存期間は32日間(当日含む)
※お客さま自身で、メーターごとに保存期間の延長設定が可能
※アドバンスドプランの月額固定料金内で、メーター保存期間を100個まで397日間(当日含む)に延長可能
※メーター保存期間を101個以上延長したい場合は、追加分に対して1メーターごとの月額固定料金が加算
※1テナントあたり、最大300個までメーター保存期間の延長設定が可能
|
設定可能なアラームの数 |
1テナントあたり10個まで |
1テナントあたり100個まで
※アドバンスドプランの月額固定料金内で、アラームを100個まで設定可能
※アラームを101個以上設定したい場合は、追加分に対して1アラームごとの月額固定料金が加算
※1テナントあたり、最大300個までアラームの追加設定が可能
|
カスタムメーター |
1テナントあたり1個まで |
1テナントあたり10個まで
※アドバンスドプランの月額固定料金内で、カスタムメーターを10個まで設定可能
※カスタムメーターを11個以上追加したい場合は、追加分に対して1メーターごとの月額固定料金が加算
※1テナントあたり、最大30個までカスタムメーターの追加設定が可能
|
その他の機能 |
ー |
ダッシュボード機能
データダウンロード機能(GUI)
|
注釈
申込方法¶
サービス提供の品質¶
サポート範囲¶
上記に記載した機能はサポート範囲となります。
運用¶
本サービスは、以下の運用品質にて提供します。
項目 |
内容 |
|---|---|
運用時間 |
24時間/365日 |
故障時の対応方針 |
NTTドコモビジネスにて復旧を速やかに実施します。 |
故障情報はポータルサイト上での掲載のみにより提供します。故障情報のメール通知は提供対象外です。